Process functions (进程函数)#
进程函数是一个进程(参见 concepts 中的定义和解释),它是作为一个装饰的 python 函数来实现的。目前,有两种类型的进程函数:
前者可以 创建 新数据,而后者可以协调其他流程并 返回 其结果。本节将提供如何实现这两种流程类型的详细信息和最佳实践。由于计算函数和工作函数都是流程函数,并且具有相同的实现方式,因此下面解释的所有规则都适用于这两种流程类型。
The simple example in the introductory section on calculation functions showed how a simple python function can be turned into a calculation function simply by adorning it with the calcfunction() decorator.
When the function is run, AiiDA will dynamically generate a FunctionProcess and build its process specification based on the function signature.
Here we will explain how this is accomplished and what features of the python function signature standard are supported.
函数签名#
要解释 python 函数定义和调用支持哪些功能,我们首先需要弄清一些术语。在处理函数时,有两个截然不同的部分:
下面的代码片段定义了一个简单的 python 函数:
#!/usr/bin/env python
def add_multiply(x, y, z=1):
return (x + y) * z
函数需要三个参数,分别为 x、y 和 z。此外,函数 plain_function 具有默认值,因为一个或多个参数(本例中为 z)的形式为 parameter = expression。调用*函数时,术语略有不同,参数值可以以 ‘positional’ 或 ‘keywords’ 的形式传递。在下面的示例中,使用 ‘positional’ 参数调用函数:
#!/usr/bin/env python
def add_multiply(x, y, z=1):
return (x + y) * z
add_multiply(1, 2, 3) # x=1, y=2, z=3
它们被称为位置参数,因为参数没有明确命名,因此将仅根据它们在函数调用中的位置与相应的参数匹配。在本例中,x、y 和 z 的值分别为 1、2 和 3。由于我们指定了三个值,因此实际上没有使用第三个参数 z 的默认值。但是,我们可以只指定两个参数,在这种情况下,将使用默认值,如下所示:
#!/usr/bin/env python
def add_multiply(x, y, z=1):
return (x + y) * z
add_multiply(1, 2) # x=1, y=2, z=1
如果不指定第三个参数,将使用默认值,因此在本例中 z 将等于 1。此外,我们还可以使用 ‘命名’ 参数,根据参数的名称来确定参数的目标,而不必依赖参数的位置:
#!/usr/bin/env python
def add_multiply(x, y, z=1):
return (x + y) * z
add_multiply(z=1, y=2, x=1) # x=1, y=2, z=1
请注意,我们传递参数的顺序并不重要,因为我们在赋值时明确指定了每个参数的名称。既然我们知道了位置参数和命名参数的区别,我们就可以 important 地理解 python 的要求: 位置参数必须在命名参数之前 。这意味着下面的函数定义和函数调用都是非法的,因为在位置参数之前有命名参数:
#!/usr/bin/env python
def add_multiply(x, y=1, z):
return (x + y) * z
add_multiply(x=1, 2, 3) # Raises `SyntaxError` in definition and call
最后,python 知道 *args 和 **kwargs 的概念,它们允许定义一个接受可变数量的位置参数和关键字参数的函数(也称为 _variadic_ 函数)。
#!/usr/bin/env python
def add(*args, **kwargs):
return sum(args) + sum(kwargs.values())
add(4, 5, z=6) # Returns 15
位置参数占位符 *args 以元组的形式接收位置传递的参数,而 **kwargs 则以字典的形式接收命名参数。正式定义说完了,现在让我们看看流程函数支持这些概念中的哪些。
默认参数#
与普通的 python 函数一样,计算函数也支持默认参数,只要它是 Node 实例,就像输入或 None 一样。不过,与 python 函数一样,我们只能使用不可变对象作为函数默认值,因为可变对象会在函数调用之间保留,可能会产生意想不到的结果。因此,要在进程函数中使用默认值,只需使用 None 作为默认值,并在函数体设置中检查其是否存在默认值(如果是 None )。这种模式如下所示:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add_multiply(x, y, z=None):
if z is None:
z = Int(3)
return (x + y) * z
result = add_multiply(Int(1), Int(2))
result = add_multiply(Int(1), Int(2), Int(3))
上述示例中的两个函数调用结果完全相同。
变式参数#
如果进程函数需要使用的参数数量事先未知,则可以有效地使用关键字参数:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add(**kwargs):
return sum(kwargs.values())
result = add(alpha=Int(1), beta=Int(2), gamma=Int(3))
该示例生成的 provenance 看起来如下:
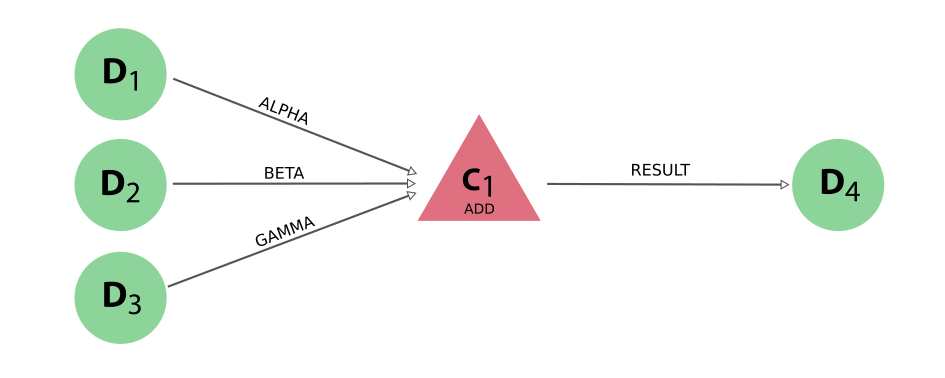
图 9 输入的链接标签是根据函数调用时参数的命名确定的。#
请注意,输入 必须作为关键字参数传递 ,因为它们用于链接标签。
在 2.3 版本加入: Variadic positional arguments are now supported
Variadic positional arguments can be used in case the function should accept a list of inputs of unknown length.
Consider the example of a calculation function that computes the average of a number of Int nodes:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def average(*args):
return sum(args) / len(args)
result = average(*(Int(1), Int(2), Int(3)))
结果将是 Float node(示例中的值为 2. Since in this example the arguments are not explicitly declared in the function signature, nor are their values passed with a keyword in the function invocation, AiiDA needs to come up with a different way to determine the labels to link the input nodes to the calculation. For variadic arguments, link labels are created from the variable argument declaration (*args),后面跟一个索引。因此,上例中的链接标签将是 args_0 、 args_1 和 args_2 。如果这些标签中的任何一个与位置参数或关键字参数的标签重叠,就会出现 RuntimeError 。在这种情况下,需要将有冲突的参数名称改为不与自动生成的变量参数标签重叠的名称。
类型验证#
在 2.3 版本加入.
类型提示(在 Python 3.5 中引入了 PEP 484 )可用于为进程函数参数添加自动类型验证。例如,下面的代码会引发 ValueError 异常:
from aiida.engine import calcfunction
from aiida.orm import Float, Int
@calcfunction
def add(x: Int, y: Int):
return x + y
add(Int(1), Float(1.0))
在声明流程函数时,流程规范 ( ProcessSpec ) 会动态生成。对于每个函数参数,如果提供了正确的类型提示,就会将其设置为相应输入端口的 valid_type 属性。在上面的示例中,x 和 y 输入的类型提示是 Int ,这就是传递 Float 的调用会引发 ValueError 的原因。
备注
目前不解析返回值的类型提示。
如果参数接受多种类型,则可以正常使用 typing.Union 类:
import typing as t
from aiida.engine import calcfunction
from aiida.orm import Float, Int
@calcfunction
def add(x: t.Union[Int, Float], y: t.Union[Int, Float]):
return x + y
add(Int(1), Float(1.0))
现在,带有 Int 和 Float 的调用将正确完成。同样,可选参数(默认为 None )也可以使用 typing.Optional 声明:
import typing
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add_multiply(x: Int, y: Int, z: typing.Optional[Int] = None):
if z is None:
z = Int(3)
return (x + y) * z
result = add_multiply(Int(1), Int(2))
result = add_multiply(Int(1), Int(2), Int(3))
也支持 postponed evaluation of annotations introduced by PEP 563 。这意味着可以使用 Python 基本类型来进行类型提示,而不是 AiiDA 的 Data node 等效类型:
from __future__ import annotations
from aiida.engine import calcfunction
@calcfunction
def add(x: int, y: int):
return x + y
add(1, 2)
类型提示会自动序列化,就像调用函数时实际输入一样, as introduced in v2.1 。
还支持联合类型 X | Y as introduced by PEP 604 的替代语法:
from __future__ import annotations
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add_multiply(x: int, y: int, z: int | None = None):
if z is None:
z = Int(3)
return (x + y) * z
result = add_multiply(1, 2)
result = add_multiply(1, 2, 3)
警告
即使添加了 from __future__ import annotations 语句,PEP 563 和 PEP 604 所定义的符号用法也不支持 Python 3.10 以上的版本。原因是类型推断使用了 Python 3.10 中引入的 inspect.get_annotations 方法。对于较早的 Python 版本,可以使用 get-annotations 后向端口,但它在 PEP 563 和 PEP 604 中不起作用,因此必须使用 typing 模块中的构造。
如果进程函数的类型提示无效,则会被忽略并记录警告信息: function 'function_name' has invalid type hints .这确保了在现有进程函数具有无效类型提示时的向后兼容性。
文档字符串解析#
在 2.3 版本加入.
如果流程函数提供了 docstring,AiiDA 将尝试解析它。如果成功,函数参数描述将被设置为动态生成的流程规范的输入端口的 help 属性。这意味着函数参数的描述可以通过程序从流程规范中获取(由 spec 类方法返回):
from aiida.engine import calcfunction
@calcfunction
def add(x: int, y: int):
"""Add two integers.
:param x: Left hand operand.
:param y: Right hand operand.
"""
return x + y
assert add.spec().inputs['a'].help == 'Left hand operand.'
assert add.spec().inputs['b'].help == 'Right hand operand.'
这对在包装工作链中暴露process function特别有用:
from aiida.engine import WorkChain, calcfunction
@calcfunction
def add(x: int, y: int):
"""Add two integers.
:param x: Left hand operand.
:param y: Right hand operand.
"""
return x + y
class Wrapper(WorkChain):
"""Workchain that exposes the ``add`` calcfunction."""
@classmethod
def define(cls, spec):
super().define(spec)
spec.expose_inputs(add)
现在,用户可以直接通过工作链的规格访问输入描述,而无需进入流程功能本身。例如,在交互式 shell:
In [1]: builder = Wrapper.get_builder()
In [2]: builder.x?
Type: property
String form: <property object at 0x7f93b839a900>
Docstring: {
'name': 'x',
'required': 'True',
'valid_type': "(<class 'aiida.orm.nodes.data.int.Int'>,)",
'help': 'Left hand operand.',
'is_metadata': 'False',
'non_db': 'False'
}
返回值#
在 图 9 中,您可以看到 engine 使用标签 result 连接计算函数 node 及其输出 node 的链接。如果计算函数只返回一个结果,这是默认的链接标签。如果您想自己指定标签,可以以字典形式返回结果,其中的键将用作链接标签。通过使用字典,还可以记录多个 node 作为输出。请看下面的代码段:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def sum_and_difference(alpha, beta):
return {'sum': alpha + beta, 'difference': alpha - beta}
result = sum_and_difference(Int(1), Int(2))
运行此计算函数后生成的 provenance 将显示如下:
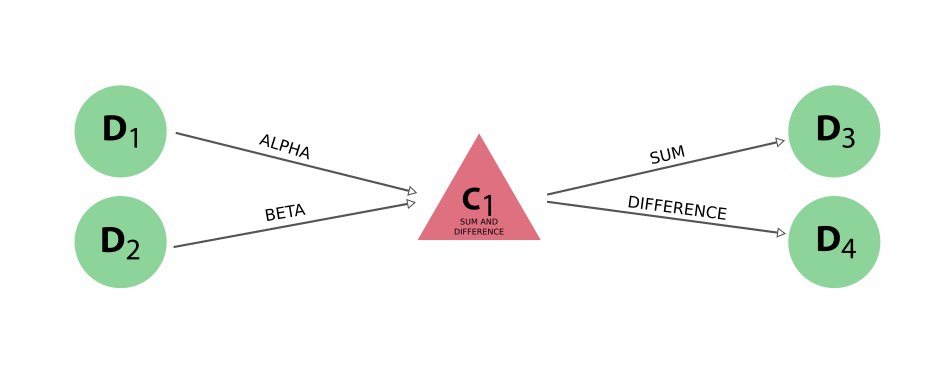
图 10 如果返回的是字典,则键将用作连接输出 node 和计算 node 的链接的标签。#
与往常一样,计算函数返回的所有值都必须是可存储的,这意味着它们必须是 Node 类的实例。
警告
在从 calcfunction 返回 node 之前,请勿自行调用 important store() 。由于 AiiDA 中计算/workflow 的二元性, calcfunction 作为一个类似计算的过程,只能 创建 而不能 返回 数据 node。这意味着,如果从已存储*的 calcfunction 返回 node,engine 将出现异常。
在 2.3 版本加入: Outputs with nested namespaces
输出标签中可附加嵌套命名空间:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add(alpha, beta):
return {'nested.sum': alpha + beta}
result = add(Int(1), Int(2))
assert result['nested']['sum'] == 3
退出代码#
到目前为止,我们只看到了计算函数中一切正常的例子。然而,现实世界是不同的,我们经常会遇到出现问题的情况。计算函数可能会接收到不正确或不连贯的输入,或者其执行的代码可能会抛出异常。当然,我们可以抛出输入验证异常,或者甚至不捕获我们调用的代码抛出的异常,但这将导致函数进程进入 Excepted 终端状态。正如在 process state 章节中解释的那样,这种状态确实是为在执行过程中发生异常的进程保留的。请看下面的计算函数定义和调用:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def divide(x, y):
return x / y
result = divide(Int(1), Int(0))
由于传递的 y 值为零,因此 engine 在运行计算函数时将遇到 ZeroDivisionError 异常。 verdi process list 的输出将确认进程已发生异常:
PK Created State Process label Process status
---- --------- ---------------- --------------- ----------------
10 2m ago ⨯ Excepted divide
Total results: 1
进程执行过程中出现的异常会作为日志信息记录在相应的进程 node 中。要显示这些日志信息,可以使用 verdi process report 。在上面的示例中,它会显示如下内容:
2019-03-21 15:12:25 [19]: [10|divide|on_except]: Traceback (most recent call last):
File "/home/sphuber/code/aiida/env/dev/plumpy/plumpy/process_states.py", line 220, in execute
result = self.run_fn(*self.args, **self.kwargs)
File "/home/sphuber/code/aiida/env/dev/aiida-core/aiida/engine/processes/functions.py", line 319, in run
result = self._func(*args, **kwargs)
File "docs/source/working/include/snippets/functions/calcfunction_exception.py", line 6, in divide
return x / y
File "/home/sphuber/code/aiida/env/dev/aiida-core/aiida/orm/nodes/data/numeric.py", line 30, in inner
return to_aiida_type(func(left, right))
File "/home/sphuber/code/aiida/env/dev/aiida-core/aiida/orm/nodes/data/numeric.py", line 75, in __div__
return self / other
ZeroDivisionError: division by zero
不过,在这个特殊示例中,异常并不是什么意料之外的错误,而是一个我们本可以考虑到并预见到的错误,所以简单地将进程标记为失败可能更适用。为了达到这个目的,我们可以在进程上设置一个 exit status 的概念,它是一个整数,当非零时,会将处于 Finished 状态的进程标记为 失败。由于退出状态被设置为进程 node 的属性,因此查询失败进程也变得非常容易。要在计算函数上设置一个非零的退出状态以显示其失败,只需返回一个 ExitCode 类的实例即可。演示时间到
from aiida.engine import ExitCode, calcfunction
from aiida.orm import Int
@calcfunction
def divide(x, y):
if y == 0:
return ExitCode(300, 'cannot divide by 0')
return x / y
result = divide(Int(1), Int(0))
当我们现在使用相同的输入运行计算函数时,进程将成功终止,其退出状态将设置为存储在 ExitCode 中的值。退出状态也由 verdi process list 显示:
PK Created State Process label Process status
---- --------- ---------------- --------------- ----------------
10 2m ago ⨯ Excepted divide
773 21s ago ⏹ Finished [300] divide
Total results: 2
这两种方法都有效,使用哪一种取决于您的使用情况。你应该问自己的问题是,一个潜在的问题是否值得把进程扔到 ‘excepted’ 进程堆里。或者,就像上面的例子一样,问题是很容易预见的,并且可以通过明确定义的退出状态进行分类,在这种情况下,返回退出代码可能更有意义。最后,我们应该考虑哪种解决方案更容易让调用函数的 workflow 根据结果做出响应,以及哪种解决方案更容易查询这些特定的故障模式。
作为类成员方法#
在 2.3 版本加入.
进程函数也可以声明为类成员方法,例如作为 WorkChain 的一部分:
class CalcFunctionWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('x')
spec.input('y')
spec.output('sum')
spec.outline(
cls.run_compute_sum,
)
@staticmethod
@calcfunction
def compute_sum(x, y):
return x + y
def run_compute_sum(self):
self.out('sum', self.compute_sum(self.inputs.x, self.inputs.y))
在本例中,工作链声明了一个名为 compute_sum 的类方法,并使用 calcfunction 装饰器将其装饰为一个计算函数。important 方法还使用了 staticmethod (参见 Python documentation )装饰,这样在调用方法时就不会传递工作链实例。如最后一行所示,calcfunction 可以像其他类方法一样从工作链步骤中调用。
Provenance#
除了存储所有进程的基本属性(如进程状态和标签)外,进程函数还会自动存储与其所代表函数的源代码相关的附加信息:
功能名称
函数名称空间
功能起始行号
功能源文件
前三个属性在进程函数执行后立即通过检查 python 源代码获取,并作为属性存储在进程 node 中。可以通过进程 node 的相应属性访问它们,如下所示:
from aiida.engine import calcfunction
from aiida.orm import Int
@calcfunction
def add(x, y):
return x + y
result, node = add.run_get_node(Int(1), Int(2))
print(node.function_name) # add
print(node.function_namespace) # __main__
print(node.function_starting_line_number) # 4
定义函数的文件源代码也会被存储起来,但由于它可能相当大,所以作为原始文件存储在 process node 的存储库中。可通过 get_source_code_file() 方法检索。
这些属性为存储在 provenance graph 中的进程函数提供了一定的可查询性,而且通过存储已执行函数的源代码,将来还可以跟踪函数是如何创建输出 nodes 的。但要注意的是,仅仅存储函数的源文件并不能保证可以重现准确的结果。例如,可以通过读取文件或从数据库加载现有 node 来向函数 ‘泄露’ 数据,而这些数据并没有明确作为输入传递。另外,也可以调用外部代码 import,但不会记录其源代码。
可重复性准则#
由于流程功能实现方式的性质,不可能保证 100% 的重现性,但通过遵循以下指导原则,可以尽可能地接近重现性。
不要将数据泄漏到函数中
限制外部代码的 importing
保持功能自洽,并保存在不同的文件中
例如,通过在函数体中读取本地文件系统中的文件并使用其内容创建输出,就可以在函数中泄露数据。即使存储了源代码,如果不拥有被读取的文件,也不可能重现结果。同样,您也不应该通过应用程序接口从数据库中加载任何现有数据,而应该将它们作为流程函数的直接输入。
在 import 其他 python 代码时也会出现类似的问题。实际上,将 import 代码加入进程函数几乎是不可能的,因为这将迫使代码大量重复。然而,从 aiida-core 库或进程函数所在的资源库中 import 代码与 import 本地 python 文件之间仍有区别。尽管这两种情况都无法保证可重复性,但前者的机会更大,因为插件包的版本号应该被记录下来。因此,经验法则是尽量减少代码的 import,但如果必须这样做,请确保将其作为具有明确版本号的插件包的一部分。
最后,如前言所述,process function 的源文件在每次执行时都会以文件形式存储在存储库中。默认存储后端 core.psql_dos 使用 disk-objecstore 软件包进行文件存储,它会自动复制文件。不过,这不一定适用于其他存储后端,因为这些文件可能会占用大量空间。因此,建议将每个 process function 保存在各自独立的文件中。