概念#
在 AiiDA 中运行的任何程序都是 Process 类的实例。 Process 类包含了所有的信息和逻辑,告诉处理它的人如何运行完成它。通常,负责运行进程的是 Runner 的实例。这个实例可以是本地运行程序,也可以是运行进程的守护进程中的一个守护进程运行程序。
除了这些运行指令外,任何已执行的 Process 都需要在数据库中建立某种记录,以存储执行过程中发生的情况。例如,它需要记录具体的输入内容、报告的日志信息以及最终的输出结果。为此,每个进程都将使用 ProcessNode 类的一个子类的实例。这个 ProcessNode 类是 Node 的子类,在数据库中作为进程的执行记录,并延伸到 provenance graph 中。
理解这种分工非常重要。 Process 描述了应该如何运行,而 ProcessNode 只是在数据库中记录执行过程中实际发生的事情。需要记住的一点是,在运行过程中,我们处理的是 Process ,而当运行结束后,我们与 ProcessNode 进行交互。
Process (进程) 类型#
AiiDA 的 Process 有两种:
类Calculation型
类Workflow型
类Calculation型的 Process 有能力 创建 数据,而类似workflow的Process则协调其他进程,并有能力 返回 计算产生的数据。同样,这个区别在AiiDA中起着重要作用,理解它至关重要。因此,这些不同类型的进程也得到了 ProcessNode 类的不同子类。这些 node 类的层次结构,以及它们与 Data node 之间允许的链接类型,在 provenance implementation 文档中有详细解释。
目前, aiida-core 中有四种进程,下表显示了 provenance graph 中的 node 类别以及进程的用途。
Process (进程) 类 |
Node 类 |
用于 |
|---|---|---|
外部代码进行的计算 |
||
运行多种计算的 Workflow |
||
使用 |
||
使用 |
有关 CalcJob 或 calcfunction 概念的基本信息,请参阅 calculations concept WorkChain 和 workfunction 在 workflows concept 中进行了描述。在阅读并理解了计算和 workflow 过程的基本概念后,可分别在 calculations 和 workflows 的专门开发章节中找到有关如何实施和使用它们的详细信息。
备注
engine 不会明确执行 FunctionProcess ,但会在运行以 calcfunction() 或 workfunction() 装饰的 python 函数时动态生成 FunctionProcess 。
进程状态#
每个正在执行的 Process 类实例都有一个进程状态。该属性可显示进程的当前状态。它存储在 Process 实例本身中, plumpy 库 workflow engine 只对该值进行操作。但是, Process 实例一旦终止就会 死亡,因此进程状态也会写入计算 node 中,进程将其作为数据库记录使用,位于 process_state 属性下。进程可以处于六种状态之一:
Active |
Terminated |
|---|---|
Created |
Killed |
Running |
Excepted |
Waiting |
Finished |
左列的三个状态是 ‘active’ 状态,而右列显示的是三个 ‘terminal’ 状态。进程一旦进入结束状态,就永远不会再离开,其执行将永久终止。当进程首次创建时,它处于 Created 状态。一旦进程被运行程序拾取并处于活动状态,它就会进入 Running 状态。如果进程正在等待它调用的另一个进程结束,它将处于 Waiting 状态。如果进程处于 Killed 状态,则表示用户发出了杀死该进程的命令,或其父进程已被杀死。 Excepted 状态表示在执行过程中发生了异常,但没有被捕获,进程被意外终止。最后一个选项是 Finished 状态,它表示进程已成功执行,并且执行是有名无实的。请注意,这并不自动意味着进程的结果也可以被认为是成功的,它只是在执行过程中没有出现任何问题。
为了区分执行成功和执行失败,还有 exit status 。这是存储在进程 node 中的另一个属性,是一个可由进程设置的整数。0 (零)表示进程结果成功,非零值表示失败。各种进程使用的所有进程 node 都是 ProcessNode 的子类,其定义了用于查询进程状态和退出状态的便捷属性。
属性 |
意义 |
|---|---|
|
返回当前进程状态 |
|
返回退出状态,如果未设置则为 |
|
返回退出信息,如果未设置,则返回 |
|
如果进程是 |
|
如果进程是 |
|
如果进程是 |
|
如果进程是 |
|
如果进程为 |
|
如果进程为 |
从数据库加载计算 node 时,可以使用这些属性方法查询其状态和退出状态。
进程退出码#
上一节关于进程状态的内容表明, Finished 状态的进程并不说明结果是 ‘成功’ 还是 ‘失败’。 Finished 状态仅表示 engine 成功地将进程运行到执行结束,没有遇到异常或被杀死。为了区分 ‘成功’ 和 ‘失败’ 的进程,可以定义 ‘退出状态’。 exit status is a common concept in programming 和 是一个小整数,零表示进程结果成功,非零值表示失败。默认情况下,一个名义上终止的进程会得到一个 0 (零)的退出状态。要将进程标记为失败,可以返回一个名为 ExitCode 的元组实例,该元组允许设置整数 exit_status 和字符串消息 exit_message 。当 engine 收到来自进程的返回值 ExitCode 时,它将在 provenance graph 中代表进程的进程 node 的相应属性上设置退出状态和消息。
参见
关于如何定义和返回退出代码,请参阅 exit code usage section 。
Process 生命周期#
进程的生命周期是指从进程启动到进程到达 terminal state 的时间。
Process 与 node 的区别#
正如 introduction of this section 中所解释的,’进程’ 与在 provenance graph 中代表其执行的 node 之间有明确和 important 的区别。启动进程时,会在内存中创建一个 Process 类的实例,负责运行的运行程序会将该实例传播至完成。这个 进程``实例只存在于它所运行的 python 解释器(例如守护进程)的内存中,因此我们无法直接查看它的状态。这就是为什么进程会将其任何状态变化写入 provenance graph 中代表它的相应 node 的原因。这样,node 就像一个 '代理' 或镜像,反映内存中的进程状态。这意味着许多 ``verdi 命令(如 verdi process list )的输出实际上并不显示进程实例的状态,而是显示其最后写入状态的 node 的状态。
Process 任务#
上一节介绍了启动一个进程意味着在内存中创建一个 Process 类的实例。当进程在本地解释器中 ‘运行’ (详见 launching processes 章节)时,一旦解释器消亡,该进程实例也将随之消亡。因此,’提交’ 通常是启动进程的首选方法。当一个进程被 ‘提交’ 时, Process 的实例就会被创建,同时数据库中代表它的 node 也会被创建,然后它的状态就会被持久化(存储)在数据库中。这就是所谓的 ‘进程检查点’,更多信息请参见 will follow later 。随后,进程实例被关闭,一个 ‘继续任务’ 被发送到 RabbitMQ 的进程队列中。该任务只是一条包含进程标识符的小消息。为了从 checkpoint 中重建进程,该进程需要在守护进程环境中 import,方法是 a) 给它一个 associated entry point 或 b) 在守护进程工作者将拥有的 PYTHONPATH 中给它一个 including its module path 。
所有守护进程运行程序在启动后都会订阅进程队列,RabbitMQ 会在收到继续执行任务时将任务分配给它们,确保每个任务一次只发送给一个运行程序。接收的守护进程运行程序可从数据库中存储的检查点恢复内存中的进程实例并继续执行。一旦进程到达终端状态,守护进程运行程序就会向 RabbitMQ 确认任务已完成。在运行程序确认任务已完成之前,RabbitMQ 将认为任务未完成。如果守护进程运行程序在有机会完成进程运行之前被关闭或死亡,任务将自动被 RabbitMQ 重新排队并发送到另一个守护进程运行程序。再加上进程队列中的所有任务都会被 RabbitMQ 持久化到磁盘上,这就保证了延续任务一旦发送到 RabbitMQ,就会在某个时刻完成,同时允许机器关闭。
每个守护进程运行程序可并发运行的任务数都有上限,这意味着如果活动任务多于可用空闲时间,部分任务将保持排队状态。任务在队列中而不在任何运行程序中的进程,虽然在技术上是 ‘active’ 的,因为它们没有被终止,但实际上并没有在运行。当进程没有实际运行时,也就是没有运行程序在内存中运行时,我们无法与之交互。同样,一旦任务消失,无论是因为进程被有意终止(还是无意终止),进程都不会再继续运行。
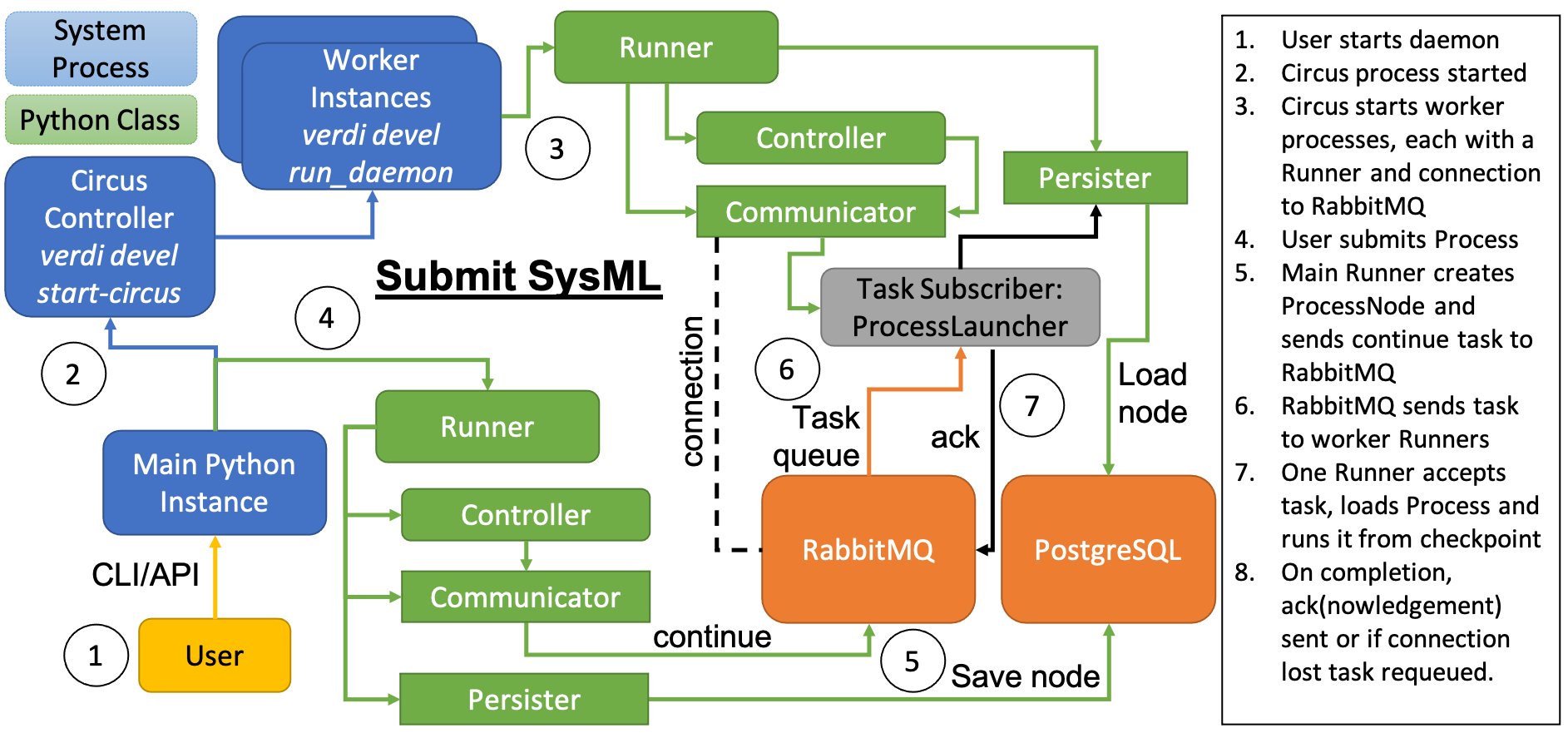
图 8 提交流程的系统建模表示法。#
流程检查点#
进程检查点是内存中 Process 实例的完整表示,可以存储在数据库中。由于它是一个完整的表示,因此 Process 实例也可以从这样的检查点完全重建。在进程的任何状态转换中,都会通过序列化进程实例并将其存储为相应进程 node 的属性来创建检查点。该机制是机器的最后一个齿轮,它与上一节中解释的 RabbitMQ 持久化进程队列一起,允许进程在其运行的机器关闭并重新启动后继续运行。
Process 密封 (sealing)#
AiiDA的一个基本规则是,一旦node被存储,它就是不可变的,这意味着它的属性不能再被改变。但这一规则对进程来说是个问题,因为要开始运行进程,必须先存储相应的进程node。但此时,其属性(如进程状态或其他可变属性)在相应进程的整个生命周期内都不能再被 engine 更改。为了克服这一限制,引入了 可更新 属性的概念。这些特殊属性允许更改 ,即使 进程 node 已存储 且 相应进程仍处于活动状态。为了标记进程已终止,甚至进程 node 上的可更新属性也被视为不可更改,node 被 密封 。密封进程 node 的行为与正常存储的 node 完全相同,因为它的**属性都是不可变的。此外,进程 node 一旦被封存,就不能再连接任何传入或传出链接。未被密封的进程 node 也不能被导出,因为它们属于仍在运行的进程。需要注意的是,密封概念不适用于数据 node,这些数据一经存储就可以导出。要确定进程 node 是否被密封,可以使用属性 is_sealed 。