使用方法#
备注
本章假定读者了解 basic concept 的知识,并知道工作函数和工作链之间的区别,以及何时应使用工作函数或工作链。
AiiDA 中的 workflow 是一个 process(详见 process section ),它调用其他 workflow 和计算,并可选择 返回 数据,因此可以编码典型科学 workflow 的逻辑。目前,有两种方法可以实现 workflow process:
本节将提供如何实施这两种 workflow 类型的详细信息和最佳实践。
Work functions (工作函数)#
工作职能的概念和基本实施规则在其他地方有详细说明:
由于工作函数与计算函数一样是 process function 的子类型,因此它们的实现规则完全相同。然而,它们的预期目标和启发式方法却大相径庭。 calculation functions 是类似于 ‘calculation’ 的 processes,可以 创建 新数据,而工作函数则类似于 ‘workflow’ 的 processes,只能 返回 数据。本节将介绍工作函数的预期用途和限制。
返回数据#
之前已经说过很多次:工作函数,就像所有类似 ‘workflow’ 的 processes、return 数据一样,但 return 到底是什么意思呢?在这里,’return’ 并不是指返回值的一段 python 代码。相反,它指的是 workflow process 将一个数据 node 记录为其输出之一,这个数据 本身并没有创建 ,而是由 workflow 调用的其他 process 创建的。计算 process 负责 创建 数据 node,而 workflow 只是 返回 该数据作为其输出之一。
这正是 workfunction 函数的作用。它将一个或多个数据 node 作为输入,调用其他 processes 并将这些输入传递给其他 processes,然后有选择地返回由它调用的计算 processes 创建的部分或全部输出。如 technical section 所述,只需从函数返回 nodes 即可将输出记录为 ‘returned’ nodes。engine 将检查函数的返回值,并将输出 nodes 附加到代表工作函数的 node 上。为了验证输出 node 事实上不是 ‘created’,engine 将检查 node 是否已存储。因此,请务必**不要存储自己创建的 node,否则 engine 将引发异常,如下例所示:
from aiida.engine import workfunction
from aiida.orm import Int
@workfunction
def illegal_workfunction(x, y):
return Int(x + y)
result = illegal_workfunction(Int(1), Int(2))
由于返回的 node 是新创建的 node,且未存储,engine 将引发以下异常:
ValueError: Workflow<illegal_workfunction> tried returning an unstored `Data` node.
This likely means new `Data` is being created inside the workflow.
In order to preserve data provenance, use a `calcfunction` to create this node and return its output from the workflow
请注意,您当然可以自己在 node 上调用 store 来规避这一检查,但这并不重要。使用 workfunction 调用 ‘create’ 新数据的问题在于,provenance 会丢失。为了说明这个问题,让我们回到实现 workflow 将两个整数相加并将结果与第三个整数相乘的简单问题。如 图 13 所示, correct implementation 的结果是 provenance graph,它清楚地捕捉到加法和乘法作为单独计算 nodes 的结果。为了说明如果不调用计算函数来执行计算,而是直接在工作函数中执行计算并返回结果,请看下面的示例:
from aiida.engine import workfunction
from aiida.orm import Int
@workfunction
def add_and_multiply(x, y, z):
sum = Int(x + y)
product = Int(sum * z)
return product.store()
result = add_and_multiply(Int(1), Int(2), Int(3))
警告
对于文档阅览者来说:这是一个明确的示例,说明 如何不使用 工作函数。 correct implementation 调用计算函数来执行计算
请注意,在本示例实现中,我们必须在返回结果之前明确调用 store ,以避免 engine 引发异常。结果 provenance 将如下所示:
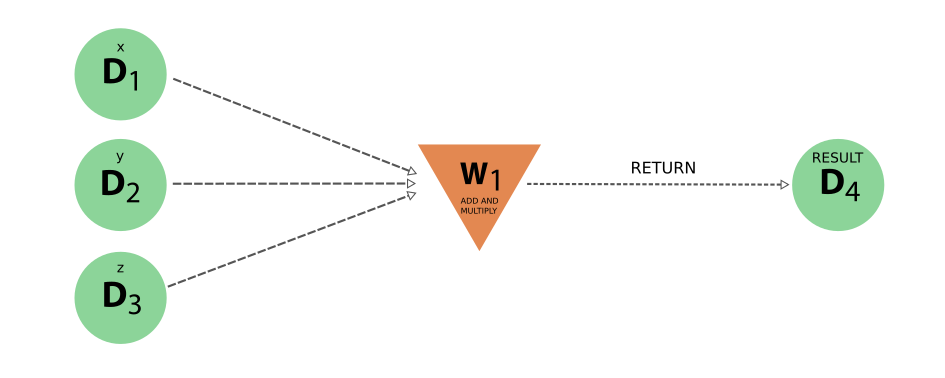
图 19 由不正确的工作函数实现生成的 provenance。请注意,加法和乘法没有明确表示,而是隐含在 workflow node 中。此外,结果 node 没有 ‘create’ 链接,因为工作函数不能创建新数据。#
然而,看看生成的 provenance 就知道为什么我们不应该这样做了。这个错误的实现丢失了 provenance,因为它没有明确表示加法和乘法,而且 result node 没有 create 链接,这意味着如果只跟踪数据 provenance,它就像凭空出现的一样!与之相比,图 13 中的 provenance graph 是由正确使用计算函数进行计算的解决方案生成的。在这个微不足道的例子中,我们可能会认为这种信息损失并不严重,因为 workflow node 已经隐含了这种损失。但是,半途而废的解决方案可能会使问题更加明显,下面的代码片段就证明了这一点:加法是通过调用计算函数正确完成的,但最终乘积仍由工作函数本身执行:
from aiida.engine import calcfunction, workfunction
from aiida.orm import Int
@calcfunction
def add(x, y):
return Int(x + y)
@workfunction
def add_and_multiply(x, y, z):
sum = add(x, y)
product = Int(sum * z)
return product.store()
result = add_and_multiply(Int(1), Int(2), Int(3))
警告
对于文档阅览者来说:这是一个明确的示例,说明 如何不使用 工作函数。 correct implementation 调用计算函数来执行计算
这一次,加法运算由计算函数正确执行,但其结果被工作函数本身乘以并返回。请注意,必须再次在 product 上明确调用 store 以避免 engine 抛出 ValueError ,这只是本例 的目的,实际操作中不应这样做 。由此产生的 provenance 将如下所示:
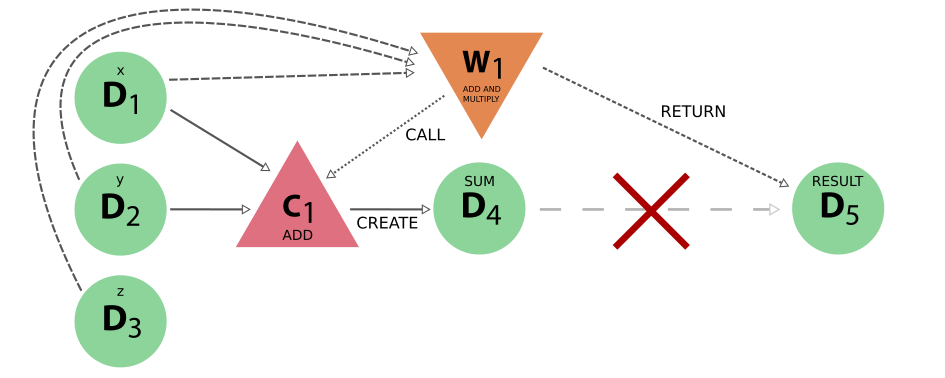
图 20 由错误的工作函数实现产生的 provenance,该函数只使用计算函数进行加法运算,却自行执行乘法运算。红叉表示中间和 D4 与最终结果 D5 之间没有实际联系,尽管后者实际上来自前者。#
从生成的 provenance 中可以看出,虽然由于工作函数调用了计算函数,加法被明确地表示出来,但和与最终结果之间没有任何联系。也就是说,和 D4 与最终结果 D5 之间没有直接联系,如红叉所示,尽管我们知道最终答案是基于中间和。这是工作函数 ‘creating’ 新数据的直接原因,并说明了这样做是如何丢失数据创建的 provenance 的。
退出代码#
要终止工作函数的执行并将其标记为失败,只需返回一个 exit code 。 ExitCode 类是用一个整数来表示所需的退出状态和一个可选的消息。当返回这样一个退出代码时,engine 将把工作函数的 node 标记为 Finished ,并把退出状态和消息设置为退出代码的值。请看下面的示例:
@workfunction
def exiting_workfunction():
from aiida.engine import ExitCode
return ExitCode(418, 'I am a teapot')
一旦返回退出代码,工作函数的执行将立即终止,退出状态和信息将分别设置为 418 和 I am a teapot 。由于没有输出 node 返回, WorkFunctionNode node 将没有输出,函数调用返回的值将是一个空字典。
Work chains (Work chains)#
The basic concept of the work chain has been explained elsewhere.
This section will provide details on how a work chain can and should be implemented.
A work chain is implemented by the WorkChain class.
Since it is a sub class of the Process class, it shares all its properties.
It will be very valuable to have read the section on working with generic processes before continuing, because all the concepts explained there will apply also to work chains.
让我们继续看 concept of workchains 章节中的示例,我们将两个整数相加,然后将结果与第三个整数相乘。我们在代码片段中提供了一个非常简单的实现方法,执行后生成的 provenance graph 如 图 17 所示。为方便起见,我们在此再次复制该代码片段:
from aiida.engine import WorkChain, calcfunction
from aiida.orm import Int
@calcfunction
def add(x, y):
return Int(x + y)
@calcfunction
def multiply(x, y):
return Int(x * y)
class AddAndMultiplyWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('x')
spec.input('y')
spec.input('z')
spec.outline(
cls.add,
cls.multiply,
cls.results,
)
spec.output('result')
def add(self):
self.ctx.sum = add(self.inputs.x, self.inputs.y)
def multiply(self):
self.ctx.product = multiply(self.ctx.sum, self.inputs.z)
def results(self):
self.out('result', self.ctx.product)
现在,我们将逐步介绍实施过程,并更详细地介绍界面和最佳做法。
定义#
要实现新的工作链,只需创建一个子类 WorkChain 的新类。你可以给这个新类起任何有效的 python 类名,但惯例是让它以 WorkChain 结尾,这样就能立即明确它引用了什么。创建新的工作链类后,首先要实现的也是最重要的 important 方法是 define() 方法。这是一个类方法,允许开发人员定义工作链的特征,例如它接受哪些输入、可以产生哪些输出、可以返回哪些潜在的退出代码以及完成所有这些工作的逻辑大纲。
要实现 define 方法,必须从以下三行开始:
@classmethod
def define(cls, spec):
super().define(spec)
将 AddAndMultiplyWorkChain 替换为工作链的实际名称。 @classmethod 修饰符表明该方法是类方法 [1] 而不是实例方法。第二行是方法签名,并指定它将接收类本身 cls 和 ProcessSpec 的实例 spec 。我们将用这个对象来定义工作链的输入、输出和其他相关属性。第三行也是最后一行非常重要,因为它将调用父类(这里是 WorkChain 类)的 define 方法。
警告
如果您忘记在 define 方法中调用 super ,您的工作链就会彻底失败!
输入和输出#
完成这些手续后,就可以开始通过 spec 定义工作链的有趣属性了。在示例中,你可以看到方法 input() 是如何用于定义多个输入端口的,这些端口准确记录了工作链期望的输入。同样, output() 也被调用来指示工作链将产生一个标签为 result 的输出。这两种端口创建方法支持更多的功能,如添加帮助字符串、验证等,所有这些将在 ports and port namespace 章节中详细介绍。
概要#
大纲使工作链有别于其他 processes。它是一种定义高级逻辑的方法,用于编码工作链所需的 workflow。大纲是通过 outline() 在 define 方法中定义的。工作链将执行一系列指令,每条指令都作为工作链类的一个方法来实现。在上面的简单示例中,大纲由三条简单指令组成:8e726e8d、 multiply 、B190f140。由于这些指令是作为实例方法实现的,因此在前缀中使用 cls. 表示它们实际上是工作链类的方法。出于同样的原因,它们的实现应将 self 作为唯一参数,如示例代码段所示。
这个简单示例中的大纲并不特别有趣,因为它由三条按顺序执行的简单指令组成。不过,大纲还支持各种逻辑结构,如 while-loop、条件和返回语句。与往常一样,说明这些结构的最佳方法是举例说明。工作链大纲目前可用的逻辑结构有
if、elif、elsewhilereturn
为了将这些结构体与 python 内置程序区分开来,它们的后缀是下划线,如 while_ 。要在工作链设计中使用这些结构体,必须先将它们添加到 import:
from aiida.engine import if_, while_, return_
下面的示例展示了如何使用这些逻辑结构定义工作链的大纲:
spec.outline(
cls.intialize_to_zero,
while_(cls.n_is_less_than_hundred)(
if_(cls.n_is_multitple_of_three)(
cls.report_fizz,
).elif_(cls.n_is_multiple_of_five)(
cls.report_buzz,
).elif_(cls.n_is_multiple_of_three_and_five)(
cls.report_fizz_buzz,
).else_(
cls.report_n,
)
),
cls.increment_n_by_one,
)
这是众所周知的 FizzBuzz [2] 问题的一个实现(而且是一个极其拙劣的实现)。其原理是,程序应该依次打印从 0 到某个极限值的数字,但如果数字是 3 的倍数,则打印 Fizz ;如果是 5 的倍数,则打印 Buzz ;如果是两者的倍数,则打印 FizzBuzz 。请注意,这些语法与普通的 python 语法非常相似。例如,条件中使用的方法( while_ 和 if_ 结构的括号之间)应返回布尔值;条件成立时返回 True ,否则返回 False 。大纲步骤本身的实际执行现在变得微不足道:
def initialize_to_zero(self):
self.ctx.n = 0
def n_is_less_than_hundred(self):
return self.ctx.n < 100
def n_is_multiple_of_three(self):
return self.ctx.n % 3 == 0
def n_is_multiple_of_five(self):
return self.ctx.n % 5 == 0
def n_is_multiple_of_three_and_five(self):
return self.ctx.n % 3 == 0 and self.ctx.n % 5 == 0
def increment_n_by_one(self):
self.ctx.n += 1
本例旨在说明,对于设计良好的大纲,用户只需查看大纲,就能很好地了解工作链的 工作内容和 工作方式。用户不需要查看大纲步骤的执行情况,因为大纲本身已经包含了所有 important 信息。由于工作链的目标应该是执行一项非常明确的任务,因此大纲的目标是以清晰、简短但不过于简洁的方式捕获实现该目标所需的逻辑。大纲支持各种逻辑流程结构,如条件和 while 循环,因此应尽可能在大纲中而不是在大纲函数的正文中表达这些逻辑。不过,也可以过分夸张,在大纲中加入过于精细的逻辑块,导致大纲变得臃肿难懂。
在设计大纲时,一个好的经验法则如下:在开始设计工作链之前,要非常明确地定义工作链应该执行的任务。目标明确后,绘制 schematic 方框图,将必要的步骤和逻辑决策连接起来,以完成该目标。将得到的流程图以一对一的方式转换成大纲,往往能得到非常合理的设计大纲。
退出代码#
除了输入、输出和大纲之外,工作链还有一个属性是通过其 process 规范指定的。任何工作链都可能有一种到多种失效模式,这些模式由 exit codes 建模。工作链可以随时停止,只需从大纲方法返回一个退出代码即可。要检索规范中定义的退出代码,可以使用 exit_codes() 属性。该属性会返回一个属性字典,其中的退出代码标签会映射到相应的退出代码。例如,使用以下 process 规范:
spec = ProcessSpec()
spec.exit_code(418, 'ERROR_I_AM_A_TEAPOT', 'the process had an identity crisis')
要了解如何使用退出代码优雅地终止工作链的执行,请参阅 中止和退出代码 部分。
启动工作链#
启动工作链的规则与任何其他 process 的规则相同,详见 this section 。除了这些基本规则外,向守护进程提交工作链还有一个特殊之处。在向守护进程提交 WorkChain 或任何其他 process 时,您需要确保守护进程能在需要加载该类时找到它。通过插件系统以指定的 entry point 注册类是确保守护进程能够找到它的一种方法。不过,如果您只是有一个测试类,而不想费力为其创建 entry point,则应确保您定义类的模块位于 python 路径中。此外,请确保工作链定义 不在您提交 的同一文件中,否则 engine 将无法加载它。
背景#
在导言部分介绍的最简单的工作链示例中,我们已经看到上下文是如何在工作链执行过程中用于持久化信息并在大纲步骤之间传递信息的。上下文本质上是一个数据容器,与可容纳各种数据的字典非常相似。engine 将确保其内容在步骤之间以及守护进程关闭或重启时得到保存和持久化。下面是一个微不足道的例子:
def step_one(self):
self.ctx.some_variable = 'store me in the context'
def step_two(self):
assert self.ctx.some_variable == 'store me in the context'
在 step_one 大纲步骤中,我们在上下文中存储了字符串 'store me in the context' ,它的地址为 self.ctx ,键值为 some_variable 。请注意,您可以使用任何可以作为普通 python 字典有效键的东西作为键。在第二个大纲步骤 step_two 中,我们可以通过检查存储在上下文 self.ctx.some_variable 中的值来验证字符串是否被成功持久化。
警告
存储在上下文中的任何数据***必须是可序列化的。
这只是一个介绍上下文概念的简单示例,但它确实是工作链中更重要的 important 部分之一。如果要在工作链中提交计算或另一个工作链,上下文就变得至关重要。如何实现这一点,我们将在下一节中介绍。
提交子 processes#
WorkChain 的主要任务之一是启动其他 processes,如 CalcJob 或另一个 WorkChain 。如何提交 processes 已在 another section 中说明,可通过使用 submit() 发射功能完成。但是,从工作链中提交子 process 时, 不应使用该功能 。相反, Process 类提供了自己的 submit() 方法。如果这样做,您将遇到异常:
InvalidOperation: 'Cannot use top-level `submit` from within another process, use `self.submit` instead'
您唯一需要做的改动就是将顶层的 submit 方法替换为 process 类的内置方法:
def submit_sub_process(self)
node = self.submit(SomeProcess, **inputs) # Here we use `self.submit` and not `submit` from `aiida.engine`
return ToContext(sub_process=node)
self.submit 方法的界面与全局 aiida.engine.launch.submit 启动程序完全相同。调用 submit 方法时,会创建 process 并提交给守护进程,但此时尚未完成。因此, submit 调用返回的值并不是提交的 process 的结果,而是 process node,它代表了 process 在 provenance graph 中的执行情况,并充当了 未来 的角色。我们需要以某种方式告诉工作链,它应该等待子 process 执行完毕并解决未来问题后再继续工作。为此,必须将控制权交还给 engine,当 process 完成后,engine 就可以调用大纲中的下一步,我们就可以分析结果了。上面的代码段已经表明,这是通过返回 ToContext 类的实例来实现的。
背景#
为了存储提交的 process 的未来,我们可以在上下文中使用一个特殊结构体来存储它,该结构体将告诉 engine,在继续工作链之前,它应该等待该 process 完成。为说明其工作原理,请看下面的最小示例:
from aiida.engine import ToContext, WorkChain
class SomeWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.outline(
cls.submit_workchain,
cls.inspect_workchain,
)
def submit_workchain(self):
future = self.submit(SomeWorkChain)
return ToContext(workchain=future)
def inspect_workchain(self):
assert self.ctx.workchain.is_finished_ok
如上一节所述,为要提交的给定 process 调用 self.submit 将返回一个 future。要将这个未来添加到上下文中,我们不能像在 context section 中解释的那样直接访问上下文,而是需要使用类 ToContext 。该类必须从 aiida.engine 模块中 import。要将 future 添加到上下文中,只需构造一个 ToContext 的实例,将 future 作为关键字参数传递,然后从大纲步骤返回即可。本例中使用的关键字 workchain 将是用于在执行结束后在上下文中存储 node 的关键字。返回 ToContext 实例向 engine 发出信号,表明它必须等待其中包含的期货执行完毕,将其 node 保存在上下文中指定的键下,然后继续执行大纲中的下一步。在本例中,这就是 inspect_workchain 方法。至此,我们可以确定 process(本例中的工作链)已经结束执行,虽然不一定成功,但我们可以继续工作链的逻辑。
警告
仅使用 ToContext 结构不足以告诉 engine 应该等待子 process 完成。大纲中***需要至少有另一个步骤来跟随添加可等待程序的步骤。如果根据大纲,没有其他步骤,engine 就会认为工作链已经完成,因此不会等待子 process 完成。可以这样想:如果连一个步骤都没有,那么工作链也无法对子 process 的结果做任何处理,因此也就没有等待的必要了。
有时,我们希望同时启动多个 processes 并行运行。如果使用上述机制,这将无法实现,因为在提交单个 process 并返回 ToContext 实例后,工作链必须等待 process 完成后才能继续。为了解决这个问题,还有一种方法可以在上下文中添加期货:
from aiida.engine import WorkChain
class SomeWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.outline(
cls.submit_workchains,
cls.inspect_workchains,
)
def submit_workchains(self):
for i in range(3):
future = self.submit(SomeWorkChain)
key = f'workchain_{i}'
self.to_context(**{key: future})
def inspect_workchains(self):
for i in range(3):
key = f'workchain_{i}'
assert self.ctx[key].is_finished_ok
在这里,我们在一个大纲步骤中的 for 循环中提交了三个工作链,但我们并没有返回 ToContext 的实例,而是调用了 to_context() 方法。该方法的语法与 ToContext 类完全相同,只是不需要返回其值,因此我们可以在一个大纲步骤中多次调用该方法。其内部功能也与 ToContext 类相同。在 submit_workchains 大纲步骤结束时,engine 将找到通过调用 to_context 添加的期货,并等待它们全部完成。好在这三个子工作链可以并行运行,一旦全部完成,父工作链将进入下一步,即 inspect_workchains 。在那里,我们可以在上下文中找到工作链的 nodes ,该关键字在上一步的 to_context 调用中被用作关键字参数。
由于我们不希望 to_context 的后续调用覆盖之前的未来调用,因此必须创建唯一的键来存储它们。在本例中,我们选择使用 for 循环的索引。名称没有任何意义,只是为了保证键名的唯一性。这种模式经常出现在需要并行启动多个工作链或计算的情况下,因此必须使用唯一的名称。然而,从本质上讲,您实际上只是在创建一个列表,最好是能够在上下文中创建一个列表,并在提交时简单地将未来附加到该列表中。下一节将解释如何实现这一点。
追加#
如果要将已提交的子 process 的未来添加到上下文中,但要将其追加到列表中,而不是分配给某个键,则可以使用 append_() 函数。请看上一节的示例,现在我们将使用 append_ 函数:
from aiida.engine import WorkChain, append_
class SomeWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.outline(
cls.submit_workchains,
cls.inspect_workchains,
)
def submit_workchains(self):
for i in range(3):
future = self.submit(SomeWorkChain)
self.to_context(workchains=append_(future))
def inspect_workchains(self):
for workchain in self.ctx.workchains:
assert workchain.is_finished_ok
请注意,在 submit_workchains 步骤中,我们不再需要根据索引生成唯一键,而只需将 future 包入 append_ 函数,并将其赋值给通用键 workchains 。engine 将看到 append_ 函数,它不会将与 future 对应的 node 分配给键 workchains ,而是将其附加到存储在该键下的列表中。如果列表尚不存在,则会自动创建。现在, self.ctx.workchains 包含一个已完成工作链 node 的列表,顺序与插入时相同,因此在 inspect_workchains 步骤中,我们只需遍历该列表即可访问所有工作链。请注意, append_ 的使用不仅限于 to_context 方法。您还可以使用与 ToContext 完全相同的方法,在多个大纲步骤中将 process 附加到上下文中的列表。
嵌套上下文键#
为简化上下文的组织结构,键可能包含点 .,从而在 process 中透明地创建命名空间。例如,将以下内容与上述并行提交示例进行比较:
from aiida.engine import WorkChain
class SomeWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.outline(
cls.submit_workchains,
cls.inspect_workchains,
)
def submit_workchains(self):
for i in range(3):
future = self.submit(SomeWorkChain)
key = f'workchains.sub{i}'
self.to_context(**{key: future})
def inspect_workchains(self):
for key, workchain in self.ctx.workchains.items():
assert workchain.is_finished_ok
这样就可以创建直观分组且易于访问的子计算或工作链结构。
报告#
在 WorkChain 执行过程中,我们可能希望让用户了解其进度和发生的情况。为此, WorkChain 实现了 report() 方法,该方法的功能类似于日志记录器。它只接受一个参数,即需要报告的信息字符串:
def submit_calculation(self):
self.report('here we will submit a calculation')
这将把消息发送到 python 的内部日志记录器,使其被默认的 AiiDA 日志记录器接收,但同时也会触发数据库日志处理程序,将消息存储到数据库中,并将其链接到工作链的 node。这样, verdi process report 命令就可以检索所有使用 report 方法触发的特定 process 消息。请注意,报告方法除了记录工作链的 pk 外,还会自动记录工作链名称和触发报告消息的大纲步骤名称。这些信息将显示在 verdi process report 的输出中,因此您无需在信息中明确引用工作链名称、大纲步骤名称或日期和时间。
import 需要注意的是,报告系统是一种日志记录形式,因此只能由人工读取。也就是说,报告系统不是通过解析日志信息来传递信息的。
中止和退出代码#
在每个大纲步骤结束时,engine 将检查返回值。如果检测到非零整数值,engine 将把它解释为退出代码,并停止执行工作链,同时将其 process 状态设置为 Finished 。此外,整数返回值将被设置为工作链的 exit_status ,与 Finished process 状态相结合,表示工作链被认为是 Failed ,如 process state 部分所述。这一点非常有用,因为它允许 workflow 设计人员轻松退出工作链,并使用返回值以编程方式说明工作链停止的原因。
我们假设您已经阅读了 section on how to define exit codes 至 process 工作链规范。请看下面的工作链示例,它定义了这样一个退出代码:
spec.exit_code(400, 'ERROR_CALCULATION_FAILED', 'the child calculation did not finish successfully')
现在设想一下,我们在大纲中启动计算,并在下一步检查计算是否成功完成。如果计算没有成功完成,下面的代码段展示了如何获取相应的退出代码,并通过返回退出代码来终止 WorkChain :
def submit_calculation(self):
inputs = {'code': code}
future = self.submit(SomeCalcJob, **inputs)
return ToContext(calculation=future)
def inspect_calculation(self):
if not self.ctx.calculation.is_finished_ok:
self.report('the calculation did not finish successfully, there is nothing we can do')
return self.exit_codes.ERROR_CALCULATION_FAILED
self.report('the calculation finished successfully')
在 inspect_calculation 大纲中,我们将检索上一步中提交并添加到上下文中的计算,并通过属性 is_finished_ok 检查计算是否成功完成。如果返回 False ,在本例中我们只需触发一条报告消息,并返回与标签 ERROR_CALCULATION_FAILED 相对应的退出代码。请注意,可以通过 WorkChain 属性 exit_codes 获取具体的退出代码。这将返回为该 WorkChain 定义的退出代码集合,然后可以通过将其作为属性访问来检索任何特定的退出代码。返回的退出代码将是 ExitCode 类的实例,它将导致工作链中止,并在 node 上设置规格中定义的 exit_status 和 exit_message 。
备注
self.exit_codes.ERROR_CALCULATION_FAILED 符号只是语法糖,用于检索规范中定义的带有该错误标签的 ExitCode 实例。直接构建自己的 ExitCode 并从大纲步骤中返回,在中止工作链执行和设置退出状态和消息方面具有完全相同的效果。不过,我们强烈建议通过规范定义退出代码,并通过 self.exit_codes 集合获取它,因为这样工作链的调用者就可以很容易地通过规范获取它。
ExitCode 的 message 属性也可以是包含占位符的字符串。当退出代码的信息足以通用于各种情况,但用户希望将退出信息参数化时,这种方法就非常有用。要将退出代码的模板信息具体化,只需调用 format() 方法并将参数作为关键字参数传递即可:
exit_code_template = ExitCode(450, 'the parameter {parameter} is invalid.')
exit_code_concrete = exit_code_template.format(parameter='some_specific_key')
这一概念也可应用于 process 的范围内。在 process 规范中,我们可以声明一个通用退出代码,其确切信息取决于一个或多个参数:
spec.exit_code(450, 'ERROR_INVALID_PARAMETER, 'the parameter {parameter} is invalid.')
通过 WorkChain 的 self.exit_codes 集合,可以方便地对该通用型进行如下定制:
def inspect_calculation(self):
return self.exit_codes.ERROR_INVALID_PARAMETER.format(parameter='some_specific_key')
这与之前的示例没有什么不同,因为 self.exit_codes.ERROR_INVALID_PARAMETER 只是返回一个 ExitCode 的实例,然后我们在该实例上调用 format 并加上替换参数。
总之,使用退出代码中止工作链执行的最大好处是,退出状态现在可以通过编程方式使用,例如由父工作链使用。想象一下,父工作链提交了这个工作链。终止执行后,父工作链想知道子工作链的情况。如 report 章节所述,不应使用工作链的报告信息。而退出状态则是一个完美的方法。父工作链可以通过 exit_status 属性轻松请求子工作链的退出状态,并根据其值决定如何继续。
模块化 workflow 设计#
在创建复杂的 workflow 时,最好将其拆分成较小的模块化部分。在最底层,每个 workflow 应准确执行一项任务。然后,这些 workflow 可以通过 ``parent`` workflow 封装在一起,创建一个更大的逻辑单元。
为了使这种方法易于管理,需要尽可能简单地将多个 workflow 粘合到一个更大的父 workflow 中。AiiDA 提供的简化工具之一就是 暴露 另一个 process 类的端口。这可以是另一个 WorkChain 实现、 CalcJob 甚至 process function( calcfunction 或 workfunction )。
公开输入和输出#
请看下面的工作链示例,它只是简单地接收一些输入,然后将它们作为输出再次返回:
from aiida.engine import WorkChain
from aiida.orm import Bool, Float, Int
class ChildWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('a', valid_type=Int)
spec.input('b', valid_type=Float)
spec.input('c', valid_type=Bool)
spec.outline(cls.do_run)
spec.output('d', valid_type=Int)
spec.output('e', valid_type=Float)
spec.output('f', valid_type=Bool)
def do_run(self):
self.out('d', self.inputs.a)
self.out('e', self.inputs.b)
self.out('f', self.inputs.c)
作为第一个例子,我们将实现一个薄包装器 workflow,它只需将输入转发到 ChildWorkChain ,并将子节点的输出转发到它的输出端:
from aiida.engine import ToContext, WorkChain
from child import ChildWorkChain
class SimpleParentWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.expose_inputs(ChildWorkChain)
spec.expose_outputs(ChildWorkChain)
spec.outline(cls.run_child, cls.finalize)
def run_child(self):
child = self.submit(ChildWorkChain, **self.exposed_inputs(ChildWorkChain))
return ToContext(child=child)
def finalize(self):
self.out_many(self.exposed_outputs(self.ctx.child, ChildWorkChain))
在这个简单父工作链的 define 方法中,我们使用了 expose_inputs() 和 expose_outputs() 。这将在父工作链中创建相应的输入和输出端口。此外,AiiDA 还会记住特定工作链类的输入和输出。这将在调用 run_child 方法中的子工作链时使用。 exposed_inputs() 方法会返回一个字典,其中包含父类接收到的子类暴露的输入,因此可以将这些输入传递给子类。最后,在 finalize 方法中,我们使用 exposed_outputs() 来检索子代暴露给父代的输出。使用 out_many() 将这些输出添加到父工作链的输出中。现在,该工作链的运行方式与子代工作链完全相同:
#!/usr/bin/env runaiida
from aiida.engine import run
from aiida.orm import Bool, Float, Int
from simple_parent import SimpleParentWorkChain
if __name__ == '__main__':
result = run(SimpleParentWorkChain, a=Int(1), b=Float(1.2), c=Bool(True))
print(result)
# {'e': 1.2, 'd': 1, 'f': True}
接下来,我们将看到如何通过使用 暴露``功能的附加功能来创建更复杂的父工作链。下面的工作链启动了两个子工作链。这两个子代共享输入 ``a,但有不同的 b 和 c。输出 e 只取自第一个子代,而 d 和 f 则取自两个子代。为了避免名称冲突,我们需要为两个子代分别创建一个 名称空间 ,用于存储不共享的输入和输出。我们的目标是 workflow 可以按如下方式调用:
#!/usr/bin/env runaiida
from aiida.engine import run
from aiida.orm import Bool, Float, Int
from complex_parent import ComplexParentWorkChain
if __name__ == '__main__':
result = run(
ComplexParentWorkChain,
a=Int(1),
child_1=dict(b=Float(1.2), c=Bool(True)),
child_2=dict(b=Float(2.3), c=Bool(False)),
)
print(result)
# {
# 'e': 1.2,
# 'child_1.d': 1, 'child_1.f': True,
# 'child_2.d': 1, 'child_2.f': False
# }
这是通过下面的 workflow 实现的。在下一节中,我们将对每个步骤进行说明。
from aiida.engine import ToContext, WorkChain
from child import ChildWorkChain
class ComplexParentWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.expose_inputs(ChildWorkChain, include=['a'])
spec.expose_inputs(ChildWorkChain, namespace='child_1', exclude=['a'])
spec.expose_inputs(ChildWorkChain, namespace='child_2', exclude=['a'])
spec.outline(cls.run_children, cls.finalize)
spec.expose_outputs(ChildWorkChain, include=['e'])
spec.expose_outputs(ChildWorkChain, namespace='child_1', exclude=['e'])
spec.expose_outputs(ChildWorkChain, namespace='child_2', exclude=['e'])
def run_children(self):
child_1_inputs = self.exposed_inputs(ChildWorkChain, namespace='child_1')
child_2_inputs = self.exposed_inputs(ChildWorkChain, namespace='child_2', agglomerate=False)
child_1 = self.submit(ChildWorkChain, **child_1_inputs)
child_2 = self.submit(ChildWorkChain, a=self.inputs.a, **child_2_inputs)
return ToContext(child_1=child_1, child_2=child_2)
def finalize(self):
self.out_many(self.exposed_outputs(self.ctx.child_1, ChildWorkChain, namespace='child_1'))
self.out_many(self.exposed_outputs(self.ctx.child_2, ChildWorkChain, namespace='child_2', agglomerate=False))
首先,我们要在顶层公开 a 输入和 e 输出。为此,我们再次使用 expose_inputs() 和 expose_outputs() ,但要加上可选关键字 include 。这指定了一个键列表,只有该列表中的输入或输出才会被暴露。因此,将 include=['a'] 传递到 expose_inputs() 后,只有输入 a 被公开。
此外,我们希望公开输入 b 和 c (输出 d 和 f),但这两个子代分别使用特定的命名空间。为此,我们将 namespace 参数传递给 expose 函数。不过,由于我们现在不应该再暴露 a (e),所以我们使用了 exclude 关键字,它指定了一个不会被暴露的键的列表。
在调用子代时,我们再次使用 exposed_inputs() 方法转发暴露的输入。由于输入 b 和 c 现在位于特定的命名空间中,我们需要将该命名空间作为附加参数传递。默认情况下, exposed_inputs() 会搜索给定命名空间的所有父命名空间以查找输入,如 child_1 的调用所示。如果多个命名空间中存在相同的输入键,则最低命名空间中的输入优先。也可以禁用这种行为,而只在传递的显式命名空间中搜索。这可以通过设置 agglomerate=False 来实现,如 child_2 的调用所示。当然,我们还需要明确传递输入 a。
最后,我们使用 exposed_outputs() 和 out_many() 将子代的输出转发到父代的输出。同样,可以使用 namespace 和 agglomerate 选项来选择 exposed_outputs() 方法返回哪些输出。
参见
有关创建 workflow 的更多实例,请参阅 how to write workflows 和 how to write error resistant workflows 章节。
脚注