一致性#
由于科学研究的本质,删除数据库的部分内容(例如,如果出现错误、输入拼写错误或进行了无用的计算)或导出数据库(用于合作或出版目的)变得不可或缺。AiiDA 提供的这两种功能都有一个共同点:它们很容易导致 provenance graph 信息不完整。为了更好地理解原因,让我们来看看下面的基本 provenance graph:

即使在这个简单的例子中,如果我们只导出计算 node 和输出数据 node(或者只删除输入数据 node),那么我们将丢失运行计算所需的部分关键信息(D1 node),从而失去计算 C1 的可重复性。因此,在这个简单的例子中,为了得到一致的 provenance,每当导出一个计算 node 时,必须同时导出其所有输入 node 的 import (或者,对称地,每当删除一个数据 node 时,必须同时删除将其作为输入的所有计算)。
这只是手动编辑 provenance 数据库时必须考虑的众多规则之一。需要记住的关键信息是,AiiDA 不仅会删除或导出用户明确指定的 node,还会在生成的数据库中包含任何其他需要保持 provenance 一致的 node。
值得注意的是,如果你连续导出部分信息,AiiDA可以重建导出数据时可能中断的链接。因此,如果你先导出上一个图表,然后再导出完整数据库的下一个部分:

然后 AiiDA 就能自动识别共享的 node D2,并在 import process 期间将两个部分连接起来。对于这种识别,先导出哪个子图并不重要。
在下一节中,我们将更详细地解释纳入其他 node 的标准和相应的遍历规则。
遍历规则#
当你运行 verdi node delete [NODE_IDS] 或 verdi archive create -N [NODE_IDS] 时,AiiDA 会查看从你指定的 node 传入或传出的链接,并决定是否有其他 node 需要保留。
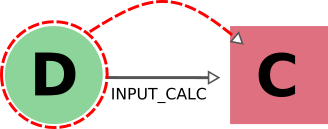
对于这个决定,不仅要考虑链接的类型,还要考虑是沿其方向(我们称之为 forward 方向)还是反方向( backward 方向)。为了说明这一点,在上面的例子中,当删除数据 node D1 时,AiiDA 将沿 forward 方向跟踪 input_calc 链接(在这种情况下,它将决定链接的 node (C1) 也必须删除)。如果初始目标 node 是 C1,那么 input_calc 链接将沿 backward 方向移动(在这种情况下,node D1 不会被删除,下文将对此进行说明)。
这个 process 将递归地重复每一个刚刚被列入删除或导出的 node,直到不再需要添加 node。定义是否将链接的 node 添加到删除/导出列表的规则(基于链接的种类和方向)被称为 遍历规则 。在下一节中,我们将介绍这些规则在导出和删除程序中的应用。
下表根据涉及的 node 和链接类型进行了分组。我们还提供了所考虑案例的示例,其中被包围的 node 是我们的目标,而另一个 node (红色箭头所指)是我们正在考虑添加到删除/导出列表中的 node。
数据和计算 Nodes#
上面第一个例子已经讨论了删除输入 node 的情况:在这种情况下,必须同时删除将其作为输入的任何计算。
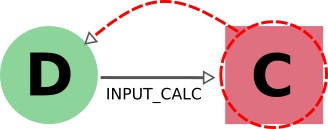
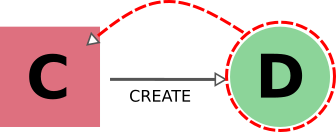
在 AiiDA 中,我们在删除一个输出时也采用同样的标准:在这种情况下,我们沿着 create 链接的 backward 方向,同时标记删除创建它的计算。这样做的原因是,缺少输出的计算可能会产生误导。例如,某些计算会根据输入标志的组合产生可选输出。缺失的输出可能会被解释为计算没有计算该信息。在输出的情况下,规则通常与删除的规则相反。因此,在这种情况下适用以下规则:导出计算 node 时,必须同时导出其所有输入数据 node 和创建的输出 node。
另一方面,在导出数据 node 时,用户通常不需要同时导出将其作为输入的所有计算。这些计算可能代表进一步的工作,默认情况下不需要同时导出(除非用户在 node 列表中明确指定)。同样,在删除计算时,我们通常希望保留其输入,因为它们可能会被其他无关的计算使用。
怎样才能删除计算的输出?通常情况下,我们可能希望删除(递归)计算所产生的所有输出。不过,我们给用户留了一个选项,即只删除计算,将其输出保留在数据库中。虽然我们强调这一操作会删除输出 nodes 的所有 provenance 信息,但在某些情况下,这一操作是有用的,甚至是必要的(删除受版权保护的输入,或创建一个较小的归档文件,以传输给希望使用输出数据的合作者)。
示意图(明确锁定的 node 已被圈住) |
规则名称 |
导出目标时的行为 node |
删除目标时的行为 node |
|---|---|---|---|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
数据和 Workflow Nodes#
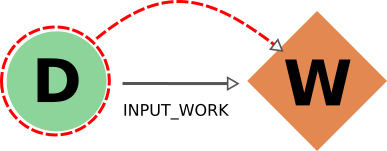
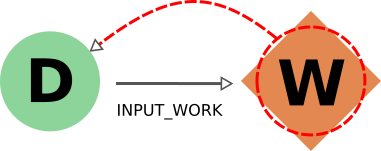
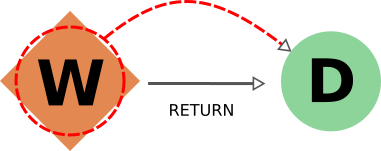
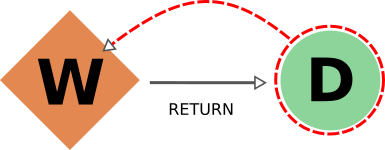
由于同样的原因,考虑 input_work 链接时的行为与考虑 input_calc 链接时的行为完全相同。 return 链接的情况与 create 链接的情况部分相似。事实上,我们不希望生成的数据库有缺失的输出,因此在导出 workflow 时,返回的数据 nodes 也将包括在内(删除数据 node 时,返回的 workflow 也将删除)。不过,在导出返回的 node 时,默认行为是**不通过 return 链接向后遍历,因为一个数据 node 可能会被多个与其创建无关的 workflow(例如代表其他研究的选择程序)返回。负责协调其创建的 workflow 将包含在导出中,但不是直接包含,而是通过包含创建计算(通过 create_backward ),然后包含其调用的 workflow 的连锁效应(通过 call_calc_backward 和 call_work_backward ,见下节)。
示意图(明确锁定的 node 已被圈住) |
规则名称 |
导出目标时的行为 node |
删除目标时的行为 node |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Workflows 和计算 Nodes#
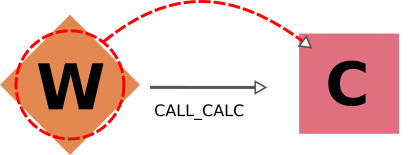
最后,我们将考虑 processes 之间可能存在的(调用)联系。父 workflow 的结果主要取决于子 workflow 或由其启动的计算。因此,在导出 workflow node 时,我们总是沿 forward 方向遍历其 call 链接( call_calc 和 call_work ),以包括所有子 processes(即直接被其调用的 processes)。由于遍历规则是递归应用的,这意味着作为目标子代的任何 workflow 的子代 processes 也将被导出,依此类推。类似地,删除 process 时也是如此,但方向相反 ( backward ),包括目标 node 的父节点 workflow(如果有的话)以及该父节点的父节点,等等。
由于 call 链接默认情况下是向后跟踪的,因此导出或删除一个 process 时,不仅会选择其所有子 process,还会选择其任何父 process 的所有子 process。由于所有 call 链接都是双向遍历的,因此在 workflow 中选择任何一个 process node 都意味着也会包括该 workflow 中的其他 process。用户可以禁止在其中一个方向上遍历 call 链接( forward 用于删除, backward 用于导出),以实现精细控制(请参阅下面的示例)。
示意图(明确锁定的 node 已被圈住) |
规则名称 |
导出目标时的行为 node |
删除目标时的行为 node |
|---|---|---|---|
|
|
|
|
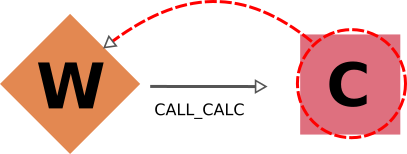
|
|
|
|
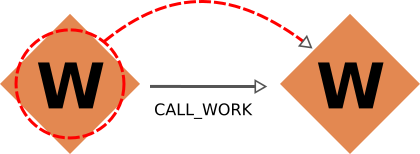
|
|
|
|
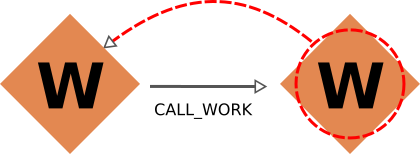
|
|
|
|
层叠规则:示例#
在前面的章节中,我们描述了 AiiDA 用来决定哪些 nodes 也应该包含在要删除或导出的 nodes 初始列表中的基本规则。这些规则是递归应用的:当新的 node 被纳入删除(或导出)列表时,这些规则也会被应用,直到没有新的 node 被纳入为止。因此,在给定的 node 数据集上使用这些功能的结果可能并不总是很直接,最终数据集所包含的 node 数据可能比天真地预期的要多。
首先,我们只关注数据 provenance(即只有 input_calc 和 create 链接)。沿着 forward 方向前进时,以下两条规则适用:
如果删除数据 node,任何使用该数据作为输入的计算也将被删除(
input_calc_forward=True)。如果删除计算 node,任何输出数据 node 都将被删除 * 默认* (
create_forward=True)。
二者结合的结果是 ``chain reaction``,其中每个可以通过数据 provenance 追溯到任何初始目标 node 的 node 最终也会被删除。导出的情况也是如此:默认情况下,每个祖先也会被导出(因为 create_backward 默认情况下是 True ,而 input_calc_backward 始终是 True )。
关于数据 provenance 和逻辑 provenance 之间的联系,最 important 需要了解的是程序的默认行为是如何将最高级别的 workflow 作为要处理的单元的。这背后的逻辑是假定程序的典型用户将主要以交互方式使用程序,通过 verdi 命令行运行预定义的 workflow 而无需详细了解其内部程序。因此,默认行为的设计就是为了重现这种使用方式下最直观的结果。
这种行为基本上是 call_calc_forward=True 和 call_work_forward=True 设置的结果,即包含 process node 也意味着包含任何子 process node 或父 process node。以递归方式遵循这些规则会导致命令影响任何给定 workflow 中的所有 process:这样,作为给定最高级 workflow 的子 process 的 node 最终会被组合在一起,也就是说(默认情况下)在删除或导出时,它们都会受到同样的影响。
通过每种功能的特定可切换标记,可以更自由地进一步自定义选择要导出或删除的部分(尽管最终部分必须始终遵守不可切换规则,见上文)。不过,这通常需要对遍历规则有更深入的了解,并可能意味着要对特定图进行更透彻的分析。为了更好地说明这一点,我们现在来看看删除程序在下图中的应用:
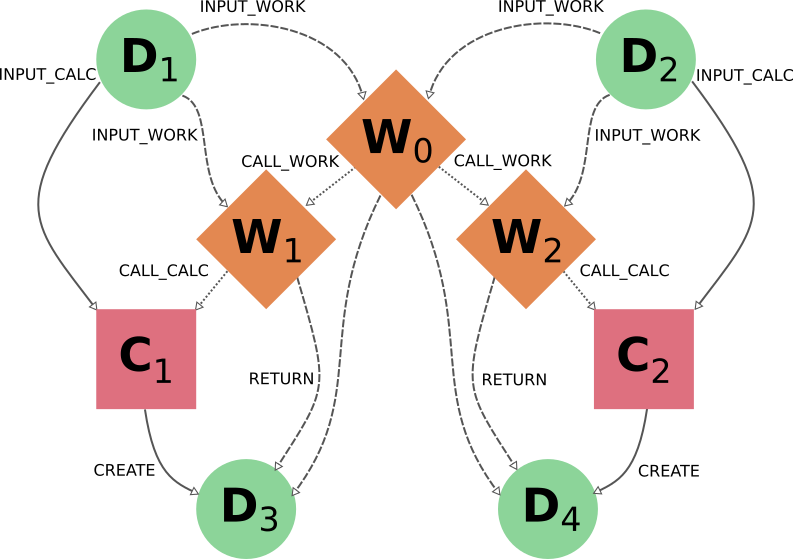
正如您所看到的,W1 和 W2 描述了两个相似但独立的程序,它们由一个父程序 workflow W0 启动。一般用户会通过直接运行 workflow W0 从输入 D1 和 D2 得到结果 D3 和 D4,甚至可能不知道 W0 内部分为两个子 Workflow W1 和 W2。因此,如果用户认为 workflow(指由它产生的整组 node)不再有必要,那么要从数据库中删除它,直观的做法就是将 workflow node W0 作为删除目标。事实上,这样做可以达到预期的效果:
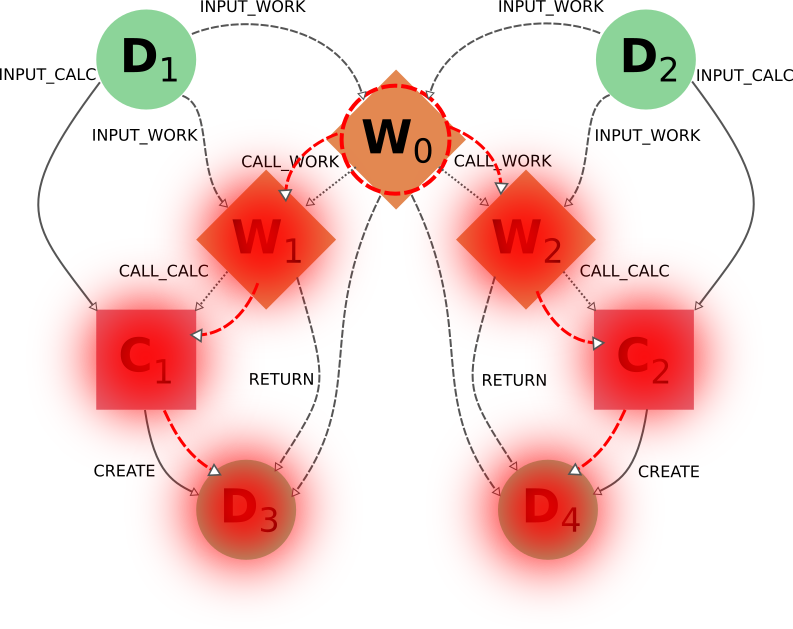
由于 W0 是目标 ( call_work_forward=True ),node 的 W1 和 W2 将被包括在内,然后 node 的 C1 和 C2 也将被包括在内 ( call_calc_forward=True ),最后 node 的 D3 和 D4 也将被包括在内 ( create_forward=True )。最后,只剩下 D1 和 D2 (因为默认值为 input_work_backward=False 和 input_calc_backward=False )。
如果用户以输出 nodes 为目标(打算删除与获得这些结果相关的所有内容),也会出现同样的结果。important 值得注意的是,即使用户只删除其中一个输出结果,workflow 生成的整组 nodes 也会被删除,而不仅仅是与目标数据 node 相关的那些。由于 D3 和 D4 这两个结果是从同一个高层 process W0 中得到的,因此默认行为的基本假设是它们是相互关联的,而不是相互独立的(就好像它们是一个计算的两个不同输出)。
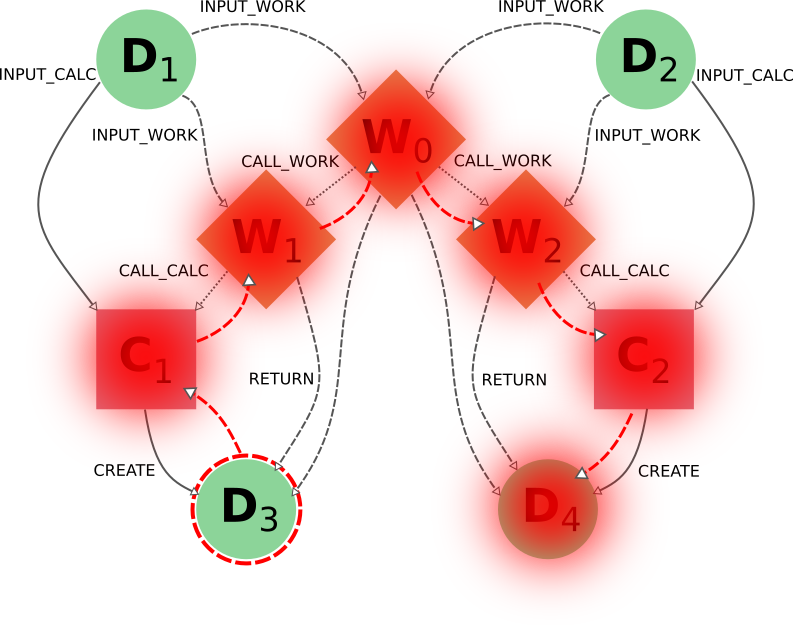
在这种情况下,node C1 首先会被包括在内,因为目标数据 node D3 ( create_reverse=True ),这反过来又会包括 node W1 ( call_calc_reverse=True ),然后是它的父数据 workflow W0 ( call_work_reverse=True )。然后,node 的 W2、C2 和 D4 将被包括在内,因为 W0 也被包括在内,原因与上文各段所述相同。
自定义图形遍历(用于删除或导出)#
node 之间的这种依存关系尤其适用于这样的情况,例如,当用户对父 workflow W0 的内部程序有更多了解,希望只删除与 workflow W1 相关的计算和结果时。以 W1 为目标的直观操作并不能产生预期的结果:
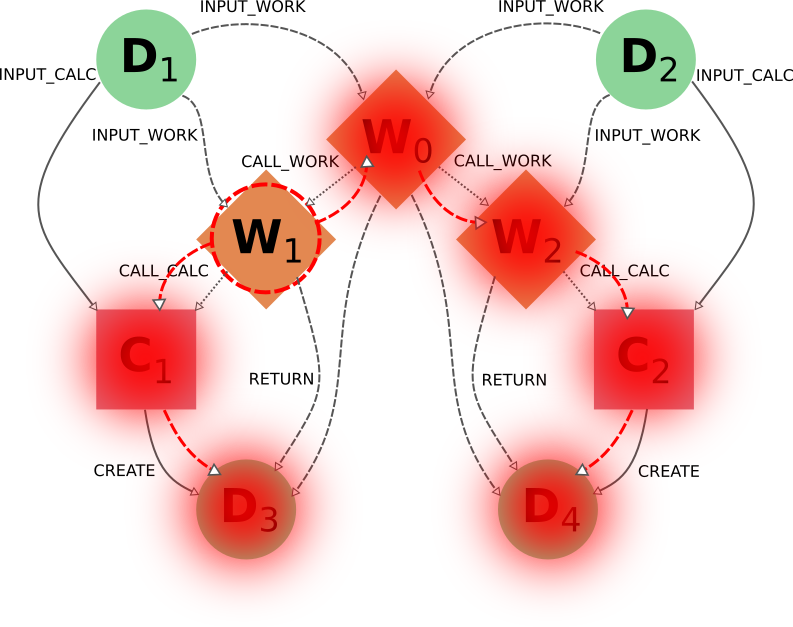
事实上,C1 和 D4 将被删除(通过 call_calc_forward 从 W1 到 C1,以及通过 create_forward 从 C1 到 D3)、但 W0 (从 W1 至 call_work_reverse )、W2 (从 W0 至 call_work_forward )、C2 (从 W2 至 call_calc_forward )和 D4 (从 C2 至 create_forward )也是如此。实现理想结果的方法并不简单,不过在某些类似情况下,我们可以提出针对具体情况的解决方案,例如针对 W1 使用可切换标记 call_work_forward=False (防止从 W0 遍历到 W2):
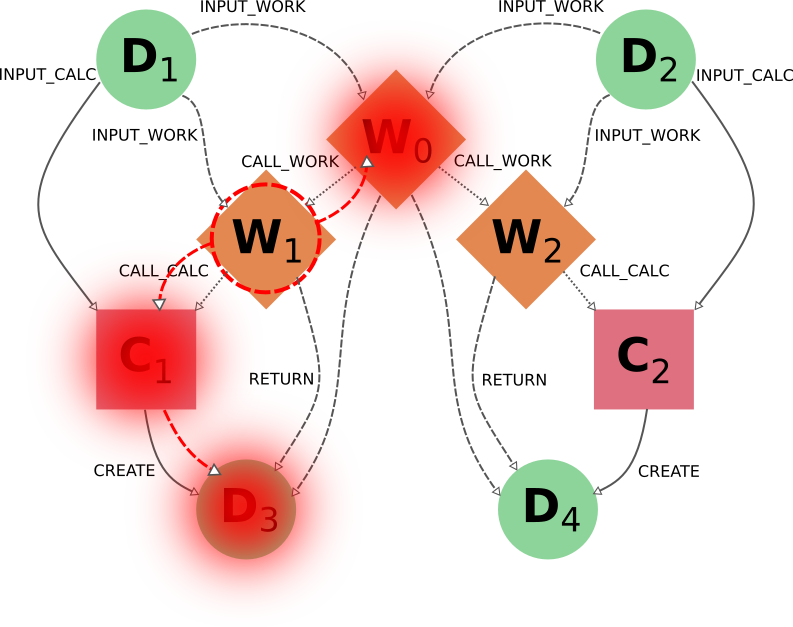
不过,这种方法并不普遍适用,如果 W1 有子 workflow 也需要删除,这种方法就行不通了。更普遍的方法是,首先通过删除 node W0 切断与 W2 的连接,并关闭所有可切换的遍历规则。然后,一旦图中明确反映出 W1 和 W2 的独立性,就可以使用默认设置删除 node W1。
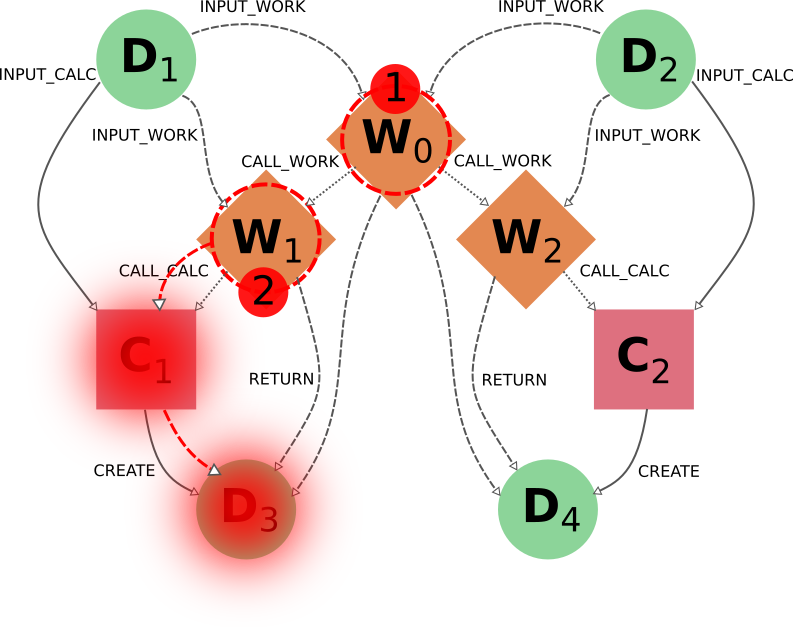
值得注意的是,如果 workflow W0 本身是上一级 workflow 的一部分,那么由于不可切换规则 call_work_reverse=True 的存在,所有上一级逻辑都将被删除。这是删除 workflow 的部分内容不可避免的结果,因为失去了这些信息,workflow 就变得不完整了,保留它毫无意义。