Caching¶
Enabling caching¶
There are numerous reasons why you may need to re-run calculations you’ve already done before. Since AiiDA stores the full provenance of each calculation, it can detect whether a calculation has been run before and reuse its outputs without wasting computational resources. This is what we mean by caching in AiiDA.
Caching is not enabled by default.
In order to enable caching for your AiiDA profile (here called aiida2), place the following cache_config.yml file in your .aiida configuration folder:
aiida2:
default: True
From this point onwards, when you launch a new calculation, AiiDA will compare its hash (depending both on the type of calculation and its inputs, see How are nodes hashed?) against other calculations already present in your database. If another calculation with the same hash is found, AiiDA will reuse its results without repeating the actual calculation.
In order to ensure that the provenance graph with and without caching is the same, AiiDA creates both a new calculation node and a copy of the output data nodes as shown in Fig. 2.
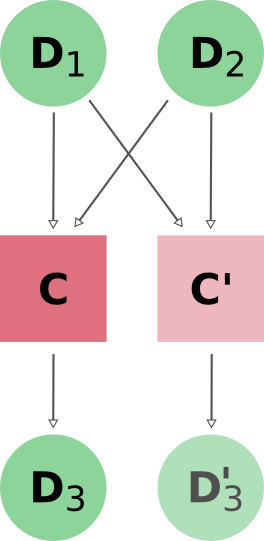
Fig. 2 When reusing the results of a calculation C for a new calculation C’, AiiDA simply makes a copy of the result nodes and links them up as usual.¶
Note
AiiDA uses the hashes of the input nodes D1 and D2 when searching the calculation cache. I.e. if the input of C’ were new nodes D1’ and D2’ with the same content (hash) as D1, D2, the cache would trigger as well.
Note
Caching is not implemented at the WorkChain/workfunction level (see Limitations for details).
How are nodes hashed?¶
Hashing is turned on by default, i.e. all nodes in AiiDA are hashed (see also Controlling hashing).
The hash of a Data node is computed from:
all attributes of the node, except the
_updatable_attributesand_hash_ignored_attributesthe
__version__of the package which defined the node classthe content of the repository folder of the node
the UUID of the computer, if the node is associated with one
The hash of a ProcessNode includes, on top of this, the hashes of all of its input Data nodes.
Once a node is stored in the database, its hash is stored in the _aiida_hash extra, and this extra is used to find matching nodes.
If a node of the same class with the same hash already exists in the database, this is considered a cache match.
Use the get_hash() method to check the hash of any node.
In order to figure out why a calculation is not being reused, the _get_objects_to_hash() method may be useful:
In [1]: calc=load_node(1234)
In [2]: calc.get_hash()
Out[2]: '62eca804967c9428bdbc11c692b7b27a59bde258d9971668e19ccf13a5685eb8'
In [3]: calc._get_objects_to_hash()
Out[3]:
['1.0.0b4',
{'resources': {'num_machines': 2, 'default_mpiprocs_per_machine': 28},
'parser_name': 'cp2k',
'linkname_retrieved': 'retrieved'},
<aiida.common.folders.Folder at 0x1171b9a20>,
'6850dc88-0949-482e-bba6-8b11205aec11',
{'code': 'f6bd65b9ca3a5f0cf7d299d9cfc3f403d32e361aa9bb8aaa5822472790eae432',
'parameters': '2c20fdc49672c3505cebabacfb9b1258e71e7baae5940a80d25837bee0032b59',
'structure': 'c0f1c1d1bbcfc7746dcf7d0d675904c62a5b1759d37db77b564948fa5a788769',
'parent_calc_folder': 'e375178ceeffcde086546d3ddbce513e0527b5fa99993091b2837201ad96569c'}]
Configuration¶
Class level¶
Besides an on/off switch per profile, the .aiida/cache_config.yml provides control over caching at the level of specific calculations using their corresponding entry point strings (see the output of verdi plugin list aiida.calculations):
profile-name:
default: False
enabled:
- aiida.calculations:quantumespresso.pw
disabled:
- aiida.calculations:templatereplacer
In this example, caching is disabled by default, but explicitly enabled for calculaions of the PwCalculation class, identified by the aiida.calculations:quantumespresso.pw entry point string.
It also shows how to disable caching for particular calculations (which has no effect here due to the profile-wide default).
For calculations which do not have an entry point, you need to specify the fully qualified Python name instead. For example, the seekpath_structure_analysis calcfunction defined in aiida_quantumespresso.workflows.functions.seekpath_structure_analysis is labelled as aiida_quantumespresso.workflows.functions.seekpath_structure_analysis.seekpath_structure_analysis. From an existing CalculationNode, you can get the identifier string through the process_type attribute.
The caching configuration also accepts * wildcards. For example, the following configuration enables caching for all calculation entry points defined by aiida-quantumespresso, and the seekpath_structure_analysis calcfunction. Note that the *.seekpath_structure_analysis entry needs to be quoted, because it starts with * which is a special character in YAML.
profile-name:
default: False
enabled:
- aiida.calculations:quantumespresso.*
- '*.seekpath_structure_analysis'
You can even override a wildcard with a more specific entry. The following configuration enables caching for all aiida.calculation entry points, except those of aiida-quantumespresso:
profile-name:
default: False
enabled:
- aiida.calculations:*
disabled:
- aiida.calculations:quantumespresso.*
Instance level¶
Even when caching is turned off for a given calculation type, you can enable it on a case-by-case basis by using the enable_caching context manager for testing purposes:
from aiida.engine import run
from aiida.manage.caching import enable_caching
with enable_caching(identifier='aiida.calculations:templatereplacer'):
run(...)
Warning
This affects only the current python interpreter and won’t change the behavior of the daemon workers.
This means that this technique is only useful when using run, and not with submit.
If you suspect a node is being reused in error (e.g. during development), you can also manually prevent a specific node from being reused:
Load one of the nodes you suspect to be a clone. Check that
get_cache_source()returns a UUID. If it returns None, the node was not cloned.Clear the hashes of all nodes that are considered identical to this node:
for n in node.get_all_same_nodes(): n.clear_hash()
Run your calculation again. The node in question should no longer be reused.
Limitations¶
Workflow nodes are not cached. In the current design this follows from the requirement that the provenance graph be independent of whether caching is enabled or not:
Calculation nodes: Calculation nodes can have data inputs and create new data nodes as outputs. In order to make it look as if a cloned calculation produced its own outputs, the output nodes are copied and linked as well.
Workflow nodes: Workflows differ from calculations in that they can return an input node or an output node created by a calculation. Since caching does not care about the identity of input nodes but only their content, it is not straightforward to figure out which node to return in a cached workflow.
For the moment, this limitation is acceptable since the runtime of AiiDA WorkChains is usually dominated by expensive calculations, which are covered by the current caching mechanism.
The caching mechanism for calculations should trigger only when the inputs and the calculation to be performed are exactly the same. While AiiDA’s hashes include the version of the python package containing the calculation/data classes, it cannot detect cases where the underlying python code was changed without increasing the version number. Another edge case would be if the parser lives in a different python package than the calculation (calculation nodes store the name of the parser used but not the version of the package containing the parser).
Finally, while caching saves unnecessary computations, it does not save disk space: The output nodes of the cached calculation are full copies of the original outputs. The plan is to add data deduplication as a global feature at the repository and database level (independent of caching).