概念#
计算是 创建 新数据的过程(详见 process section)。目前,有两种实现计算过程的方法:
第一种是两种方法中最简单的一种,基本上是将一个 python 函数神奇地转换成一个进程。这非常适合计算密集度不高的计算,而且可以在 python 函数中轻松实现。对于计算量较大的计算(通常由可选择在远程计算集群上运行的外部代码执行),计算作业是更好的选择。
在下面的章节中,我们将解释这两个概念,但不会过多地介绍如何实现或运行它们。如需更详细的介绍,请参阅 calculation functions 和 calculation jobs 的相关高级章节。
计算功能#
请看下面的计算任务:
给定三个整数,将前两个相加,然后将和乘以第三个。
在简单的 python 代码中,解决方法如下:
def add(x, y):
return x + y
def multiply(x, y):
return x * y
result = multiply(add(1, 2), 3)
这个简单的代码片段可以实现获得预期结果的目标,但是,provenance 却丢失了。函数的输出和输入之间没有连接。解决这一问题的方法是使用 calcfunction()。AiiDA 中的 calcfunction 是一个 function decorator,它在计算过程中转换了一个普通的 python 函数,执行时自动将输出的 provenance 保存在 provenance graph 中。用 calcfunction 装饰器更新前面的代码段,结果如下
from aiida.engine import calcfunction
@calcfunction
def add(x, y):
return x + y
@calcfunction
def multiply(x, y):
return x * y
result = multiply(add(1, 2), 3)
为了装饰这两个函数,我们唯一要做的就是在函数定义前添加 @calcfunction 行。添加装饰器告诉 AiiDA,当函数执行时,该函数的 provenance 应该存储在 provenance graph 中。这意味着将计算 node 的输入和输出连接起来,代表执行的函数。要实现这一点,必须进行的最后一项修改是使输入和输出可存储。在前面的代码段中,输入是普通的 python 整数类型,无法自动以 node 的形式存储在 provenance graph 中。要解决这个问题,只需将它们封装在 Int node 子类中,这样就可以将它们存储在数据库中:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add(x, y):
return x + y
@calcfunction
def multiply(x, y):
return x * y
result = multiply(add(Int(1), Int(2)), Int(3))
与前一个代码段的唯一区别是,所有输入都已封装在 Int 类中。函数返回的结果现在也是一个 Int node,可以存储在 provenance graph 中,并包含计算结果。
Added in version 2.1: Function argument casting
如果函数参数是一个 Python 基本类型 (即类型为 bool, dict, Enum, float, int, list 或 str 的值),它可以直接传递给函数,而不需要先用相应的 AiiDA 数据类型包装它。也就是说,你也可以以下列方式运行上面的示例:
result = multiply(add(1, 2), 3)
而 AiiDA 会识别出参数的类型是 int`,并自动用 ``Int node 包起来。
备注
由于函数 add 和 multiply 中的 x 和 y 已经是 Int 实例,和也将是 1。这是真的,因为所有算术运算符都可以在 AiiDA 基类(Int、Float 等)上使用,就像在等价的 python 类型上一样。但 import 需要注意的是,只能存储 Node 实例或其子类。有关如何从进程函数返回结果的详细信息,请参阅 advanced section。
通过这些微不足道的改动,运行该函数所产生的完整结果 provenance 得到了保留,如下所示:
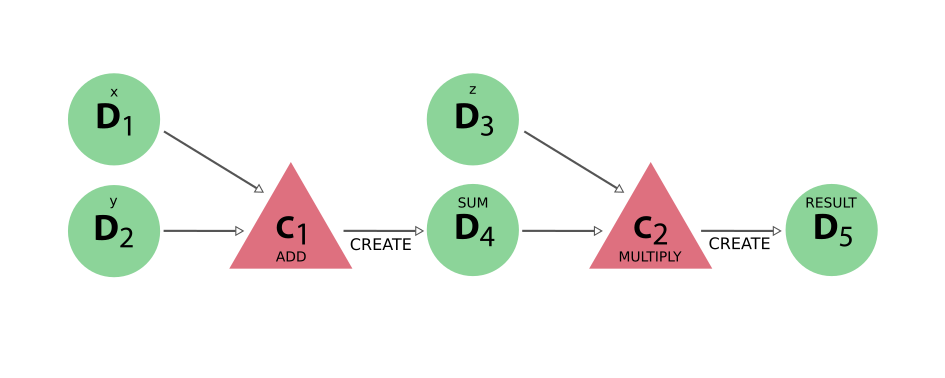
图 11 计算函数示例生成的 provenance#
上面的示例已经说明了如何运行 calcfunction:只需调用它即可。返回值就是函数定义返回的结果。不过,有时我们也希望有一个计算 node 的引用,它表示函数在 provenance graph 中的执行情况。下面的示例显示了两个额外的启动函数,它们将返回一个元组,除了结果外,还将返回与流程相关的 pk 或 node
from aiida.engine import calcfunction, run, run_get_node, run_get_pk
from aiida.orm import Int
@calcfunction
def add(x, y):
return x + y
x = Int(1)
y = Int(2)
result = run(add, x, y)
result, node = run_get_node(add, x, y)
result, pk = run_get_pk(add, x, y)
这只是对计算功能非常简短和有限的描述。如需更详细的启动说明,请参阅 launching processes 章节。如果您想了解有关实现计算功能和最佳实践的更多详情,请参阅 working with calculation functions 章节。
计算工作#
在上一节的 calculation functions 中,我们展示了如何将一个简单的 python 函数转换成一个进程,这样当它启动时,它的执行就会自动记录在 provenance graph 中。然而,并不是所有的计算都适合用 python 函数来实现,而是需要用 AiiDA 外部的独立代码来实现。为了将外部代码与 AiiDA 的 engine 接口,引入了 CalcJob 进程类。关于如何实现,接口和最佳实践的详细解释,可以在 later section 中找到。在此,我们将从大处着眼,大致解释计算作业如何模拟外部代码的执行,以及启动后会执行哪些任务。
为了说明计算作业是如何运行的,我们需要一个外部代码。例如,让我们想象一个由 bash 脚本组成的外部代码,它读取包含两个整数的输入文件,将它们相加,然后使用 echo 在标准输出中打印结果:
#!/bin/bash
# Read two integers from file 'aiida.in' and echo their sum
x=$(cat aiida.in | awk '{print $1}')
y=$(cat aiida.in | awk '{print $2}')
echo $(( $x + $y ))
运行时,该脚本会读取名为 aiida.in 的文件内容,并希望其中包含两个整数。它将把这两个整数解析为变量 x 和 y,然后打印它们的和。当你想通过 AiiDA 运行这个 ‘code’ 时,你需要告诉 AiiDA 应该如何运行它。ArithmeticAddCalculation 是一个计算作业的实现,它形成了一个接口来完成示例 bash 脚本。一个特定代码的 CalcJob 实现,通常被称为计算插件,本质上是指示 engine 应该如何运行。这包括如何根据接收到的输入创建必要的输入文件、如何调用代码可执行文件以及计算完成后应检索哪些文件。请注意,文件应该是 ‘retrieved’ 的,因为计算作业不仅可以在本地主机上运行,还可以在任何 computer that is configured in AiiDA 上运行,包括通过 SSH 等方式访问的远程机器。
由于 CalcJob 与之前描述的 calculation functions 一样是一个进程,因此它们可以以相同的方式运行。
from aiida.engine import run
from aiida.orm import Int, load_code
from aiida.plugins import CalculationFactory
ArithmeticAddCalculation = CalculationFactory('core.arithmetic.add')
inputs = {
'code': load_code('add@localhost'),
'x': Int(1),
'y': Int(2),
}
run(ArithmeticAddCalculation, **inputs)
运行计算作业后生成的 provenance 将如下所示:
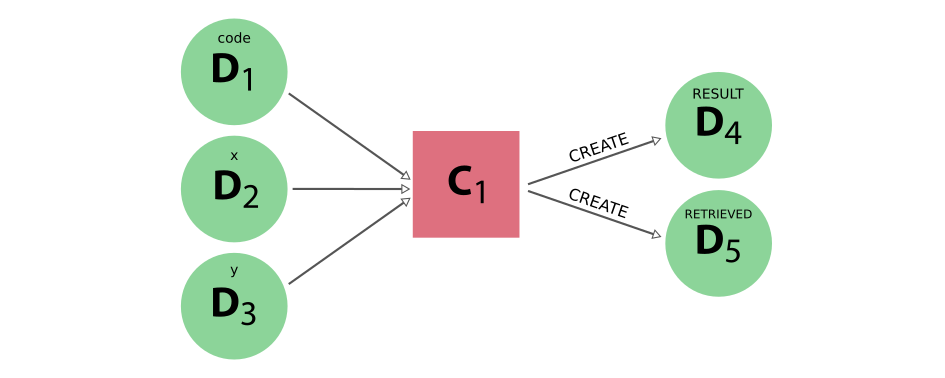
图 12 计算作业示例生成的 provenance#
在 provenance graph 中,计算作业的执行由进程 node 表示,即标有 C:sub:`1` in 图 12 的粉红色方块。作为输入的整数数据 nodes x and y 以及第三个输入 code 都与计算作业相关联。所有计算作业都需要这个输入,因为它代表实际执行的外部代码。这些代码 node 是 AbstractCode 类的实例,是 Data 的子类。这意味着代码实例是一种数据 node。其功能是记录可执行文件的路径和其他一些在代码设置过程中定义的代码相关属性。
计算作业产生了两个输出,一个是包含 x 和 y 之和的整数 node,另一个是包含检索到的输出文件的 FolderData node。请注意,计算作业的所有输出(retrieved node 除外)在技术上都不是由计算作业本身创建的,而是由 Parser 类的实现创建的。原则上,这一步是可选的,因此计算作业不需要产生任何输出,但 retrieved 文件夹中的数据 node 除外。解析器如何融入计算作业概念将在 this section 中讨论。
运输任务#
为了得到上面 图 12 中显示的 provenance graph,engine 执行了很多任务。启动计算作业时,engine 将大致执行以下步骤:
上传 :计算任务执行用于将输入的 nodes 转换为所需的输入文件,并将其上传到目标计算机上的 ‘工作’ 目录中。
提交 :为执行计算,向配置输入 code 的计算机的调度程序提交作业。
更新 :engine 将查询调度程序以检查计算任务的状态
检索 :作业完成后,engine 将检索计算插件指定的输出文件,并将其存储在作为计算输出 node 连接的 node 中。
所有这些任务都需要 engine 与实际运行外部代码的计算机或机器进行交互。由于用作计算任务输入的 AbstractCode 是为特定的 Computer 配置的,因此 engine 完全知道如何执行所有这些任务。因此,CalcJob` 的实现本身完全独立于代码运行的机器。要在不同的机器上运行计算任务,只需将 ``code 输入改为为该机器配置的输入即可。如果机器**不是本地主机,engine 将需要一种连接到远程机器的方法,以便执行上述四项任务中的每一项。允许 engine 连接到远程机器的机制称为 传输 ,因此使用该传输执行的任务称为 传输任务 。
指数后退机制#
在远程计算机上执行计算作业时,engine 必须为每个传输任务连接到计算机。在连接到远程时,可能会出现一系列潜在问题,导致计算作业失败。例如,远程机器可能出现故障而无法连接,或者 engine 本身可能失去互联网连接。不过,这些问题通常都是暂时的。为了防止计算工作中断或永远丢失,engine 采用了 指数回退机制 。每当 engine 执行传输任务但遇到异常时,它不会让计算任务失败,而是会重新安排同一任务在稍后时间再次执行。任务会自动重新安排,直到成功完成为止,每次尝试的间隔时间会以指数形式增加。如果连续 5 次尝试后任务仍然失败,engine 不会重新安排任务,而是直接暂停计算任务。verdi process list 的输出将提供更多有关任务失败原因的信息:
PK Created State Process label Process status
---- ---------- ------------ -------------------------- ---------------------------------------------------------------------------------------
151 1h ago ⏸ Waiting ArithmeticAddCalculation Pausing after failed transport task: retrieve_calculation failed 5 times consecutively
Total results: 1
当计算作业因传输任务多次失败而暂停时,用户有时间调查问题。如果确定问题是暂时的并且已经解决,则可以使用 verdi process play 恢复暂停的进程。然后,engine 将自动重新安排最后失败的任务,计算工作将继续进行。
这种指数后退机制使 engine 在计算作业方面非常稳健,将临时问题造成的计算资源损失降至最低。
备注
重试延迟和最大重试次数等参数目前无法配置,但将来可能可以配置。
解析器#
上一节解释了 CalcJob 类如何作为 AiiDA 的 engine 与外部代码之间的接口。计算任务插件将指示 engine 如何完成 transport tasks 的计算。但是,如前所述,这些任务在检索到输出文件后就会停止,engine 将以 FolderData node 标签 'retrieved' 的形式将输出文件附加到计算作业 node。就计算作业而言,这就是绝对需要的。然而,人们往往希望将这些输出文件解析为一些特定的输出,这些输出应在 provenance graph 中表示为单个的 node。这可以通过实现 Parser 类并在计算任务的输入中指定它来实现。在这种情况下,engine 将在成功检索作业创建的输出文件后调用解析器。在解析器实现过程中,可以对检索到的文件进行解析,并将其转换为输出 node。有关如何为计算作业实施解析器以及如何在输入中指定解析器的技术细节,请参阅 detailed parser section、