概念#
AiiDA 中的 workflow 是一个 process(详见 process section ),它调用其他 workflow 和计算,并可选择 返回 数据,因此可以编码典型科学 workflow 的逻辑。目前,有两种方法可以实现 workflow process:
第一种是两种方法中最简单的一种,基本上是将一个 python 函数神奇地转换成 process。这非常适合计算量不是很大的 workflow,可以用 python 函数轻松实现。对于更复杂的 workflow,工作链是更好的选择。通过将工作链和工作函数链在一起,每个工作链和函数都可以运行其他子 process,我们就可以定义一个 workflow。为简单起见,从这里开始,我们将交替使用 workflow、工作链和工作函数这三个术语,作为*pars pro toto* 和*totum pro parte*。
在下面的章节中,我们将解释这两个概念,但不会详细介绍如何实现或运行它们。如需更详细的介绍,请参阅 work functions 和 work chains 的相关高级章节。
Work functions (工作函数)#
工作函数的实现方式与 calculation function 相同,但它们的用例却截然不同。由于工作函数是 ‘workflow-like’ process,它只能 返回 现有数据,而计算函数创建的 ‘calculation-like’ process 只能 创建 新数据。这一区别在 process 章节中有更详细的阐述,了解这一区别是非常重要的 import。
为了解释 @workfunction 的使用,我们将继续 calculation functions 的示例,因此在继续之前,请先阅读该部分。该示例展示了如何使用 @calcfunction 装饰器创建两个函数,对给定的三个整数计算前两个整数之和,然后与第三个整数相乘,同时保留 provenance。尽管计算函数确保了数据的 provenance 被保留,但谁*调用这些函数的逻辑却没有明确保留。从计算函数生成的 provenance graph 中,无法推断出这些函数是在一个脚本中连续调用的,还是先调用了 add 函数,很久之后才将输出作为 multiply 函数的输入。捕捉 processes 调用*顺序的逻辑 provenance 正是类似 workflow 的 processes(如 workfunction )的设计目的。
在下面的示例中,我们使用 @workfunction 装饰器装饰了一个名为 add_and_multiply 的函数。
from aiida.engine import calcfunction, workfunction
from aiida.orm import Int
@calcfunction
def add(x, y):
return Int(x + y)
@calcfunction
def multiply(x, y):
return Int(x * y)
@workfunction
def add_and_multiply(x, y, z):
sum = add(x, y)
product = multiply(sum, z)
return product
result = add_and_multiply(Int(1), Int(2), Int(3))
Added in version 2.1: Function argument casting
如果函数参数是一个 Python 基本类型 (即类型为 bool, dict, Enum, float, int, list 或 str 的值),它可以直接传递给函数,而不需要先用相应的 AiiDA 数据类型包装它。也就是说,你也可以以下列方式运行上面的示例:
result = add_and_multiply(1, 2, 3)
而 AiiDA 会识别出参数的类型是 int`,并自动用 ``Int node 包起来。
我们不在脚本中直接调用计算函数,而是调用 work 函数,然后连续调用计算函数,将第一个函数的中间结果传递给第二个函数。如果我们查看这个示例生成的 provenance graph,就会看到类似下面的内容:
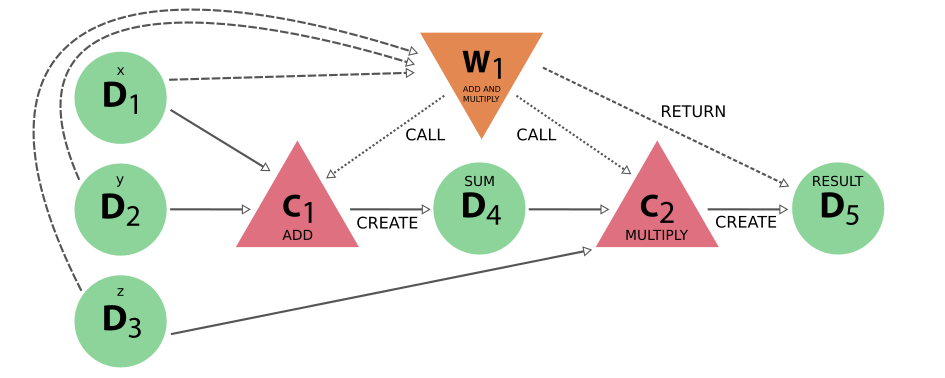
图 13 工作函数示例生成的完整 provenance 代码#
很明显,这个 provenance graph 包含的信息要比计算功能示例中的信息多得多。这些信息实际上是否必要或有用取决于具体情况,完全由用户决定,但也有很大的好处。 provenance graph implementation 将类似计算的 processes 和类似 workflow 的 processes 严格区分开来,并允许它们之间存在不同的联系,乍一看,新用户可能会觉得这有点过分。然而,由于增加了代表逻辑 provenance 的并行但不同的 workflow 层,人们可以忽略计算的所有细节。下面的 provenance graph 就证明了这一点,除了只显示数据和 workflow node 之外,它与前面的 provenance graph 完全相同:
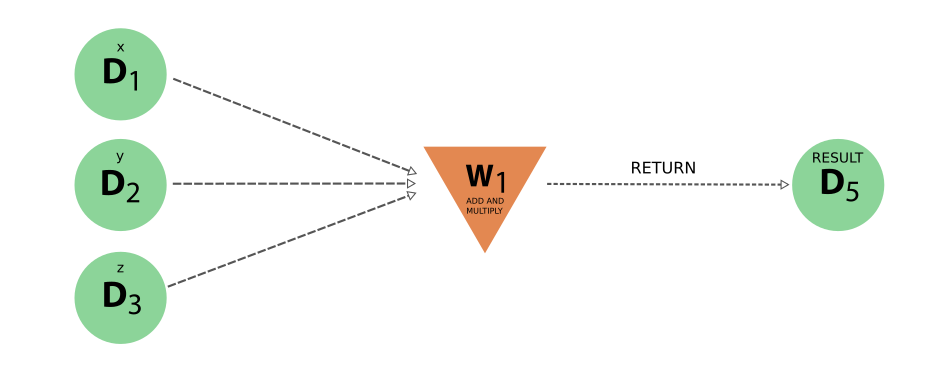
图 14 工作函数示例生成的 ‘logical’ provenance 只显示 workflow 和数据 node 及其链接#
有了这种简化的表示方法,原始输入如何导致最终结果的全貌就会一目了然。相反,实际数据 provenance 并没有丢失。在下图中,所有的 workflow node 都被省略了,我们最终得到的是与只使用计算函数的 original example 的 图 11 中完全相同的 provenance graph。
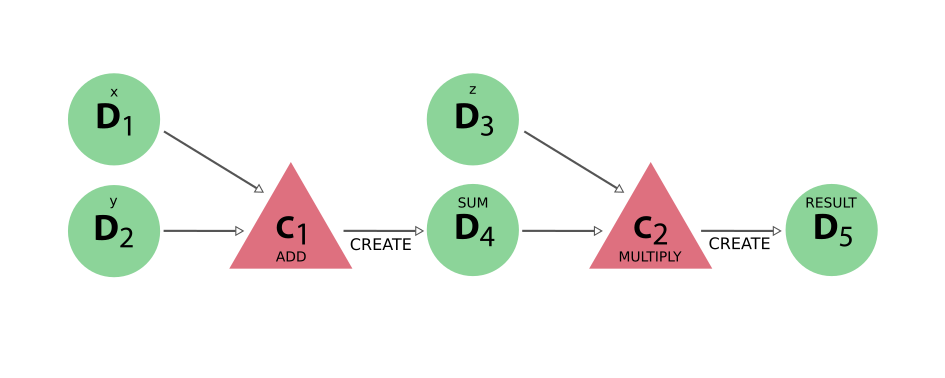
图 15 工作函数示例生成的 ‘data’ provenance 仅显示了计算和数据 nodes 及其链接#
在这个简单的例子中,选择 provenance graph 的哪个部分显然是有限的。但是,workflows 很快就会变得复杂和嵌套很深,此时,将 provenance graph 的各个部分组合在一个 node 下并以透明的方式有效地 ‘hide’ 其内部部分的能力就变得非常宝贵。
工作函数除了可以发挥协调作用外,还可以用作过滤器或选择函数。试想一下,您想编写一个 process function,接收一组输入整数 node,然后返回值最大的一个。我们不能使用 calcfunction 来实现这一功能,因为它必须返回其输入 node 中的一个,而这是明确禁止的。但是,对于 workfunction 来说,返回现有的 node 甚至是其中一个输入值都是完全没问题的。实现示例如下
from aiida.engine import workfunction
from aiida.orm import Int
@workfunction
def maximum(x, y, z):
return sorted([x, y, z])[-1]
result = maximum(Int(1), Int(2), Int(3))
上述工作函数将把输入值最高的 node x 作为输出之一。执行此选择工作函数的 provenance 将如下所示:
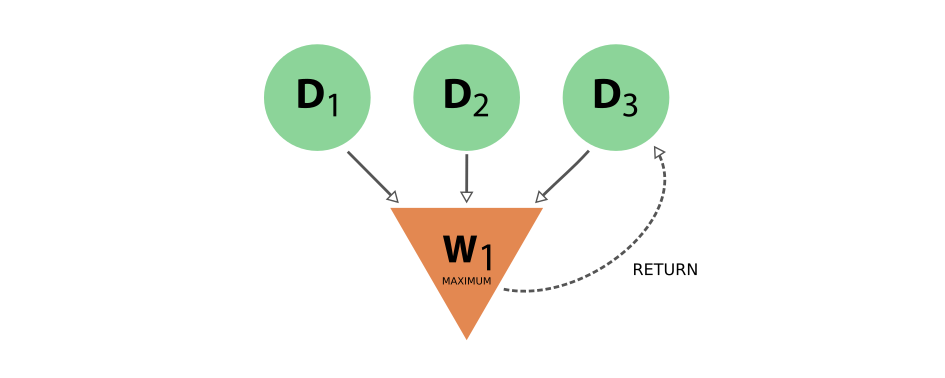
图 16 工作函数生成的 provenance 选择其输入 node 中的一个#
警告
important 需要再次说明的是,在上面给出的工作函数示例中,工作函数返回的所有 node 都是 已存储 的。也就是说,它们要么是由工作函数调用的计算函数创建的,要么是作为输入之一传入的。这并非偶然,因为工作函数***只能返回已存储的 node。如果试图返回由工作函数本身创建的 node,则会引发异常。你可以在 AiiDA 和 implementation of the provenance graph 中的各种 process types 文档中找到关于这种设计选择背后原因的更详细解释。
Work chains (Work chains)#
为什么?#
既然我们已经演示了如何轻松使用 workfunctions 来编写自动保留 provenance 的 workflow,那么现在就应该承认,工作函数并非完美无缺,也有其不足之处。在数字加法和乘法的简单示例中,执行函数的时间非常短,但想象一下,您正在执行一项成本更高的计算,例如,您要运行一个实际的 CalcJob ,该函数将提交给调度程序,并可能运行很长时间。如果在运行过程中,workflow 由于某种原因被中断,那么所有进程都会丢失。可以说,简单地将工作函数链在一起不会出现 ‘checkpoints’。
但不用担心!为了解决这个问题,AiiDA 定义了工作链的概念。顾名思义,这种结构是将 workflow 的多个逻辑步骤串联起来的一种方式,一旦这些步骤成功完成,就可以保存它们之间的进度。因此,工作链是 workflow 中涉及较昂贵和复杂计算部分的首选解决方案。为了定义工作链,AiiDA 提供了 WorkChain 类。
实现#
如果我们对上一节的简单示例问题重新执行工作函数解决方案,但这次使用工作链,那么它将看起来像下面这样:
from aiida.engine import WorkChain, calcfunction
from aiida.orm import Int
@calcfunction
def add(x, y):
return Int(x + y)
@calcfunction
def multiply(x, y):
return Int(x * y)
class AddAndMultiplyWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('x')
spec.input('y')
spec.input('z')
spec.outline(
cls.add,
cls.multiply,
cls.results,
)
spec.output('result')
def add(self):
self.ctx.sum = add(self.inputs.x, self.inputs.y)
def multiply(self):
self.ctx.product = multiply(self.ctx.sum, self.inputs.z)
def results(self):
self.out('result', self.ctx.product)
不要被本代码段中的所有代码吓倒。本示例的重点不是解释确切的语法, advanced workflows 部分将对此进行更详细的说明,而只是介绍工作链的概念。工作链的核心属性由在 define() 方法中设置的 process specification 定义。这里唯一需要注意的是,它定义了工作链的 输入、逻辑 大纲 和 输出*。大纲中的步骤作为工作链的类方法来实现。 add 步骤将通过调用 add 计算函数将前两个整数相加,并将和暂时存储在 context 中。大纲的下一步 multiply 将使用存储在第一个大纲步骤计算的上下文中的总和,并调用 multiply 计算函数来计算第三个输入整数。最后, result 步将提取上一步产生的乘积,并将其记录为工作链的输出。当我们运行这个工作链时,得到的结果是 provenance,如下所示:
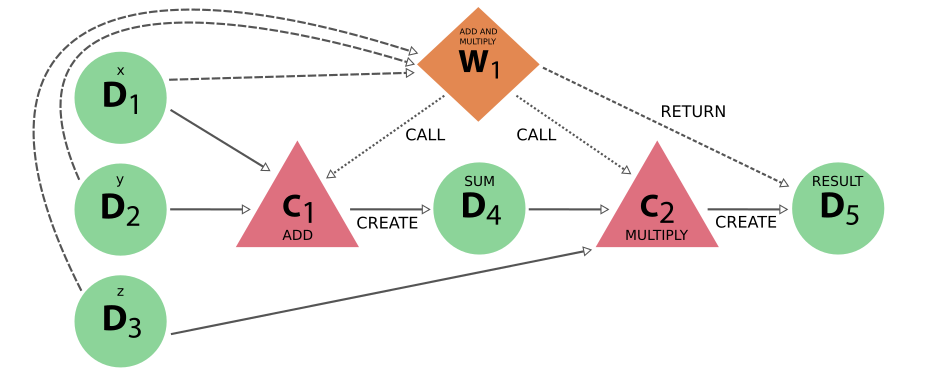
图 17 工作链示例生成的 provenance 调用计算函数来执行加法和乘法运算。#
正如您所看到的,所产生的 provenance graph 与工作函数解决方案所产生的 图 13 相同,只是 workflow node 是工作链,而不是工作函数 node。完整数据 provenance 被保留,因为通过工作链的和与积的计算由调用的 add 和 multiply 计算函数的计算 node 明确表示。
警告
使用计算函数来计算和与乘积并非偶然,而是一种有意的设计选择。由于工作链类似于 workflow processes,因此不能 创建 数据,直接在工作链大纲步骤中进行计算会导致数据丢失 provenance。
为了说明工作流 processes 不能 创建 新数据意味着什么,以及这样做如何导致数据 provenance 的丢失,让我们改变之前的实现,在工作链大纲步骤中执行求和与乘积,而不是调用计算函数。
from aiida.engine import WorkChain
from aiida.orm import Int
class AddAndMultiplyWorkChain(WorkChain):
@classmethod
def define(cls, spec):
super().define(spec)
spec.input('x')
spec.input('y')
spec.input('z')
spec.outline(
cls.add,
cls.multiply,
cls.results,
)
spec.output('result')
def add(self):
self.ctx.sum = self.inputs.x + self.inputs.y
def multiply(self):
self.ctx.product = self.ctx.sum * self.inputs.z
def results(self):
self.out('result', Int(self.ctx.product))
这样得到的 provenance 将如下所示:
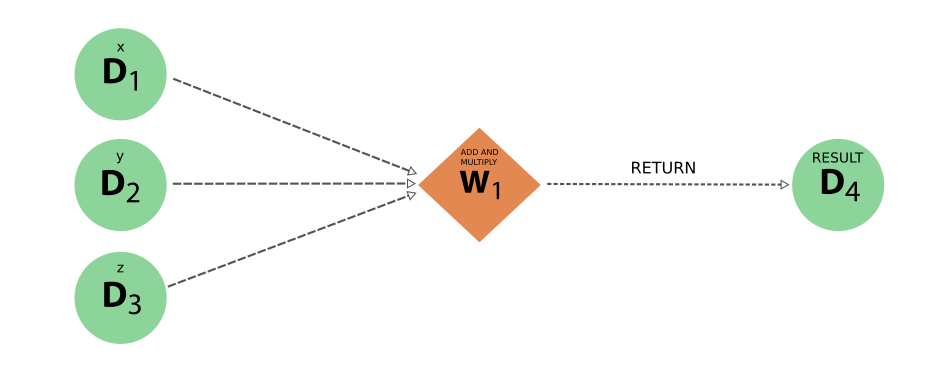
图 18 工作链示例生成的 provenance 直接在大纲步骤中计算和与积,而不是委托计算函数进行计算#
请注意,与前一个来自 图 17 的正确解的 provenance 不同,这里没有明确的计算 node 来表示和与积的计算。取而代之的是,所有的计算都被抽象化,并由代表工作链执行的单个 workflow node 表示。在 provenance graph 中,这些大纲步骤内部的逻辑由单个 workflow node 组成 ‘hidden’ 或 ‘encapsulated’。此外,代表最终产品的输出 node 只有 return 链接,尽管它是由工作链创建的。这是因为 workflow processes do not have the capacity to create new nodes ,因此在本例中丢失了数据 provenance。
import 要记住的一点是,工作链大纲步骤正文中发生的 任何计算 都不会显式表示,而是由表示工作链执行的图形中的单个 node 封装。数据 provenance 的丢失是否相关取决于用例,由 workflow 的开发者决定。这两个例子表明,AiiDA 并不强迫任何特定的方法,而是允许用户选择他们想在 provenance 中保持的粒度水平。然而,经验法则是,如果你想把 provenance 的损耗或 ‘hiding’ 降低到最低,就应该把工作函数和工作链主体中的实际计算保持在最低水平,并委托给计算。对于任何与数据 provenance 相关的实际计算工作,最好在显式计算 processes 中实现,通常是一个单独的计算函数。
优势#
与本节开头介绍的工作函数解决方案相比,工作链解决加法乘法问题所需的代码要多得多。那为什么还要使用工作链呢?这个微不足道的例子可能很难体现出它的优势,但试想一下,workflow 的逻辑会变得更加复杂,计算量也会变得更大。工作链的 process 规范提供了定义输入和输出的核心方法,使工作链如何运行一目了然。此外, outline 还能简明扼要地概括工作链要执行的逻辑步骤,而所有这些都是工作函数所不具备的。本例中的大纲非常简单,但 advanced work chain development section 将展示如何在 process 规范中直接实现复杂的逻辑。process 规范还可以通过 expose functionality 轻松地将现有的工作链 ‘wrap’ 变成更复杂的工作链。
最后,如前所述,工作链提供了检查点的可能性,即在某些点保存进度,计算中断后可以从这些点继续进行。工作链的状态会在每个大纲步骤后保存。如果在单个大纲步骤中执行了昂贵的计算工作,则这些工作完成后会立即被保存。这对工作函数来说是不可能的,如果在**个计算完成之前中断,所有中间进度都将丢失。因此,经验法则是,只要工作流程变得稍微复杂或计算密集,就应优先使用 work chains 和 calculation jobs 。
以上只是对工作链的预期用途和工作原理的快速概述,当然工作链还有更多的功能。要了解如何针对实际问题编写工作链,请继续阅读 work chain development 部分,但在此之前,请阅读以下部分,了解何时使用工作函数以及何时使用工作链更好。
何时使用#
既然我们已经知道工作函数和工作链这两个 workflow 组件在 AiiDA 中是如何工作的,你可能会问:我应该在什么时候使用哪一个?对于时间不长的简单操作,工作函数的简洁性可能就是你所需要的,所以请尽一切可能使用它。不过,一个好的经验法则是,一旦预计代码需要较长时间,例如要启动 calculation job 或其他复杂的 workflow,最好还是使用工作链。自动检查点功能可确保保存各步骤之间的工作,因此非常实用。但工作链提供的功能远不止检查点功能,与工作函数相比,工作链可能更受欢迎,您可以在高级 work chain development 部分了解更多信息。