如何编写容错的 workflows#
概述
本手册将介绍 BaseRestartWorkChain 以及如何对其进行子类化,以处理流程和计算的已知故障模式。
在 how-to on writing workflows 中,我们讨论了如何使用作业链编写简单的多步 workflow。但是,有一点我们没有考虑到:
如果计算步骤失败怎么办?
例如, MultiplyAddWorkChain 启动 ArithmeticAddCalculation 。如果计算失败,工作链将无法运行,因为 self.ctx.addition.outputs.sum 行将引发 AttributeError 。在这种情况下,工作链只运行一次计算,这并不是什么大问题,但在现实生活中,工作链会依次运行多次计算,如果工作链出现 except,那么到此为止的所有工作都将丢失。以使用量子 ESPRESSO 计算晶体结构声子的 workflow 为例:
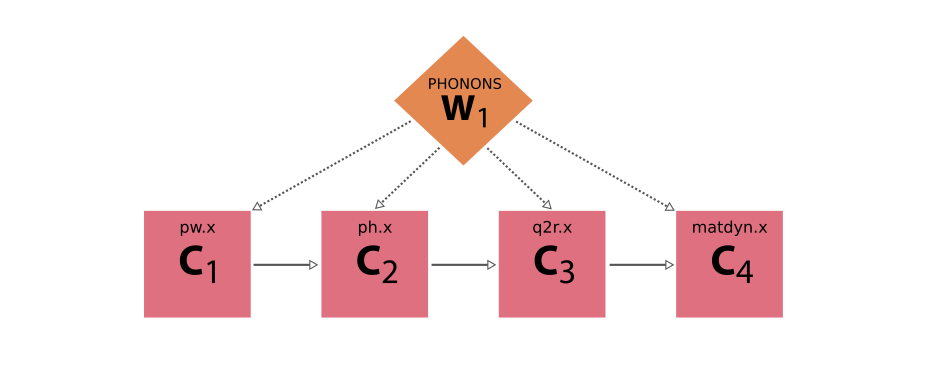
图 4 利用量子 ESPRESSO 计算晶体结构声子的 workflow 的 Schematic 图。workflow 包括四次连续计算,分别使用 pw.x 、 ph.x 、 q2r.x 和 matdyn.x 代码。#
如果所有计算都顺利进行,那么 workflow 本身当然也会运行正常,并产生所需的最终结果。但现在设想一下,第三次计算实际上失败了。如果 workflow 没有明确检查这一失败,而是盲目地认为计算已经产生了所需的结果,那么它本身就会失败,从而失去前两次计算所取得的进展。
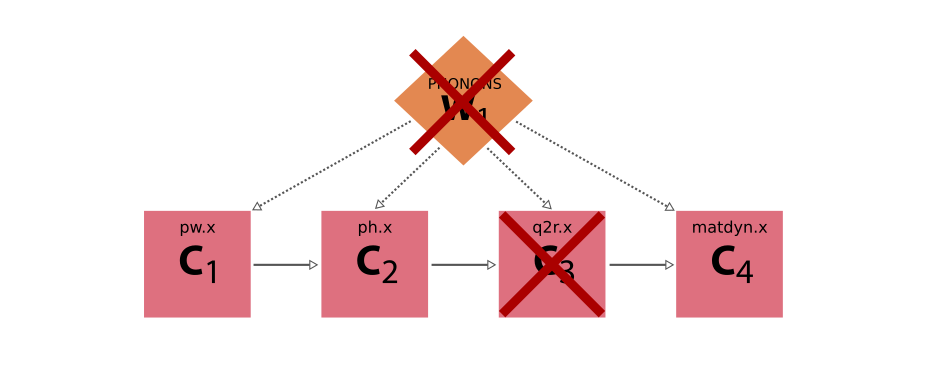
图 5 量子 ESPRESSO 声子 workflow 的执行示例,其中第三步 q2r.x 代码失败,并且由于 workflow 盲目地认为它会在没有错误的情况下完成,因此也失败了。#
这样看来,解决方案似乎很简单。在每次计算后,我们只需添加一个检查,以验证计算是否成功完成并产生所需的输出,然后再继续下一次计算。但如果计算失败了,我们该怎么办呢?根据计算失败的原因,我们也许真的可以解决问题,重新运行计算,并可能使用修正后的输入。一个常见的例子是,计算耗尽了挂壁时间(向作业调度程序请求的时间),被作业调度程序取消。在这种情况下,只需重新启动计算(如果代码支持重新启动),并有选择地给予作业更多的墙时间或资源,就可能解决问题。
您可能很想直接在 workflow 中添加错误处理功能。但是,这需要在其他 workflow 中多次执行相同的错误处理代码,而这些 workflow 恰好运行相同的代码。例如,我们可以直接在我们的声子 workflow 中添加 pw.x 代码的错误处理,但结构优化 workflow 也必须运行 pw.x ,并且必须执行相同的错误处理逻辑。有什么办法能让我们只需实现一次,就能在不同的 workflow 中轻松重复使用?
是的!与其直接在 workflow 中运行计算,不如运行一个明确设计用于完成计算的工作链。这个 基础 工作链知道计算的各种失败模式,可以尝试修复问题,并在计算失败时重启计算,直到计算成功完成。这种基础工作链的逻辑非常通用,可以应用于任何计算,实际上也可以应用于任何流程:
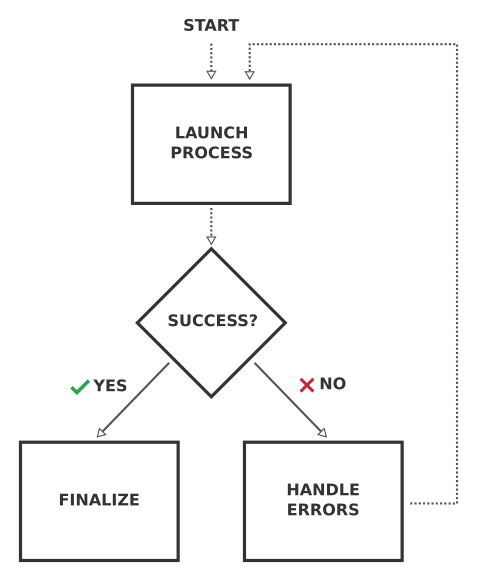
图 6 Schematic 基准工作链逻辑流程图,其任务是重复运行子进程,修正任何可能的错误,直到成功完成。#
工作链运行子进程。完成后,它将检查状态。如果子进程成功完成,工作链就会返回结果,完成工作。如果子进程失败,工作链应检查失败原因,并尝试解决问题和重新启动子进程。如此循环往复,直到子进程成功结束。当然,如果工作链始终无法解决问题,就有可能陷入无限循环,因此我们希望对可重新运行的最大计算次数加以限制:
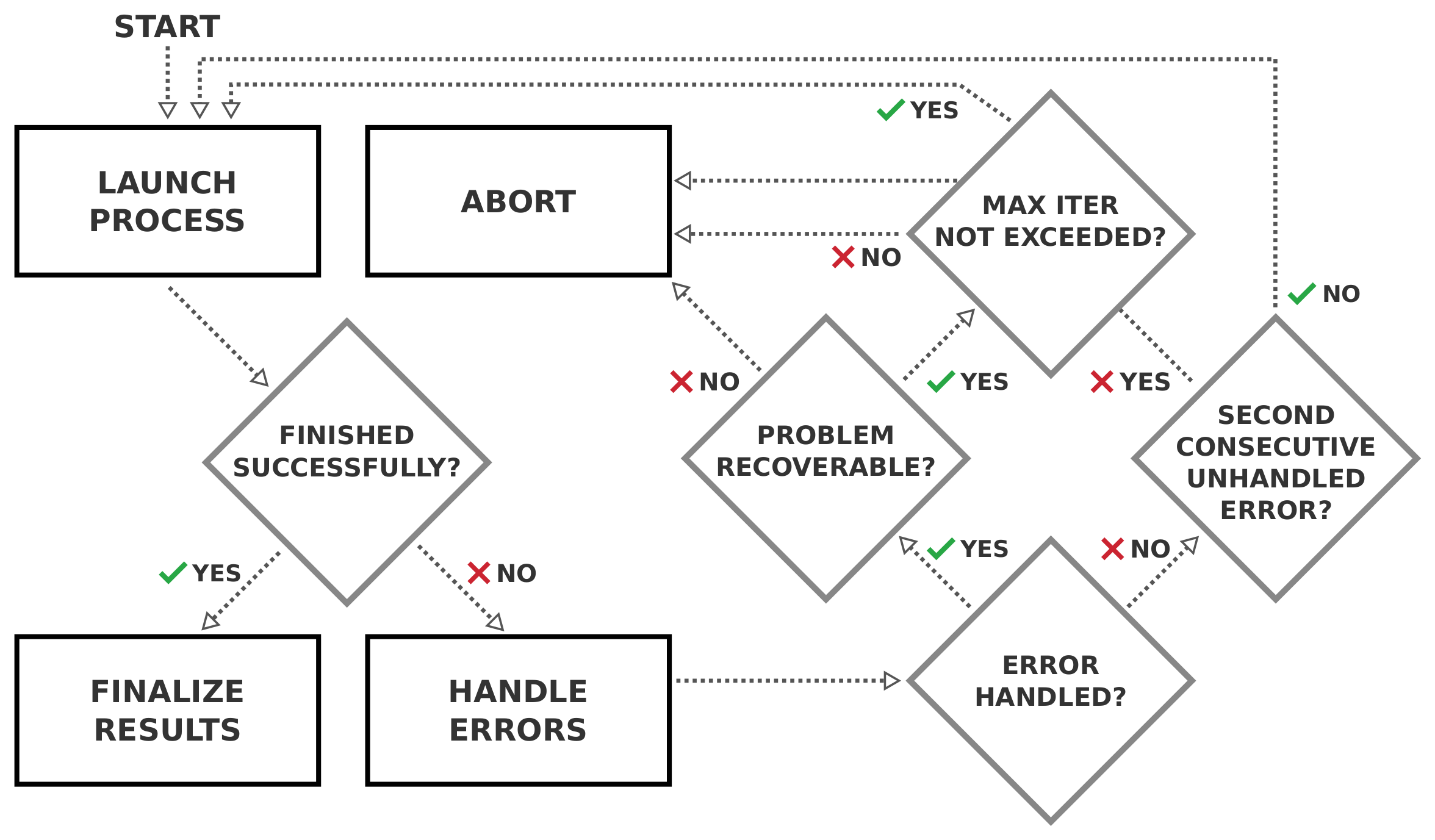
图 7 基础工作链的改进流程图,限制了工作链尝试并成功完成计算的最大迭代次数。#
由于这是一个基础工作链的常见逻辑流程,即封装另一个 Process 并重新启动它,直到成功完成为止,因此我们将其作为 aiida-core 中的一个抽象基础类来实现。 BaseRestartWorkChain 实现了上图所示流程图的逻辑。虽然 BaseRestartWorkChain 本身是 WorkChain 的子类,但您无法启动它。原因是它是完全通用的,因此不知道应该运行哪个 Process 类。相反,要使用基础重启工作链,您应该针对要封装的进程类对其进行子类化。
编写基础重启工作链#
在本教程中,我们将演示如何为 ArithmeticAddCalculation 实现 BaseRestartWorkChain 。首先,我们将 import 相关基类并创建一个子类:
from aiida.engine import BaseRestartWorkChain
from aiida.plugins import CalculationFactory
ArithmeticAddCalculation = CalculationFactory('core.arithmetic.add')
class ArithmeticAddBaseWorkChain(BaseRestartWorkChain):
_process_class = ArithmeticAddCalculation
如您所见,我们所要做的就是为 ArithmeticAddCalculation 创建一个 BaseRestartWorkChain class, which we called ArithmeticAddBaseWorkChain, and set the _process_class 类属性的子类。后者指示工作链应启动哪种类型的进程。接下来,与所有工作链一样,我们应该 定义 它的进程规范:
from aiida import orm
from aiida.engine import while_
@classmethod
def define(cls, spec):
"""Define the process specification."""
super().define(spec)
spec.input('x', valid_type=(orm.Int, orm.Float), help='The left operand.')
spec.input('y', valid_type=(orm.Int, orm.Float), help='The right operand.')
spec.input('code', valid_type=orm.AbstractCode, help='The code to use to perform the summation.')
spec.output('sum', valid_type=(orm.Int, orm.Float), help='The sum of the left and right operand.')
spec.outline(
cls.setup,
while_(cls.should_run_process)(
cls.run_process,
cls.inspect_process,
),
cls.results,
)
我们定义的输入和输出主要由工作链将要运行的子流程决定。由于 ArithmeticAddCalculation 需要输入 x 和 y,并产生 sum 作为输出,因此我们在工作链的规范中 mirror 了这些输入和输出,否则我们将无法传递必要的输入。最后,我们定义逻辑大纲,如果仔细观察,它与 图 7 中的逻辑流程图非常相似。我们首先 设置 工作链,然后进入一个循环: 在子进程尚未成功完成且未超过最大迭代次数的情况下,我们 运行 进程的另一个实例,然后 检查*结果。 should_run_process 大纲步骤中实现了while条件。当流程成功结束或不得不放弃时,我们就会报告*结果。现在,与普通的工作链实施不同,我们**不必自己实施这些大纲步骤。 BaseRestartWorkChain 已经实现了这些步骤,所以我们不需要这样做。这就是基础重启工作链如此有用的原因,因为它让我们不必编写和重复大量的 boilerplate code 。
警告
要使工作链正常运行,必须要有这个最基本的大纲定义。如果更改逻辑、步骤名称或省略某些步骤,工作链将无法运行。不过,添加额外的大纲步骤以增加自定义功能是可以的,如果合理的话,实际上也是值得鼓励的。
谜题的最后一部分是在设置中定义工作链应将哪些输入传递给子流程。你可能会问为什么要这样做,因为我们已经在规范中定义了输入,但这些并不是唯一要传递的输入。 BaseRestartWorkChain 也定义了自己的一些输入,例如 max_iterations ,您可以在其 define() 方法中看到。为了明确子进程的输入内容,我们在上下文中将它们定义为字典,键值为 inputs 。一种方法是重复使用 setup() 方法:
def setup(self):
"""Call the `setup` of the `BaseRestartWorkChain` and then create the inputs dictionary in `self.ctx.inputs`.
This `self.ctx.inputs` dictionary will be used by the `BaseRestartWorkChain` to submit the process in the
internal loop.
"""
super().setup()
self.ctx.inputs = {'x': self.inputs.x, 'y': self.inputs.y, 'code': self.inputs.code}
请注意,如前所述, setup 步骤是任何基础重启工作链逻辑大纲的关键部分。从大纲中省略这一步会破坏工作链,但完全覆盖这一步也会破坏工作链,除非我们调用 super 。
这就是我们要编写的所有代码,以便拥有一个功能正常的工作链。现在,我们可以像启动其他工作链一样启动它, BaseRestartWorkChain 就会发挥它的魔力:
submit(ArithmeticAddBaseWorkChain, x=Int(3), y=Int(4), code=load_code('add@tutor'))
一旦工作链完成,我们就可以检查 verdi process status 等发生了什么:
$ verdi process status 1909
ArithmeticAddBaseWorkChain<1909> Finished [0] [2:results]
└── ArithmeticAddCalculation<1910> Finished [0]
可以看到,工作链启动了 ArithmeticAddCalculation 的单个实例,并成功完成,因此工作链的工作也完成了。
备注
如果工作链除外,请确保包含工作链定义的目录位于 PYTHONPATH 中。
您可以通过 PYTHONPATH 添加定义 WorkChain 的 Python 文件夹:
$ export PYTHONPATH=/path/to/workchain/directory/:$PYTHONPATH
在此之后,重新启动守护进程是**非常 important** 的做法:
$ verdi daemon restart
事实上,在更新现有工作链文件或添加新文件时, 有必要 在完成所有更改后 每次 重新启动守护进程。
公开输入和输出#
任何基本重启工作链都 需要 暴露 它所封装的子进程的输入,而且很可能 希望*对它所产生的输出也这样做,尽管后者并非必要。在上一节介绍的简单示例中,只需复制粘贴子进程 ArithmeticAddCalculation 的输入和输出端口定义就不会太麻烦。但是,一旦开始使用更多的输入来封装进程,这种做法很快就会变得繁琐,而且更 importantly 容易出错。为了防止输入和输出规范的复制粘贴, ProcessSpec 类提供了 expose_inputs() 和 expose_outputs() 方法:
@classmethod
def define(cls, spec):
"""Define the process specification."""
super().define(spec)
spec.expose_inputs(ArithmeticAddCalculation, namespace='add')
spec.expose_outputs(ArithmeticAddCalculation)
...
参见
有关公开输入和输出的更多详情,请参阅基本 Workchain usage section 。
这样就能以非常高效的方式公开封装进程类的端口规范。要高效地检索传递给进程的输入,可以使用 exposed_inputs() 方法。请注意方法名称的过去式。该方法将一个进程类和一个可选的命名空间作为参数,并将返回进程启动时传入该命名空间的输入。有了这个实用程序,我们就可以简化之前展示过的 setup 大纲步骤:
def setup(self):
"""Call the `setup` of the `BaseRestartWorkChain` and then create the inputs dictionary in `self.ctx.inputs`.
This `self.ctx.inputs` dictionary will be used by the `BaseRestartWorkChain` to submit the process in the
internal loop.
"""
super().setup()
self.ctx.inputs = self.exposed_inputs(ArithmeticAddCalculation, 'add')
这样,我们就不必手动从 self.inputs 中找出所有单独的输入,而只需调用这个方法,从而节省了大量时间和代码行数。
在提交或运行使用命名输入的工作链时(上例中为 add ),必须使用命名空间:
inputs = {
'add': {
'x': Int(3),
'y': Int(4),
'code': load_code('add@tutor')
}
}
submit(ArithmeticAddBaseWorkChain, **inputs)
重要
每次更改 ArithmeticAddBaseWorkChain 时,不要忘记用以下命令重启守护进程:
$ verdi daemon restart
自定义输出#
默认情况下, BaseRestartWorkChain 将附加上一个已完成计算作业的输出。在大多数情况下,这是正确的行为,但在某些用例中,可能需要修改附加到工作链上的输出。这可以通过重载 aiida.engine.processes.workchains.restart.BaseRestartWorkChain.get_outputs() 方法来实现。例如,如果想删除附加的特定输出,可以执行以下操作:
def get_outputs(self, node) -> Mapping[str, orm.Node]:
"""Return a mapping of the outputs that should be attached as outputs to the work chain."""
outputs = super().get_outputs(node)
outputs.pop('some_output', None)
return outputs
也可以更新上次完成的计算作业返回的输出之一的内容。在这种情况下,important 应一如既往地执行 calcfunction ,以避免丢失任何 provenance。
连接输出端#
在正常运行中, results 方法是 BaseRestartWorkChain 大纲中的最后一步。在这一步中,最后完成的计算作业的输出被 ``attached`` 到工作链本身。输出的附加由 _attach_outputs() 方法实现。如果需要在 workflow 中 results 步以外的位置附加输出,可以手动调用该方法。例如,可以在终止工作链的进程处理程序中调用该方法。在这种情况下,工作链将立即停止, results 步骤将不再被调用。
错误处理#
到目前为止,我们已经看到使用 BaseRestartWorkChain 运行子进程的工作链是多么容易建立和运行。然而,如导言所述,本练习的全部目的是让工作链能够处理 失败 的进程,但在前面的示例中,工作链却顺利完成了。
如果子进程失败,会发生什么情况?
如果输入 x and y 的计算和为负值, ArithmeticAddCalculation 将失败,退出代码为 410 ,对应于 ERROR_NEGATIVE_NUMBER 。
参见
The exit code usage section, for a more detailed explanation of exit codes.
让我们用会导致计算失败的输入来启动工作链,例如将其中一个操作数设为负数,看看会发生什么:
submit(ArithmeticAddBaseWorkChain, add={'x': Int(3), 'y': Int(-4), 'code': load_code('add@tutor')})
这一次,我们将看到工作链的发展轨迹截然不同:
$ verdi process status 1930
ArithmeticAddBaseWorkChain<1930> Finished [402] [1:while_(should_run_process)(1:inspect_process)]
├── ArithmeticAddCalculation<1931> Finished [410]
└── ArithmeticAddCalculation<1934> Finished [410]
不出所料, ArithmeticAddCalculation 这次出现了故障,结果是 410 。工作链在检查 inspect_process 中子进程的结果时发现了故障,并按照其名称和设计重新启动了计算。然而,由于输入没有改变,计算不可避免地再次失败,错误代码完全相同。不过,与第一次迭代不同的是,工作链没有再次重启,而是放弃了,并返回了退出代码 402 ,即 ERROR_SECOND_CONSECUTIVE_UNHANDLED_FAILURE 。顾名思义,工作链试图运行子进程,但连续两次都失败了,没有 处理 问题。现在显而易见的问题当然是我们究竟该如何指示基本工作链处理某些问题?
由于这些问题必然依赖于工作链将运行的子进程,因此不能由 BaseRestartWorkChain 类本身来实现,而必须由子类来实现。如果子进程失败, BaseRestartWorkChain 将在 inspect_process 步骤中调用一组 进程处理程序 。每个进程处理程序都会得到刚刚运行的子进程的 node,这样它就可以检查结果并修复发现的任何问题。要为基本重启工作链实现 ``register`` 进程处理程序,只需定义一个以 node 为单个参数的方法,并使用 process_handler() 装饰器对其进行装饰:
from aiida.engine import process_handler, ProcessHandlerReport
class ArithmeticAddBaseWorkChain(BaseRestartWorkChain):
_process_class = ArithmeticAddCalculation
...
@process_handler
def handle_negative_sum(self, node):
"""Check if the calculation failed with `ERROR_NEGATIVE_NUMBER`.
If this is the case, simply make the inputs positive by taking the absolute value.
:param node: the node of the subprocess that was ran in the current iteration.
:return: optional :class:`~aiida.engine.processes.workchains.utils.ProcessHandlerReport` instance to signal
that a problem was detected and potentially handled.
"""
if node.exit_status == ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER.status:
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport()
只要是有效的 Python 方法名,且不与基础工作链的方法重叠,方法名可以是任何名称。不过,为了提高可读性,建议方法名以 handle_ 开头。在本例中,我们要特别检查 ArithmeticAddCalculation 的特定故障模式,因此要比较 node 的 exit_status() 和进程规范的 exit_status 。如果退出代码匹配,我们就知道问题是由于和为负造成的。在本例中,要解决这个虚构的问题非常简单,只需确保输入值全部为正值即可,我们可以通过求绝对值来做到这一点。我们将新值分配到 self.ctx.inputs 中,就像在 setup 步骤中定义原始输入值一样。最后,为了表示问题已经解决,我们将返回一个 ProcessHandlerReport 的实例。这将指示工作链重新启动子进程,从上下文中获取更新后的输入。有了这个简单的补充,我们现在就可以再次启动工作链了:
$ verdi process status 1941
ArithmeticAddBaseWorkChain<1941> Finished [0] [2:results]
├── ArithmeticAddCalculation<1942> Finished [410]
└── ArithmeticAddCalculation<1947> Finished [0]
这一次,虽然第一个子进程再次出现 410 失败,但新进程处理程序被调用。它调用了 ``fixes`` 输入,当工作链使用新输入重新启动子进程时,它就成功完成了。通过这个简单的过程,您可以添加任意数量的进程处理程序,以处理工作链实现中特定子进程类型可能出现的任何潜在问题。为了使代码更加易读, process_handler() 装饰器提供了各种语法糖。您可以通过装饰器的 exit_codes 关键字参数来定义该条件,而不必在每个处理程序的开头设置一个条件,将 node 的退出状态与子进程的特定退出代码进行比较:
@process_handler(exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport()
如果定义了 exit_codes 关键字(可以是 ExitCode 的单个实例,也可以是其列表),那么只有当 node 的退出状态与这些退出代码之一相对应时,才会调用进程处理程序,否则将直接跳过。
多个进程处理程序#
由于基本重启工作链的实现通常会有一个以上的进程处理程序,因此可能需要控制它们的调用顺序。这可以通过 priority 关键字来实现:
@process_handler(priority=400, exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport()
优先级较高的进程处理程序将首先被调用。在这种情况下,除了控制处理程序的调用顺序外,您可能还希望在确定问题后停止进程处理。这可以通过将 ProcessHandler 的 do_break 参数设置为 True 来实现:
@process_handler(priority=400, exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport(do_break=True)
最后,有时检测到的问题根本无法或不应该由工作链纠正。在这种情况下,处理程序可以通过在 ProcessHandler 的 exit_code 参数上设置 ExitCode 实例,发出中止工作链的信号:
from aiida.engine import ExitCode
@process_handler(priority=400, exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
return ProcessHandlerReport(exit_code=ExitCode(450, 'Inputs lead to a negative sum but I will not correct them'))
基础重启工作链将检测到该退出代码并中止工作链,同时像往常一样在 node 上设置相应的状态和信息:
$ verdi process status 1951
ArithmeticAddBaseWorkChain<1951> Finished [450] [1:while_(should_run_process)(1:inspect_process)]
└── ArithmeticAddCalculation<1952> Finished [410]
有了这些基本工具,就可以解决广泛的用例问题,同时防止出现大量模板代码。
处理程序重写#
在不更改工作链源代码的情况下,可以更改处理程序的优先级并启用/禁用它们。处理程序的这些属性可通过工作链的 handler_overrides 输入进行控制。该输入值为 Dict node,其形式如下:
handler_overrides = Dict({
'handler_negative_sum': {
'enabled': True,
'priority': 10000
}
})
正如您所看到的,键是要影响的处理程序的名称,而值则是一个可包含两个键的字典: enabled 和 priority 。要启用或禁用处理程序,可将 enabled 分别设置为 True 或 False 。 priority 键取整数,决定处理程序的优先级。请注意, handler_overrides 的值是完全可选的,并将覆盖工作链源代码中进程处理程序装饰器配置的值。此外,这些更改只会影响接收 handler_overrides 输入的工作链实例,将启动的所有其他工作链实例将不受影响。