Implementation¶
Graph nodes¶
The nodes of the AiiDA provenance graph can be grouped into two main types: process nodes (ProcessNode), that represent the execution of calculations or workflows, and data nodes (Data), that represent pieces of data.
In particular, process nodes are divided into two sub categories:
calculation nodes (
CalculationNode): Represent code execution that creates new data. These are further subdivided in two subclasses:
CalcJobNode: Represents the execution of a calculation external to AiiDA, typically via a job batch scheduler (see the concept of calculation jobs).
CalcFunctionNode: Represents the execution of a python function (see the concept of calculation functions).workflow nodes (
WorkflowNode): Represent python code that orchestrates the execution of other workflows and calculations, that optionally return the data created by the processes they called. These are further subdivided in two subclasses:
WorkChainNode: Represents the execution of a python class instance with built-in checkpoints, such that the process may be paused/stopped/resumed (see the concept of work chains).
WorkFunctionNode: Represents the execution of a python function calling other processes (see the concept of work functions).
The class hierarchy of the process nodes is shown in the figure below.
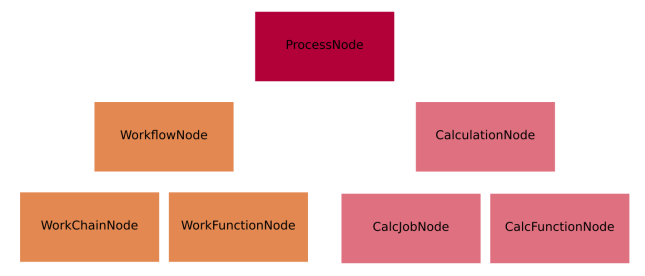
Fig. 23 The hierarchy of the ORM classes for the process nodes. Only instances of the lowest level of classes will actually enter into the provenance graph. The two upper levels have a mostly taxonomical purpose as they allow us to refer to multiple classes at once when reasoning about the graph as well as a place to define common functionality (see section on processes).¶
For what concerns data nodes, the base class (Data) is subclassed to provide functionalities specific to the data type and python methods to operate on it.
Often, the name of the subclass contains the word “Data” appended to it, but this is not a requirement. A few examples:
Dict: represents a dictionary of key-value pairs - these are parameters of a general nature that do not need to belong to more specific data sub-classesStructureData: represents crystal structure data (containing chemical symbols, atomic positions of the atoms, periodic cell for periodic structures, …)ArrayData: represents generic numerical arrays of data (python numpy arrays)KpointsData: represents a numerical array of k-points data, is a sub-class ofArrayData
For more detailed information see AiiDA data types.
In the next section we introduce the links between nodes, creating the AiiDA graph, and then we show some examples to clarify what we introduced up to now.
Graph links¶
Process nodes are connected to their input and output data nodes through directed links. Calculation processes can create data, while workflow processes can call calculations and return their outputs. Consider the following graph example, where we represent data nodes with circles, calculation nodes with squares and workflow nodes with diamond shapes.
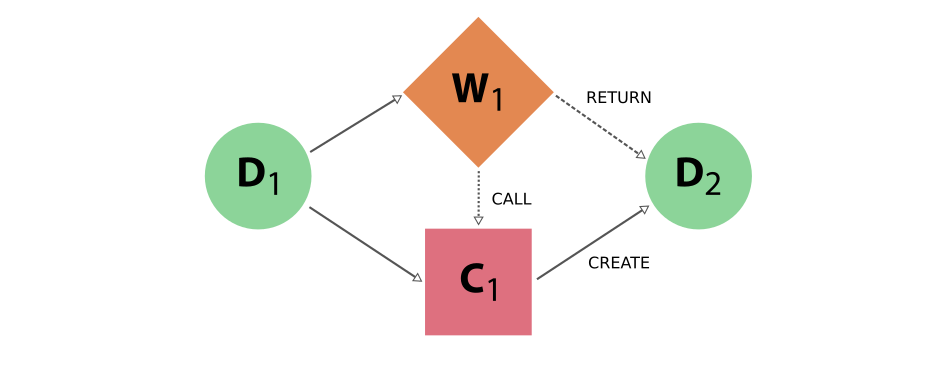
Fig. 24 Simple provenance graph for a workflow (W1) calling a calculation (C1). The workflow takes a single data node (D1) as input, and passes it to the calculation when calling it. The calculation creates a new data node (D2) that is also returned by the workflow node.¶
Notice that the different style and names for the two links coming into D2 is intentional, because it was the calculation that created the new data, whereas the workflow merely returned it. This subtle distinction has big consequences. By allowing workflow processes to return data, it can also return data that was among its inputs.
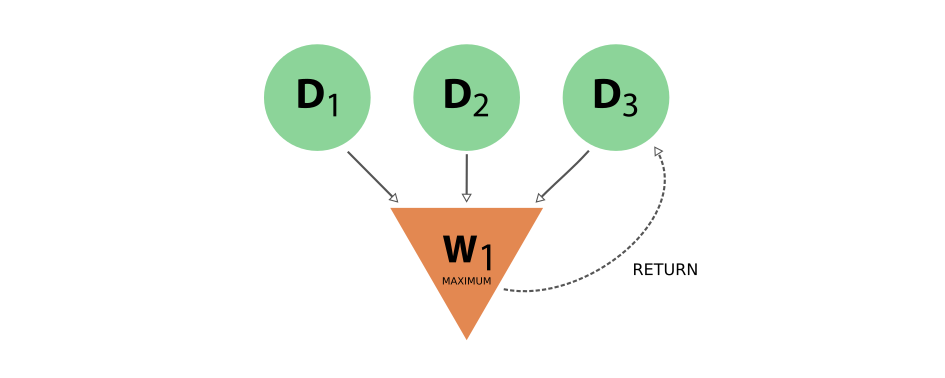
Fig. 25 Provenance graph example of a workflow node that receives three data nodes as input and returns one of those inputs. The input link from D3 to W1 and the return link from W1 to D3 introduce a cycle in the graph.¶
A scenario like this, represented in Fig. 25, would create a cycle in the provenance graph, breaking the “acyclicity” of the DAG. To restore the directed acyclic graph, we separate the entire provenance graph into two planes as described above: the data provenance and the logical provenance. With this division, the acyclicity of the graph is restored in the data provenance plane.
An additional benefit of thinking of the provenance graph in these two planes, is that it allows you to inspect it with different layers of granularity. Imagine a high level workflow that calls a large number of calculations and sub-workflows, that each may also call more sub-processes, to finally produce and return one or more data nodes as its result.
Graph examples¶
With these basic definitions of AiiDA’s provenance graph in place, let’s take a look at some examples. Consider the sequence of computations that adds two numbers x and y, and then multiplies the result with a third number z. This sequence as represented in the provenance graph would look something like what is shown in Fig. 26.
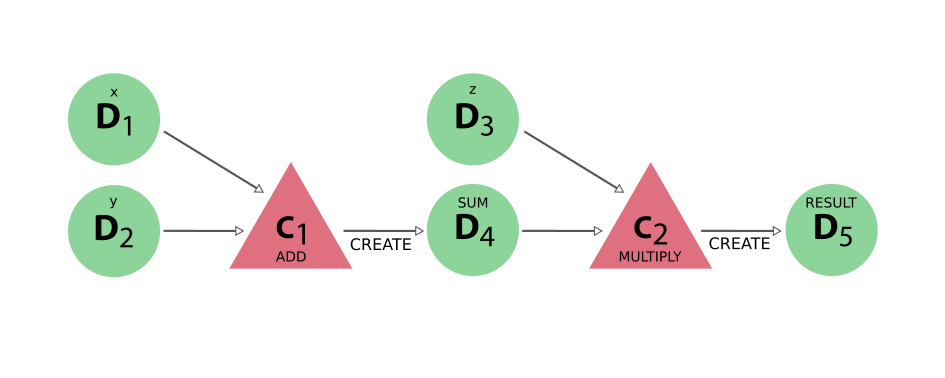
Fig. 26 The DAG for computing (x+y)*z. We have two simple calculations: C1 represents the addition and C2 the multiplication. The two data nodes D1 and D2 are the inputs of C1, which creates the data node D4. Together with D3, D4 then forms the input of C2, which multiplies their values that creates the product, represented by D5.¶
In this simple example, there was no external process that controlled the exact sequence of these operations. This may be imagined however, by adding a workflow that calls the two calculations in succession, as shown in Fig. 27.
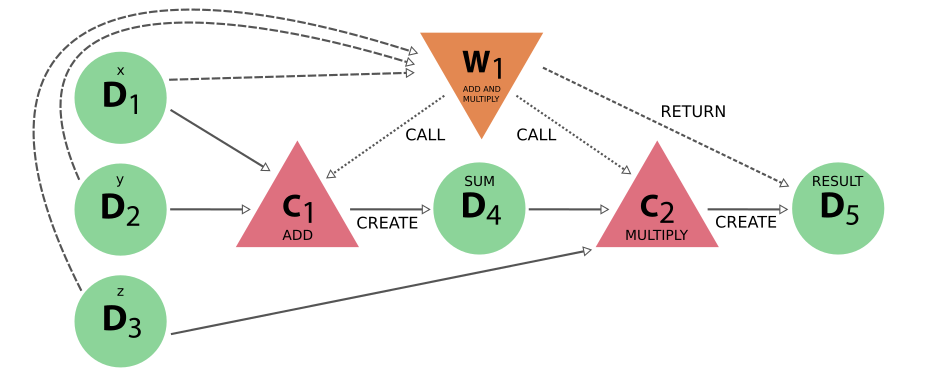
Fig. 27 The same calculation (x+y)*z is performed using a workflow. Here the data nodes D1, D2, and D3 are the inputs of the workflow W1, which calls calculation C1 with inputs D1 and D2. It then calls calculation C2, using as inputs D3 and D4 (which was created by C2). Calculation C2 creates data node D5, which is finally returned by workflow W1.¶
Notice that if we were to omit the workflow nodes and all its links from the provenance graph in Fig. 27, one would end up with the exact same graph as shown in Fig. 26 (the data provenance graph).