存储库#
AiiDA 中的文件存储库,通常简称为存储库,是持久化所有二进制数据的数据存储库,这些数据属于 provenance 图中的 Node。本章将描述文件存储库的设计和实现,主要借鉴 AEP 007: Abstract and improve the file repository 和 AEP 006: Efficient object store for the AiiDA repository 的内容。
目前的架构在很大程度上受到 AiiDA 最早版本中文件库原始设计的经验教训的影响,原始设计很难扩展到大量文件。因此,在本章的末尾有一个关于原始设计及其局限性的描述。这对理解当前解决方案的设计很有启发。
设计#
在设计文件存储库实施过程中,考虑了以下要求:
可扩展性:存储库应能存储数百万个文件,同时允许高效备份。
异构性:存储库应能有效地处理大小不一的数据,对象的大小从几个字节到多个千兆字节不等。
简便性:解决方案的运行不需要运行中的服务器。
并发性:版本库应支持多个并发读写进程。
效率:存储库应自动重复文件内容,以减少所需存储空间总量。
这些仅仅是对持久保存文件内容的数据存储或*后端*文件存储库的要求。用户存储文件时使用的前端界面则完全不同。用户习惯从文件层次结构的角度来考虑文件存储,就像在普通文件系统中一样,文件存储在(嵌套)目录中。此外,在 AiiDA 的背景下,node 应该有自己的文件子集,有自己的层次结构,例如 图 27。因此,前端界面需要允许用户按 node 层级存储和处理文件,即使只是虚拟的。有了这种保证,后端实现就可以自由地以任何可以想象的方式存储文件,以满足上述要求。
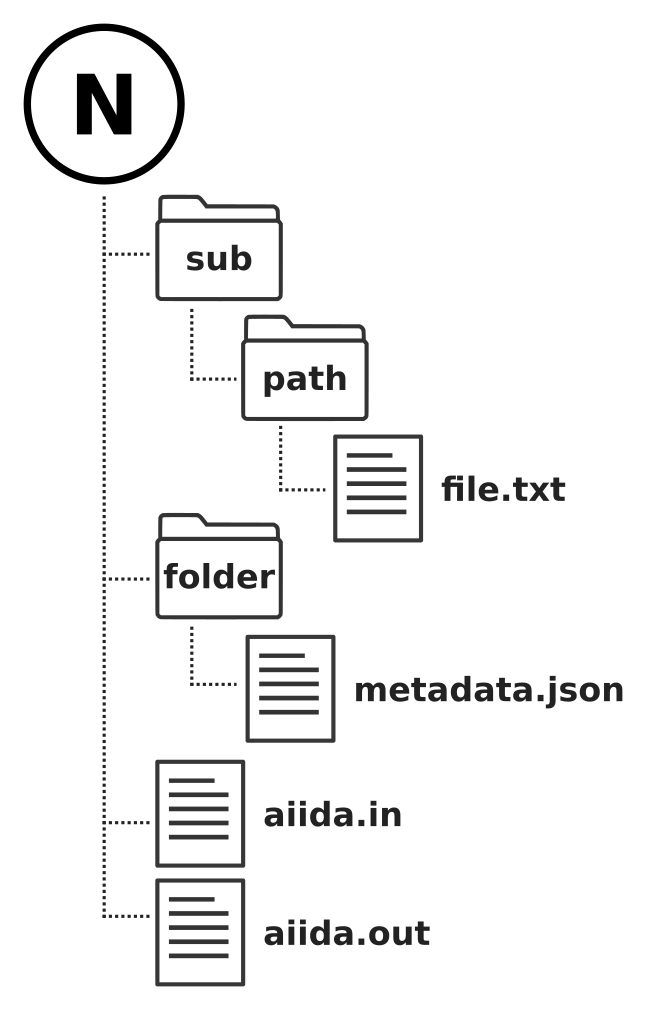
图 27 Schematic 表示 provenance graph 中 node 可能的虚拟文件层次结构。从用户的角度来看,每个 node 可以包含任意数量的文件和目录,并具有一定的文件层次结构。不过,这种层次结构完全是虚拟的,因为在包含文件内容的数据存储区中,并不一定按字面意思来维护层次结构。#
为了同时满足前端界面和实际数据存储的要求,AiiDA 的文件存储解决方案分为两个部分:前端*和*后端,前者不依赖于任何特定的存储技术,后者实现了与存储的接口。
文件存储库前端#
要了解文件存储库前端如何集成 ORM 和文件存储库后台,请看下面的类图:
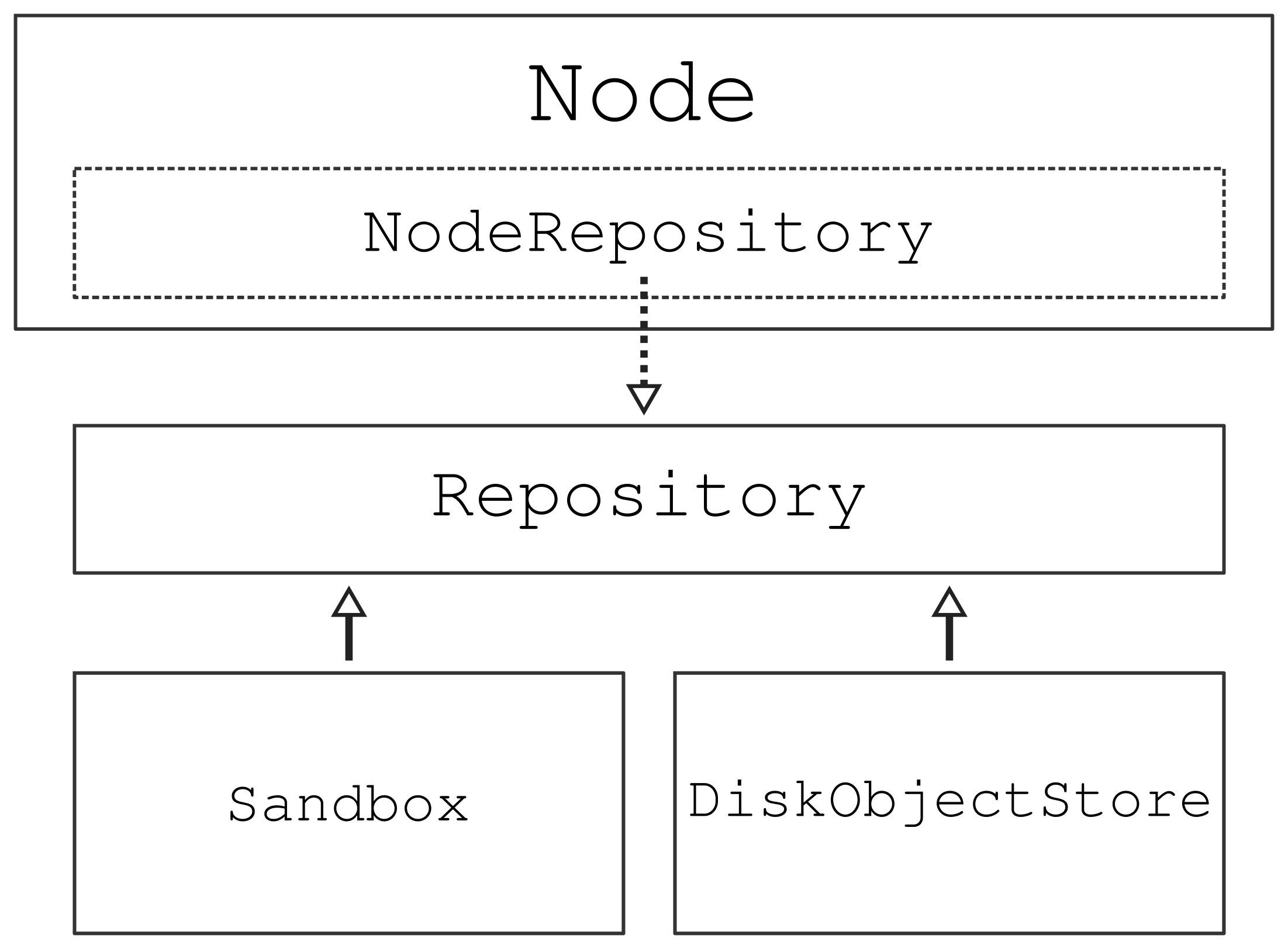
图 28 文件存储库后端通过 Repository 类进行连接。它维护可用文件存储库后端实现(无论是沙盒还是磁盘对象存储变体)之一实例的引用,以存储文件对象并检索所存储对象的内容。在内部,它保留了一个虚拟文件层次结构,允许客户端通过文件层次结构中的路径来寻址文件,而不是使用后端创建的唯一密钥标识符。最后,Node 类是用户与整个应用程序接口的主要交互点,它混合了 NodeRepository 类。后者保留了一个 Repository 类的实例,在对 node 的可变性进行检查后,所有存储库操作都将转发给该类。#
与后端界面不同,前端 Repository 确实 理解文件层次结构的概念,并将其完全保存在内存中。这样,客户端就可以与该界面进行交互,就好像文件是按照指定的层次结构存储的一样,并通过相对文件路径(而不是后端生成的唯一字符串标识符)进行寻址。但 import 要注意的是,这个虚拟层次结构并不是根据文件存储库后台的实际内容来初始化的。事实上,它 不能 这样做,因为后端没有文件层次结构的概念,因此无法在构建 Repository 时向其提供层次结构。这意味着,Repository 只能公开文件存储库后端所含文件的 子集 。
要持久保存为任何特定 node 存储的文件的虚拟层次结构,可将其存储在数据库中。node 数据库模型有一个名为 repository_metadata 的 JSONB 列,其中包含序列化形式的虚拟文件层次结构。该序列化形式由 serialize() 方法生成,from_serialized() 类方法可用于重构具有 pre-existing 文件层次结构的存储库实例。请注意,在从序列化文件层次结构构建时,Repository 不会实际验证层次结构中包含的文件对象是否*实际*包含在后端中。
The final integration of the Repository class with the ORM is through the NodeRepository class, which is mixed into the Node class.
This layer serves a couple of functions:
它实现了 nodes 的可变性规则
它是字符串流和字节流之间的转换层。
第一个方法是必要的,因为 node 被存储后,其内容被认为是不可变的,这包括其文件存储库的内容。Sealable 混合脚本重写了更改存储库内容的 Repository 方法,以确保 node 进程只要不被密封,就可以更改其内容。
The second raison-d’être of the NodeRepository is to allow clients to work with string streams instead of byte streams.
As explained in the section on the file repository backend, it only works with byte streams.
However, users of the frontend API are often more used to working with strings and files with a given encoding.
The NodeRepository overrides the put-methods and accepts string streams, and enables returning file handles to existing file objects that automatically decode the byte content.
The only additional requirement for operating with strings instead of bytes is that the client specifies the encoding.
Since the file repository backend does not store any sort of metadata, it is impossible to deduce the file encoding and automatically decode it.
Likewise, using the default file encoding of the system may yield the wrong result since the file could have been imported and actually have been originally written on another system with a different encoding.
Encoding and decoding of file objects is therefore the responsibility of the frontend user.
文件存储库后台#
在明确的职责分工中,后端只负责存储文件内容,并在请求时尽可能高效地返回文件,无论是单个文件还是批量文件都是如此。为简单起见,存储库后台只处理原始字节流,不维护任何类型的文件层次结构。AbstractRepositoryBackend 抽象类定义了任何后端文件存储库应实现的接口。
class AbstractRepositoryBackend(metaclass=abc.ABCMeta):
"""Class that defines the abstract interface for an object repository.
The repository backend only deals with raw bytes, both when creating new objects as well as when returning a stream
or the content of an existing object. The encoding and decoding of the byte content should be done by the client
upstream. The file repository backend is also not expected to keep any kind of file hierarchy but must be assumed
to be a simple flat data store. When files are created in the file object repository, the implementation will return
a string-based key with which the content of the stored object can be addressed. This key is guaranteed to be unique
and persistent. Persisting the key or mapping it onto a virtual file hierarchy is again up to the client upstream.
"""
@property
@abc.abstractmethod
def uuid(self) -> Optional[str]:
"""Return the unique identifier of the repository."""
@property
@abc.abstractmethod
def key_format(self) -> Optional[str]:
"""Return the format for the keys of the repository.
Important for when migrating between backends (e.g. archive -> main), as if they are not equal then it is
necessary to re-compute all the `Node.base.repository.metadata` before importing (otherwise they will not match
with the repository).
"""
@abc.abstractmethod
def initialise(self, **kwargs) -> None:
"""Initialise the repository if it hasn't already been initialised.
:param kwargs: parameters for the initialisation.
"""
@property
@abc.abstractmethod
def is_initialised(self) -> bool:
"""Return whether the repository has been initialised."""
@abc.abstractmethod
def erase(self) -> None:
"""Delete the repository itself and all its contents.
.. note:: This should not merely delete the contents of the repository but any resources it created. For
example, if the repository is essentially a folder on disk, the folder itself should also be deleted, not
just its contents.
"""
@staticmethod
def is_readable_byte_stream(handle) -> bool:
return hasattr(handle, 'read') and hasattr(handle, 'mode') and 'b' in handle.mode
def put_object_from_filelike(self, handle: BinaryIO) -> str:
"""Store the byte contents of a file in the repository.
:param handle: filelike object with the byte content to be stored.
:return: the generated fully qualified identifier for the object within the repository.
:raises TypeError: if the handle is not a byte stream.
"""
if (
not isinstance(handle, io.BufferedIOBase) # type: ignore[redundant-expr,unreachable]
and not self.is_readable_byte_stream(handle)
):
raise TypeError(f'handle does not seem to be a byte stream: {type(handle)}.')
return self._put_object_from_filelike(handle)
@abc.abstractmethod
def _put_object_from_filelike(self, handle: BinaryIO) -> str:
pass
def put_object_from_file(self, filepath: Union[str, pathlib.Path]) -> str:
"""Store a new object with contents of the file located at `filepath` on this file system.
:param filepath: absolute path of file whose contents to copy to the repository.
:return: the generated fully qualified identifier for the object within the repository.
:raises TypeError: if the handle is not a byte stream.
"""
with open(filepath, mode='rb') as handle:
return self.put_object_from_filelike(handle)
@abc.abstractmethod
def has_objects(self, keys: List[str]) -> List[bool]:
"""Return whether the repository has an object with the given key.
:param keys:
list of fully qualified identifiers for objects within the repository.
:return:
list of logicals, in the same order as the keys provided, with value True if the respective
object exists and False otherwise.
"""
def has_object(self, key: str) -> bool:
"""Return whether the repository has an object with the given key.
:param key: fully qualified identifier for the object within the repository.
:return: True if the object exists, False otherwise.
"""
return self.has_objects([key])[0]
@abc.abstractmethod
def list_objects(self) -> Iterable[str]:
"""Return iterable that yields all available objects by key.
:return: An iterable for all the available object keys.
"""
@abc.abstractmethod
def get_info(self, detailed: bool = False, **kwargs) -> dict:
"""Returns relevant information about the content of the repository.
:param detailed:
flag to enable extra information (detailed=False by default, only returns basic information).
:return: a dictionary with the information.
"""
@abc.abstractmethod
def maintain(self, dry_run: bool = False, live: bool = True, **kwargs) -> None:
"""Performs maintenance operations.
:param dry_run:
flag to only print the actions that would be taken without actually executing them.
:param live:
flag to indicate to the backend whether AiiDA is live or not (i.e. if the profile of the
backend is currently being used/accessed). The backend is expected then to only allow (and
thus set by default) the operations that are safe to perform in this state.
"""
@contextlib.contextmanager
def open(self, key: str) -> Iterator[BinaryIO]: # type: ignore[return]
"""Open a file handle to an object stored under the given key.
.. note:: this should only be used to open a handle to read an existing file. To write a new file use the method
``put_object_from_filelike`` instead.
:param key: fully qualified identifier for the object within the repository.
:return: yield a byte stream object.
:raise FileNotFoundError: if the file does not exist.
:raise OSError: if the file could not be opened.
"""
if not self.has_object(key):
raise FileNotFoundError(f'object with key `{key}` does not exist.')
def get_object_content(self, key: str) -> bytes:
"""Return the content of a object identified by key.
:param key: fully qualified identifier for the object within the repository.
:raise FileNotFoundError: if the file does not exist.
:raise OSError: if the file could not be opened.
"""
with self.open(key) as handle:
return handle.read()
@abc.abstractmethod
def iter_object_streams(self, keys: List[str]) -> Iterator[Tuple[str, BinaryIO]]:
"""Return an iterator over the (read-only) byte streams of objects identified by key.
.. note:: handles should only be read within the context of this iterator.
:param keys: fully qualified identifiers for the objects within the repository.
:return: an iterator over the object byte streams.
:raise FileNotFoundError: if the file does not exist.
:raise OSError: if a file could not be opened.
"""
def get_object_hash(self, key: str) -> str:
"""Return the SHA-256 hash of an object stored under the given key.
.. important::
A SHA-256 hash should always be returned,
to ensure consistency across different repository implementations.
:param key: fully qualified identifier for the object within the repository.
:raise FileNotFoundError: if the file does not exist.
:raise OSError: if the file could not be opened.
"""
with self.open(key) as handle:
return chunked_file_hash(handle, hashlib.sha256)
@abc.abstractmethod
def delete_objects(self, keys: List[str]) -> None:
"""Delete the objects from the repository.
:param keys: list of fully qualified identifiers for the objects within the repository.
:raise FileNotFoundError: if any of the files does not exist.
:raise OSError: if any of the files could not be deleted.
"""
keys_exist = self.has_objects(keys)
if not all(keys_exist):
error_message = 'some of the keys provided do not correspond to any object in the repository:\n'
for indx, key_exists in enumerate(keys_exist):
if not key_exists:
error_message += f' > object with key `{keys[indx]}` does not exist.\n'
raise FileNotFoundError(error_message)
def delete_object(self, key: str) -> None:
"""Delete the object from the repository.
:param key: fully qualified identifier for the object within the repository.
:raise FileNotFoundError: if the file does not exist.
:raise OSError: if the file could not be deleted.
"""
return self.delete_objects([key])
The put_object_from_filelike() is the main method that, given a stream or filelike-object of bytes, will write it as an object to the repository and return a key.
The put_object_from_file() is a convenience method that allows to store a file object directly from a file on the local file system, and simply calls through to put_object_from_filelike().
The key returned by the put-methods, which could be any type of string, should uniquely identify the stored object.
Using the key, open() and get_object_content() can be used to obtain a handle to the object or its entire content read into memory, respectively.
Finally, the has_object() and delete_object() can be used to determine whether the repository contains an object with a certain key, or delete it, respectively.
disk object store (DiskObjectStoreRepositoryBackend) 和 scratch sandbox (SandboxRepositoryBackend) 实现了抽象存储库后台接口。后一种实现方式只是使用本地文件系统上的临时 scratch 文件夹来实现接口,以存储文件内容。文件对象以扁平方式存储,其中作为唯一密钥的文件名基于随机生成的 UUID,如 图 29 所示。

图 29 文件存储库后端 SandboxRepositoryBackend 实现创建的文件结构。文件以完全扁平的结构存储,文件名由随机生成的 UUID 决定。这是在本地文件系统中写入和读取文件的最有效方法。由于这些沙盒存储库的生命周期很短,包含的对象也相对较少,因此平面文件存储的典型缺点并不适用。#
该沙箱实现的简单扁平结构不应成为限制因素,因为该后端只能用于短期临时文件存储库。用例是为未存储的 node 提供文件存储库。在交互式 shell 会话中创建的新 node 实例通常在存储前就会被丢弃,因此 important 不仅要尽可能高效地创建新文件,还要在删除 node 后高效地删除文件。磁盘对象存储区没有针对高效的临时对象删除进行优化,而是以软删除的方式实现对象删除,实际删除应在维护操作期间进行,如打包松散对象。这就是为什么一个新的 node 实例在实例化后会获得一个类:~aiida.repository.backend.sandbox.SandboxRepositoryBackend 的存储库实例。只有当 node 被存储时,文件才会被复制到永久的后端文件存储库(如 DiskObjectStoreRepositoryBackend)。
磁盘对象存储 (disk object store)#
磁盘对象存储空间是从零开始设计的,目的是满足上一节所述文件存储库的技术要求。概念很简单:文件存储库由 容器 表示,容器是本地文件系统中的一个目录,包含所有文件内容。当文件写入容器时,首先会写入 scratch 目录。一旦这一操作成功完成,文件就会被移动到 loose 目录中。之所以称为 loose ,是因为该目录中的每个文件都是作为一个单独的或 loose 对象存储的。对象的名称是根据其内容计算出来的哈希值,目前使用的是 sha256 algorithm。如 原始设计 所述, loose 目录会根据对象哈希值的前两个字符进行一级分片,以便提高对象查找的性能。磁盘对象存储 container 的文件夹结构 schematic 概览见 图 30。

图 30 Schematic 表示 disk object store 软件包 容器 中的文件层次结构。将文件写入容器时,它们首先被写入 scratch 沙盒文件夹,然后被原子移动到 loose 目录。在维护操作过程中, loose 文件可与存储在 packed 目录中的打包文件连接。#
在资源库中创建新文件时,先将文件写入从头沙盒文件夹,然后再原子移动到 松散 对象目录,这种方法直接满足了 并发 的要求。通过依赖操作系统的 原子 文件移动操作,所有 松散 对象都能在本地文件系统的原子性保证范围内得到保护,避免数据损坏。使用文件内容的哈希校验和作为文件名,可自动满足 效率 要求。假设所使用的哈希算法没有碰撞,两个具有相同哈希值的对象就能保证具有相同的内容,因此可以作为单一对象进行存储。虽然在存储文件之前计算文件的哈希值会产生不可忽略的开销,但所选的哈希算法速度足够快,而且由于自动和隐式重复数据删除功能,所需的存储空间也大大减少,因此这一开销是值得的。
虽然 scratch 和 loose 目录的方法满足了 并发 和 效率 的标准,但该解决方案并不具备 可扩展性 。正如 original design,由于每个对象都作为单独文件存储在磁盘上,因此该解决方案无法扩展到数百万个 node 文件的文件库。如上文所述,这使得备份文件库变得不切实际,因为仅仅构建文件列表就是一项昂贵的操作。为了解决这个问题,磁盘对象存储库采用了打包的概念。在此维护操作中,存储在 loose 目录中的所有松散对象的内容都会被串联成单个文件,存储在 packed 文件夹中。打包文件有一个可配置的最大大小,一旦达到该大小,就会创建下一个打包文件,文件名由连续的整数命名。
sqlite 数据库用于跟踪每个对象存储在哪个打包文件中、开始的字节偏移量以及总字节长度。一旦单个对象被打包到数量较少的文件中,这样的索引文件就是必要的。为了满足 简单 的要求,我们选择了 sqlite 数据库,因为它无服务器且高效。松散的对象是以随机顺序串联起来的,也就是说,磁盘对象存储空间不会像其他一些键值存储解决方案那样,根据对象内容的大小对其进行任何排序,例如将其与文件系统中的块对齐。任何大小的文件都一视同仁,因此不会对存储小文件或大文件进行优化。这样做是有意为之,因为我们希望磁盘对象存储能够存储大小各异的文件,因此无法针对特定范围的文件大小进行优化。
目前,打包操作被视为一种维护操作,因此与写入新的 松散 对象不同,不能由多个进程同时进行。尽管目前存在这种限制,打包机制还是满足了最终的 可扩展性 要求。通过减少文件总数和打包策略,打包文件可以非常高效地复制到备份副本中。由于新对象会被连接到现有打包文件的末尾,而现有打包文件在达到最大大小后原则上不会再被触及(除非打包文件被强制重新打包),因此备份工具(如 rsync)可以将内容传输减少到最低限度。
node 的使用寿命#
在介绍了所有组件之后,下面我们将介绍在 node 的整个生命周期中如何使用这些组件。当构建一个新的 node 实例时,它还没有 Repository 实例。相反,在文件存储库上执行操作时,会立即创建这样一个实例。这一点对性能至关重要,因为 node 实例在初始化时往往不需要访问其存储库内容,而构建存储库接口实例会产生不可忽略的开销。如果 node 未存储,Repository 将使用 SandboxRepositoryBackend 实现的实例来构建。这样做的好处是,如果 node 对象在被存储之前就退出了作用域,那么在存储库中创建的内容将自动从本地文件系统中清除。
当存储 node 时,Repository 实例会被一个新实例取代,这次后端设置为 DiskObjectStoreRepositoryBackend,初始化后指向当前配置文件的 容器 。沙盒存储库的内容通过 Repository 接口复制到磁盘对象存储库,最后对其内容进行序列化。序列化后的文件层次结构将存储在 node 本身的 repository_metadata 列中。这样,一旦 node 从数据库中重新加载,就可以通过调用 from_serialized() 类方法并传递存储的 repository_metadata 来正确重建 Repository 实例。
原始设计#
AiiDA 最初的文件存储库是作为本地文件系统上的一个简单目录实现的。属于node的文件会被原封不动地写入存储库目录下的一个子目录,不会进行任何压缩或打包。该目录的名称等于 node 的 UUID,确保每个子目录都是唯一的,不同 node 的文件即使名称相同,也不会相互覆盖。
考虑到包含许多 node 的数据库会导致许多子目录,从而减慢查找特定 node 目录的操作速度,存储库采用了 sharded。在文件系统中,这意味着 node 目录不是以平面结构存储在文件存储库中,而是存储在(嵌套的)子目录中。哪个子目录再次由 UUID 决定:第一个和第二个子目录分别由第一个和第二个两个字符给出。UUID 的其余字符构成最终子目录的名称。例如,UUID 为 4802585e-18da-42e1-b063-7504585ea9af,子目录的相对路径就是 48/02/585e-18da-42e1-b063-7504585ea9af。在这种结构下,文件存储库最多包含 256 个目录,从 00 到 ff,每个目录都是一样的。不过,从第三层开始,文件层次结构将再次扁平化。文件层次结构的 schematic概览见 图 31。
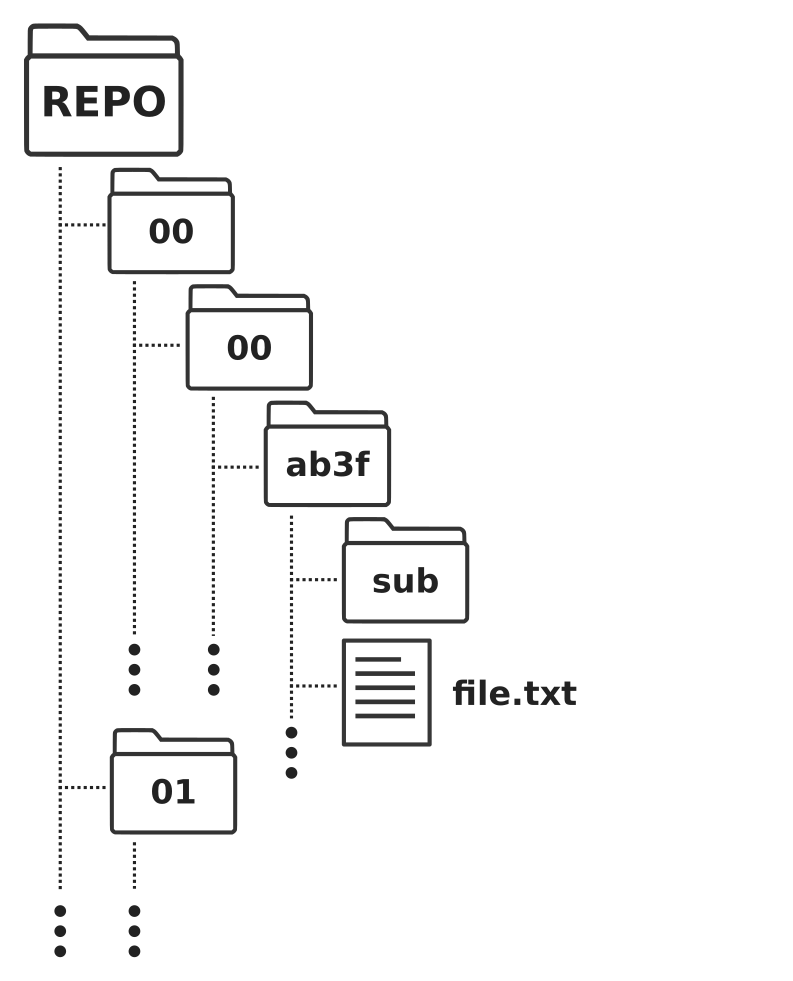
图 31 Schematic 表示文件存储库的原始结构。每个 node 的文件都存储在该 node 独有的目录中,其路径由 node 的 UUID 决定。该目录被分片两次,使用 UUID 开头的两个连续字符创建两级子目录。这样做是为了限制任何一级目录的数量,以便更有效地查找指定 node 的目录。#
局限性#
虽然设计简单、功能强大,但文件存储库的原始架构存在各种限制,其中许多限制在包含大量文件的大型项目中开始发挥重要作用。原始设计的主要限制是所有文件都按原样存储,最终导致大量文件存储在大量子目录中。在文件系统中,每个文件或目录都需要一个 inode ,这是文件系统能够将文件路径映射到磁盘实际位置的标签。文件系统中可用的 inode 数量是有限的,某些 AiiDA 项目已经达到了这些限制,使得更多的文件无法写入磁盘,即使可能还有大量的原始存储空间。
此外,用原始设计备份文件库实际上是不可能的。由于文件数量庞大,即使是确定原始文件库和备份文件库之间的差异,例如使用 rsync,也需要花费数天时间。这还只是计算差异,更不用说执行实际备份所需的时间了。
然而,有问题的不仅仅是文件的数量,即使是典型的存储库所包含的目录数量,也会大大降低备份操作的速度。由于数据库并不记录文件存储库中为任何给定的 node 存储了哪些文件和目录,因此最初的设计总是在文件存储库中为任何 node 创建一个子目录,即使其中不包含任何文件。否则,就不可能知道 node 是否 真的 不包含任何文件,或者文件库中的目录是否不小心搞错了。不过,这种方法确实导致了大量的空目录,因为许多 node 通常根本不包含任何文件,例如基本类型数据 node。