aiida.orm package¶
Main module to expose all orm classes and methods
-
class
aiida.orm.AuthInfo(computer, user, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityBase class to map a DbAuthInfo, that contains computer configuration specific to a given user (authorization info and other metadata, like how often to check on a given computer etc.)
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of AuthInfo entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.authinfos'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332168886¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
PROPERTY_WORKDIR= 'workdir'¶
-
__init__(computer, user, backend=None)[source]¶ Create a AuthInfo given a computer and a user
Parameters: - computer – a Computer instance
- user – a User instance
Returns: an AuthInfo object associated with the given computer and user
-
__module__= 'aiida.orm.authinfos'¶
-
computer¶
-
enabled¶ Is the computer enabled for this user?
Return type: bool
-
get_property(name)[source]¶ Get an authinfo property
Parameters: name – the property name Returns: the property value
-
get_workdir()[source]¶ Get the workdir; defaults to the value of the corresponding computer, if not explicitly set
Returns: the workdir Return type: str
-
set_auth_params(auth_params)[source]¶ Set the dictionary of auth_params
Parameters: auth_params – a dictionary with the new auth_params
-
set_property(name, value)[source]¶ Set an authinfo property
Parameters: - name – the property name
- value – the property value
-
user¶
-
class
-
class
aiida.orm.Comment(node, user, content=None, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityBase class to map a DbComment that represents a comment attached to a certain Node.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of Comment entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.comments'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332295371¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
__init__(node, user, content=None, backend=None)[source]¶ Create a Comment for a given node and user
Parameters: - node – a Node instance
- user – a User instance
- content – the comment content
Returns: a Comment object associated to the given node and user
-
__module__= 'aiida.orm.comments'¶
-
content¶
-
ctime¶
-
mtime¶
-
node¶
-
user¶
-
class
-
class
aiida.orm.Computer(name, hostname, description='', transport_type='', scheduler_type='', workdir=None, enabled_state=True, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityBase class to map a node in the DB + its permanent repository counterpart.
Stores attributes starting with an underscore.
Caches files and attributes before the first save, and saves everything only on store(). After the call to store(), attributes cannot be changed.
Only after storing (or upon loading from uuid) metadata can be modified and in this case they are directly set on the db.
In the plugin, also set the _plugin_type_string, to be set in the DB in the ‘type’ field.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of Computer entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.computers'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332306077¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
PROPERTY_MINIMUM_SCHEDULER_POLL_INTERVAL= 'minimum_scheduler_poll_interval'¶
-
PROPERTY_MINIMUM_SCHEDULER_POLL_INTERVAL__DEFAULT= 10.0¶
-
PROPERTY_SHEBANG= 'shebang'¶
-
PROPERTY_WORKDIR= 'workdir'¶
-
__init__(name, hostname, description='', transport_type='', scheduler_type='', workdir=None, enabled_state=True, backend=None)[source]¶ Construct a new computer
-
__module__= 'aiida.orm.computers'¶
-
classmethod
_default_mpiprocs_per_machine_validator(def_cpus_per_machine)[source]¶ Validates the default number of CPUs per machine (node)
-
_logger= <logging.Logger object>¶
-
_mpirun_command_validator(mpirun_cmd)[source]¶ Validates the mpirun_command variable. MUST be called after properly checking for a valid scheduler.
-
configure(user=None, **kwargs)[source]¶ Configure a computer for a user with valid auth params passed via kwargs
Parameters: user – the user to configure the computer for Kwargs: the configuration keywords with corresponding values Returns: the authinfo object for the configured user Return type: aiida.orm.AuthInfo
-
delete_property(name, raise_exception=True)[source]¶ Delete a property from this computer
Parameters: - name – the name of the property
- raise_exception – if True raise if the property does not exist, otherwise return None
-
description¶ Get a description of the computer
Returns: the description Return type: str
-
full_text_info¶ Return a (multiline) string with a human-readable detailed information on this computer.
Rypte: str
-
get_authinfo(user)[source]¶ Return the aiida.orm.authinfo.AuthInfo instance for the given user on this computer, if the computer is configured for the given user.
Parameters: user – a User instance. Returns: a AuthInfo instance Raises: aiida.common.NotExistent – if the computer is not configured for the given user.
-
get_configuration(user=None)[source]¶ Get the configuration of computer for the given user as a dictionary
Parameters: user ( aiida.orm.User) – the user to to get the configuration for. Uses default user if None
-
get_default_mpiprocs_per_machine()[source]¶ Return the default number of CPUs per machine (node) for this computer, or None if it was not set.
-
get_description()[source]¶ Get the description for this computer
Returns: the description Return type: str
-
get_minimum_job_poll_interval()[source]¶ Get the minimum interval between subsequent requests to update the list of jobs currently running on this computer.
Returns: The minimum interval (in seconds) Return type: float
-
get_mpirun_command()[source]¶ Return the mpirun command. Must be a list of strings, that will be then joined with spaces when submitting.
I also provide a sensible default that may be ok in many cases.
-
get_property(name, *args)[source]¶ Get a property of this computer
Parameters: - name – the property name
- args – additional arguments
Returns: the property value
-
get_scheduler()[source]¶ Get a scheduler instance for this computer
Returns: the scheduler instance Return type: aiida.schedulers.Scheduler
-
get_scheduler_type()[source]¶ Get the scheduler type for this computer
Returns: the scheduler type Return type: str
-
static
get_schema()[source]¶ - Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: get schema of the computer
-
get_transport(user=None)[source]¶ Return a Transport class, configured with all correct parameters. The Transport is closed (meaning that if you want to run any operation with it, you have to open it first (i.e., e.g. for a SSH transport, you have to open a connection). To do this you can call
transports.open(), or simply run within awithstatement:transport = Computer.get_transport() with transport: print(transports.whoami())
Parameters: user – if None, try to obtain a transport for the default user. Otherwise, pass a valid User. Returns: a (closed) Transport, already configured with the connection parameters to the supercomputer, as configured with verdi computer configurefor the user specified as a parameteruser.
-
get_transport_class()[source]¶ Get the transport class for this computer. Can be used to instantiate a transport instance.
Returns: the transport class
-
get_transport_type()[source]¶ Get the current transport type for this computer
Returns: the transport type Return type: str
-
get_workdir()[source]¶ Get the working directory for this computer :return: The currently configured working directory :rtype: str
-
hostname¶
-
is_user_configured(user)[source]¶ Is the user configured on this computer?
Parameters: user – the user to check Returns: True if configured, False otherwise Return type: bool
-
is_user_enabled(user)[source]¶ Is the given user enabled to run on this computer?
Parameters: user – the user to check Returns: True if enabled, False otherwise Return type: bool
-
label¶ The computer label
-
logger¶
-
name¶
-
set_default_mpiprocs_per_machine(def_cpus_per_machine)[source]¶ Set the default number of CPUs per machine (node) for this computer. Accepts None if you do not want to set this value.
-
set_description(val)[source]¶ Set the description for this computer
Parameters: val (str) – the new description
-
set_enabled_state(enabled)[source]¶ Set the enable state for this computer
Parameters: enabled – True if enabled, False otherwise
-
set_hostname(val)[source]¶ Set the hostname of this computer :param val: The new hostname :type val: str
-
set_minimum_job_poll_interval(interval)[source]¶ Set the minimum interval between subsequent requests to update the list of jobs currently running on this computer.
Parameters: interval (float) – The minimum interval in seconds
-
set_mpirun_command(val)[source]¶ Set the mpirun command. It must be a list of strings (you can use string.split() if you have a single, space-separated string).
-
set_property(name, value)[source]¶ Set a property on this computer
Parameters: - name – the property name
- value – the new value
-
set_transport_type(transport_type)[source]¶ Set the transport type for this computer
Parameters: transport_type (str) – the new transport type
-
store()[source]¶ Store the computer in the DB.
Differently from Nodes, a computer can be re-stored if its properties are to be changed (e.g. a new mpirun command, etc.)
-
validate()[source]¶ Check if the attributes and files retrieved from the DB are valid. Raise a ValidationError if something is wrong.
Must be able to work even before storing: therefore, use the get_attr and similar methods that automatically read either from the DB or from the internal attribute cache.
For the base class, this is always valid. Subclasses will reimplement this. In the subclass, always call the super().validate() method first!
-
class
-
class
aiida.orm.Entity(backend_entity)[source]¶ Bases:
objectAn AiiDA entity
-
class
Collection(backend, entity_class)¶ Bases:
typing.GenericContainer class that represents the collection of objects of a particular type.
-
_COLLECTIONS= <aiida.common.datastructures.LazyStore object>¶
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__call__(backend)¶ Create a new objects collection using a different backend
Parameters: backend – the backend to use Returns: a new collection with the different backend
-
__dict__= dict_proxy({'__module__': 'aiida.orm.entities', u'__origin__': None, 'all': <function all>, '_gorg': aiida.orm.entities.Collection, '__dict__': <attribute '__dict__' of 'Collection' objects>, 'query': <function query>, '__weakref__': <attribute '__weakref__' of 'Collection' objects>, 'find': <function find>, '__init__': <function __init__>, 'backend': <property object>, '_abc_cache': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache_version': 35, 'entity_type': <property object>, '__abstractmethods__': frozenset([]), '__call__': <function __call__>, '__args__': None, '__doc__': 'Container class that represents the collection of objects of a particular type.', '__tree_hash__': 5926332092883, 'get': <function get>, '__parameters__': (~EntityType,), '__orig_bases__': (typing.Generic[~EntityType],), '_COLLECTIONS': <aiida.common.datastructures.LazyStore object>, 'get_collection': <classmethod object>, '__next_in_mro__': <type 'object'>, u'__extra__': None, '_abc_registry': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache': <_weakrefset.WeakSet object>})¶
-
__extra__= None¶
-
__init__(backend, entity_class)¶ Construct a new entity collection
-
__module__= 'aiida.orm.entities'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (typing.Generic[~EntityType],)¶
-
__origin__= None¶
-
__parameters__= (~EntityType,)¶
-
__tree_hash__= 5926332092883¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 35¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
all()¶ Get all entities in this collection
Returns: A collection of users matching the criteria
-
backend¶ Return the backend.
-
entity_type¶
-
find(filters=None, order_by=None, limit=None)¶ Find collection entries matching the filter criteria
Parameters: - filters – the keyword value pair filters to match
- order_by (list) – a list of (key, direction) pairs specifying the sort order
- limit (int) – the maximum number of results to return
Returns: a list of resulting matches
Return type: list
-
get(**filters)¶ Get a single collection entry that matches the filter criteria
Parameters: filters – the filters identifying the object to get Returns: the entry
-
classmethod
get_collection(entity_type, backend)¶ Get the collection for a given entity type and backend instance
Parameters: - entity_type – the entity type e.g. User, Computer, etc
- backend – the backend instance to get the collection for
Returns: the collection instance
-
query()¶ Get a query builder for the objects of this collection
Returns: a new query builder instance Return type: aiida.orm.QueryBuilder
-
-
__dict__= dict_proxy({'__module__': 'aiida.orm.entities', 'get': <classmethod object>, '__dict__': <attribute '__dict__' of 'Entity' objects>, 'is_stored': <property object>, '_objects': None, 'initialize': <function new_fn>, '__weakref__': <attribute '__weakref__' of 'Entity' objects>, 'id': <property object>, '__init__': <function __init__>, 'backend': <property object>, 'from_backend_entity': <classmethod object>, 'uuid': <property object>, 'init_from_backend': <function init_from_backend>, 'Collection': aiida.orm.entities.Collection, 'backend_entity': <property object>, 'objects': <aiida.common.lang.classproperty object>, 'pk': <property object>, '__doc__': 'An AiiDA entity', 'store': <function store>})¶
-
__init__(backend_entity)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.entities'¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_objects= None¶
-
backend¶ Get the backend for this entity :return: the backend instance
-
backend_entity¶ Get the implementing class for this object
Returns: the class model
-
classmethod
from_backend_entity(backend_entity)[source]¶ Construct an entity from a backend entity instance
Parameters: backend_entity – the backend entity Returns: an AiiDA entity instance
-
id¶ Get the id for this entity. This is unique only amongst entities of this type for a particular backend
Returns: the entity id
-
init_from_backend(backend_entity)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
initialize(*args, **kwargs)¶
-
is_stored¶ Is the computer stored?
Returns: True if stored, False otherwise Return type: bool
-
objects¶ A class that, when used as a decorator, works as if the two decorators @property and @classmethod where applied together (i.e., the object works as a property, both for the Class and for any of its instance; and is called with the class cls rather than with the instance as its first argument).
-
pk¶ Get the primary key for this entity
Note
Deprecated because the backend need not be a database and so principle key doesn’t always make sense. Use id() instead.
Returns: the principal key
-
uuid¶ Get the UUID for this entity. This is unique across all entities types and backends
Returns: the entity uuid Return type: uuid.UUID
-
class
-
class
aiida.orm.Collection(backend, entity_class)[source]¶ Bases:
typing.GenericContainer class that represents the collection of objects of a particular type.
-
_COLLECTIONS= <aiida.common.datastructures.LazyStore object>¶
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__call__(backend)[source]¶ Create a new objects collection using a different backend
Parameters: backend – the backend to use Returns: a new collection with the different backend
-
__dict__= dict_proxy({'__module__': 'aiida.orm.entities', u'__origin__': None, 'all': <function all>, '_gorg': aiida.orm.entities.Collection, '__dict__': <attribute '__dict__' of 'Collection' objects>, 'query': <function query>, '__weakref__': <attribute '__weakref__' of 'Collection' objects>, 'find': <function find>, '__init__': <function __init__>, 'backend': <property object>, '_abc_cache': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache_version': 35, 'entity_type': <property object>, '__abstractmethods__': frozenset([]), '__call__': <function __call__>, '__args__': None, '__doc__': 'Container class that represents the collection of objects of a particular type.', '__tree_hash__': 5926332092883, 'get': <function get>, '__parameters__': (~EntityType,), '__orig_bases__': (typing.Generic[~EntityType],), '_COLLECTIONS': <aiida.common.datastructures.LazyStore object>, 'get_collection': <classmethod object>, '__next_in_mro__': <type 'object'>, u'__extra__': None, '_abc_registry': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache': <_weakrefset.WeakSet object>})¶
-
__extra__= None¶
-
__module__= 'aiida.orm.entities'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (typing.Generic[~EntityType],)¶
-
__origin__= None¶
-
__parameters__= (~EntityType,)¶
-
__tree_hash__= 5926332092883¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 35¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
all()[source]¶ Get all entities in this collection
Returns: A collection of users matching the criteria
-
backend¶ Return the backend.
-
entity_type¶
-
find(filters=None, order_by=None, limit=None)[source]¶ Find collection entries matching the filter criteria
Parameters: - filters – the keyword value pair filters to match
- order_by (list) – a list of (key, direction) pairs specifying the sort order
- limit (int) – the maximum number of results to return
Returns: a list of resulting matches
Return type: list
-
get(**filters)[source]¶ Get a single collection entry that matches the filter criteria
Parameters: filters – the filters identifying the object to get Returns: the entry
-
classmethod
get_collection(entity_type, backend)[source]¶ Get the collection for a given entity type and backend instance
Parameters: - entity_type – the entity type e.g. User, Computer, etc
- backend – the backend instance to get the collection for
Returns: the collection instance
-
query()[source]¶ Get a query builder for the objects of this collection
Returns: a new query builder instance Return type: aiida.orm.QueryBuilder
-
-
class
aiida.orm.Group(label=None, user=None, description='', type_string=<GroupTypeString.USER: 'user'>, backend=None, name=None, type=None)[source]¶ Bases:
aiida.orm.entities.EntityAn AiiDA ORM implementation of group of nodes.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionCollection of Groups
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.groups'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332329563¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
get_or_create(label=None, **kwargs)[source]¶ Try to retrieve a group from the DB with the given arguments; create (and store) a new group if such a group was not present yet.
Returns: (group, created) where group is the group (new or existing, in any case already stored) and created is a boolean saying
-
-
__init__(label=None, user=None, description='', type_string=<GroupTypeString.USER: 'user'>, backend=None, name=None, type=None)[source]¶ Create a new group. Either pass a dbgroup parameter, to reload ad group from the DB (and then, no further parameters are allowed), or pass the parameters for the Group creation.
Parameters: - dbgroup – the dbgroup object, if you want to reload the group from the DB rather than creating a new one.
- label – The group label, required on creation
- description – The group description (by default, an empty string)
- user – The owner of the group (by default, the automatic user)
- type_string – a string identifying the type of group (by default, an empty string, indicating an user-defined group.
-
__module__= 'aiida.orm.groups'¶
-
add_nodes(nodes)[source]¶ Add a node or a set of nodes to the group.
Note: all the nodes and the group itself have to be stored. Parameters: nodes – a single Node or a list of Nodes
-
count()[source]¶ Return the number of entities in this group.
Returns: integer number of entities contained within the group
-
description¶ Returns: the description of the group as a string
-
classmethod
get(**kwargs)[source]¶ Custom get for group which can be used to get a group with the given attributes
Parameters: kwargs – the attributes to match the group to Returns: the group Return type: aiida.orm.Group
-
classmethod
get_from_string(string)[source]¶ Get a group from a string. If only the label is provided, without colons, only user-defined groups are searched; add ‘:type_str’ after the group label to choose also the type of the group equal to ‘type_str’ (e.g. ‘data.upf’, ‘import’, etc.)
Raises: - ValueError – if the group type does not exist.
- aiida.common.NotExistent – if the group is not found.
-
classmethod
get_or_create(backend=None, **kwargs)[source]¶ Try to retrieve a group from the DB with the given arguments; create (and store) a new group if such a group was not present yet.
Returns: (group, created) where group is the group (new or existing, in any case already stored) and created is a boolean saying
-
static
get_schema()[source]¶ - Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: get schema of the group
-
is_empty¶ Return whether the group is empty, i.e. it does not contain any nodes.
Returns: boolean, True if it contains no nodes, False otherwise
-
label¶ Returns: the label of the group as a string
-
name¶ Returns: the label of the group as a string
-
nodes¶ Return a generator/iterator that iterates over all nodes and returns the respective AiiDA subclasses of Node, and also allows to ask for the number of nodes in the group using len().
-
remove_nodes(nodes)[source]¶ Remove a node or a set of nodes to the group.
Note: all the nodes and the group itself have to be stored. Parameters: nodes – a single Node or a list of Nodes
-
type¶ Returns: the string defining the type of the group
-
type_string¶ Returns: the string defining the type of the group
-
user¶ Returns: the user associated with this group
-
uuid¶ Returns: a string with the uuid
-
class
-
class
aiida.orm.GroupTypeString[source]¶ Bases:
enum.EnumA simple enum of allowed group type strings.
-
IMPORTGROUP_TYPE= 'auto.import'¶
-
UPFGROUP_TYPE= 'data.upf'¶
-
USER= 'user'¶
-
VERDIAUTOGROUP_TYPE= 'auto.run'¶
-
__module__= 'aiida.orm.groups'¶
-
-
class
aiida.orm.Log(time, loggername, levelname, dbnode_id, message='', metadata=None, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityAn AiiDA Log entity. Corresponds to a logged message against a particular AiiDA node.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThis class represents the collection of logs and can be used to create and retrieve logs.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.logs'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332335920¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
static
create_entry_from_record(record)[source]¶ Helper function to create a log entry from a record created as by the python logging library
Parameters: record ( logging.record) – The record created by the logging moduleReturns: An object implementing the log entry interface Return type: aiida.orm.logs.Log
-
delete(log_id)[source]¶ Remove a Log entry from the collection with the given id
Parameters: log_id – id of the log to delete
-
get_logs_for(entity, order_by=None)[source]¶ Get all the log messages for a given entity and optionally sort
Parameters: - entity (
aiida.orm.Entity) – the entity to get logs for - order_by – the optional sort order
Returns: the list of log entries
Return type: list
- entity (
-
-
__init__(time, loggername, levelname, dbnode_id, message='', metadata=None, backend=None)[source]¶ Construct a new log
-
__module__= 'aiida.orm.logs'¶
-
dbnode_id¶ Get the id of the object that created the log entry
Returns: The id of the object that created the log entry Return type: int
-
levelname¶ The name of the log level
Returns: The entry log level name Return type: basestring
-
loggername¶ The name of the logger that created this entry
Returns: The entry loggername Return type: basestring
-
message¶ Get the message corresponding to the entry
Returns: The entry message Return type: basestring
-
metadata¶ Get the metadata corresponding to the entry
Returns: The entry metadata Return type: json.json
-
time¶ Get the time corresponding to the entry
Returns: The entry timestamp Return type: datetime.datetime
-
class
-
class
aiida.orm.Data(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.node.NodeThis class is base class for all data objects.
Specifications of the Data class: AiiDA Data objects are subclasses of Node and should have
Multiple inheritance must be supported, i.e. Data should have methods for querying and be able to inherit other library objects such as ASE for structures.
Architecture note: The code plugin is responsible for converting a raw data object produced by code to AiiDA standard object format. The data object then validates itself according to its method. This is done independently in order to allow cross-validation of plugins.
-
__abstractmethods__= frozenset([])¶
-
__deepcopy__(memo)[source]¶ Create a clone of the Data node by pipiong through to the clone method and return the result.
Returns: an unstored clone of this Data node
-
__module__= 'aiida.orm.nodes.data.data'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_export_format_replacements= {}¶
-
_exportcontent(fileformat, main_file_name='', **kwargs)[source]¶ Converts a Data node to one (or multiple) files.
Note: Export plugins should return utf8-encoded bytes, which can be directly dumped to file.
Parameters: - fileformat (str) – the extension, uniquely specifying the file format.
- main_file_name (str) – (empty by default) Can be used by plugin to infer sensible names for additional files, if necessary. E.g. if the main file is ‘../myplot.gnu’, the plugin may decide to store the dat file under ‘../myplot_data.dat’.
- kwargs – other parameters are passed down to the plugin
Returns: a tuple of length 2. The first element is the content of the otuput file. The second is a dictionary (possibly empty) in the format {filename: filecontent} for any additional file that should be produced.
Return type: (bytes, dict)
-
_get_converters()[source]¶ Get all implemented converter formats. The convention is to find all _get_object_… methods. Returns a list of strings.
-
_get_exporters()[source]¶ Get all implemented export formats. The convention is to find all _prepare_… methods. Returns a dictionary of method_name: method_function
-
_get_importers()[source]¶ Get all implemented import formats. The convention is to find all _parse_… methods. Returns a list of strings.
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.data.Data.'¶
-
_query_type_string= 'data.data.'¶
-
_source_attributes= ['db_name', 'db_uri', 'uri', 'id', 'version', 'extras', 'source_md5', 'description', 'license']¶
-
_storable= True¶
-
_unstorable_message= 'storing for this node has been disabled'¶
-
_validate()[source]¶ Perform validation of the Data object.
Note
validation of data source checks license and requires attribution to be provided in field ‘description’ of source in the case of any CC-BY* license. If such requirement is too strict, one can remove/comment it out.
-
convert(object_format=None, *args)[source]¶ Convert the AiiDA StructureData into another python object
Parameters: object_format – Specify the output format
-
creator¶ Return the creator of this node or None if it does not exist.
Returns: the creating node or None
-
export(path, fileformat=None, overwrite=False, **kwargs)[source]¶ Save a Data object to a file.
Parameters: - fname – string with file name. Can be an absolute or relative path.
- fileformat – kind of format to use for the export. If not present, it will try to use the extension of the file name.
- overwrite – if set to True, overwrites file found at path. Default=False
- kwargs – additional parameters to be passed to the _exportcontent method
Returns: the list of files created
-
classmethod
get_export_formats()[source]¶ Get the list of valid export format strings
Returns: a list of valid formats
-
importfile(fname, fileformat=None)[source]¶ Populate a Data object from a file.
Parameters: - fname – string with file name. Can be an absolute or relative path.
- fileformat – kind of format to use for the export. If not present, it will try to use the extension of the file name.
-
importstring(inputstring, fileformat, **kwargs)[source]¶ Converts a Data object to other text format.
Parameters: fileformat – a string (the extension) to describe the file format. Returns: a string with the structure description.
-
source¶ Gets the dictionary describing the source of Data object. Possible fields:
- db_name: name of the source database.
- db_uri: URI of the source database.
- uri: URI of the object’s source. Should be a permanent link.
- id: object’s source identifier in the source database.
- version: version of the object’s source.
- extras: a dictionary with other fields for source description.
- source_md5: MD5 checksum of object’s source.
- description: human-readable free form description of the object’s source.
- license: a string with a type of license.
Note
some limitations for setting the data source exist, see
_validatemethod.Returns: dictionary describing the source of Data object.
-
-
class
aiida.orm.BaseType(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataData sub class to be used as a base for data containers that represent base python data types.
-
__abstractmethods__= frozenset([])¶
-
__init__(*args, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.base'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.base.BaseType.'¶
-
_query_type_string= 'data.base.'¶
-
value¶
-
-
class
aiida.orm.ArrayData(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataStore a set of arrays on disk (rather than on the database) in an efficient way using numpy.save() (therefore, this class requires numpy to be installed).
Each array is stored within the Node folder as a different .npy file.
Note: Before storing, no caching is done: if you perform a get_array()call, the array will be re-read from disk. If instead the ArrayData node has already been stored, the array is cached in memory after the first read, and the cached array is used thereafter. If too much RAM memory is used, you can clear the cache with theclear_internal_cache()method.-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.array.array'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_arraynames_from_files()[source]¶ Return a list of all arrays stored in the node, listing the files (and not relying on the properties).
-
_arraynames_from_properties()[source]¶ Return a list of all arrays stored in the node, listing the attributes starting with the correct prefix.
-
_cached_arrays= None¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.array.array.ArrayData.'¶
-
_query_type_string= 'data.array.array.'¶
-
_validate()[source]¶ Check if the list of .npy files stored inside the node and the list of properties match. Just a name check, no check on the size since this would require to reload all arrays and this may take time and memory.
-
array_prefix= 'array|'¶
-
clear_internal_cache()[source]¶ Clear the internal memory cache where the arrays are stored after being read from disk (used in order to reduce at minimum the readings from disk). This function is useful if you want to keep the node in memory, but you do not want to waste memory to cache the arrays in RAM.
-
delete_array(name)[source]¶ Delete an array from the node. Can only be called before storing.
Parameters: name – The name of the array to delete from the node.
-
get_array(name)[source]¶ Return an array stored in the node
Parameters: name – The name of the array to return.
-
get_arraynames()[source]¶ Return a list of all arrays stored in the node, listing the files (and not relying on the properties).
New in version 0.7: Renamed from arraynames
-
get_iterarrays()[source]¶ Iterator that returns tuples (name, array) for each array stored in the node.
New in version 1.0: Renamed from iterarrays
-
get_shape(name)[source]¶ Return the shape of an array (read from the value cached in the properties for efficiency reasons).
Parameters: name – The name of the array.
-
-
class
aiida.orm.BandsData(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.array.kpoints.KpointsDataClass to handle bands data
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.array.bands'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_custom_export_format_replacements= {'dat': 'dat_multicolumn', 'gnu': 'gnuplot', 'pdf': 'mpl_pdf', 'png': 'mpl_png', 'py': 'mpl_singlefile'}¶
-
_get_bandplot_data(cartesian, prettify_format=None, join_symbol=None, get_segments=False, y_origin=0.0)[source]¶ Get data to plot a band structure
Parameters: - cartesian – if True, distances (for the x-axis) are computed in cartesian coordinates, otherwise they are computed in reciprocal coordinates. cartesian=True will fail if no cell has been set.
- prettify_format – by default, strings are not prettified. If you want to prettify them, pass a valid prettify_format string (see valid options in the docstring of :py:func:prettify_labels).
- join_symbols – by default, strings are not joined. If you pass a string,
this is used to join strings that are much closer than a given threshold.
The most typical string is the pipe symbol:
|. - get_segments – if True, also computes the band split into segments
- y_origin – if present, shift bands so to set the value specified at
y=0
Returns: a plot_info dictiorary, whose keys are
x(array of distances for the x axis of the plot);y(array of bands),labels(list of tuples in the format (float x value of the label, label string),band_type_idx(array containing an index for each band: if there is only one spin, then it’s an array of zeros, of length equal to the number of bands at each point; if there are two spins, then it’s an array of zeros or ones depending on the type of spin; the length is always equalt to the total number of bands per kpoint).
-
_logger= <logging.Logger object>¶
-
_matplotlib_get_dict(main_file_name='', comments=True, title='', legend=None, legend2=None, y_max_lim=None, y_min_lim=None, y_origin=0.0, prettify_format=None, **kwargs)[source]¶ Prepare the data to send to the python-matplotlib plotting script.
Parameters: - comments – if True, print comments (if it makes sense for the given format)
- plot_info – a dictionary
- setnumber_offset – an offset to be applied to all set numbers (i.e. s0 is replaced by s[offset], s1 by s[offset+1], etc.)
- color_number – the color number for lines, symbols, error bars and filling (should be less than the parameter max_num_agr_colors defined below)
- title – the title
- legend – the legend (applied only to the first of the set)
- legend2 – the legend for second-type spins (applied only to the first of the set)
- y_max_lim – the maximum on the y axis (if None, put the maximum of the bands)
- y_min_lim – the minimum on the y axis (if None, put the minimum of the bands)
- y_origin – the new origin of the y axis -> all bands are replaced by bands-y_origin
- prettify_format – if None, use the default prettify format. Otherwise specify a string with the prettifier to use.
- kwargs – additional customization variables; only a subset is accepted, see internal variable ‘valid_additional_keywords
-
_plugin_type_string= 'data.array.bands.BandsData.'¶
-
_prepare_agr(main_file_name='', comments=True, setnumber_offset=0, color_number=1, color_number2=2, legend='', title='', y_max_lim=None, y_min_lim=None, y_origin=0.0, prettify_format=None)[source]¶ Prepare an xmgrace agr file.
Parameters: - comments – if True, print comments (if it makes sense for the given format)
- plot_info – a dictionary
- setnumber_offset – an offset to be applied to all set numbers (i.e. s0 is replaced by s[offset], s1 by s[offset+1], etc.)
- color_number – the color number for lines, symbols, error bars and filling (should be less than the parameter max_num_agr_colors defined below)
- color_number2 – the color number for lines, symbols, error bars and filling for the second-type spins (should be less than the parameter max_num_agr_colors defined below)
- legend – the legend (applied only to the first set)
- title – the title
- y_max_lim – the maximum on the y axis (if None, put the
maximum of the bands); applied after shifting the origin
by
y_origin - y_min_lim – the minimum on the y axis (if None, put the
minimum of the bands); applied after shifting the origin
by
y_origin - y_origin – the new origin of the y axis -> all bands are replaced by bands-y_origin
- prettify_format – if None, use the default prettify format. Otherwise specify a string with the prettifier to use.
-
_prepare_agr_batch(main_file_name='', comments=True, prettify_format=None)[source]¶ Prepare two files, data and batch, to be plot with xmgrace as: xmgrace -batch file.dat
Parameters: - main_file_name – if the user asks to write the main content on a file, this contains the filename. This should be used to infer a good filename for the additional files. In this case, we remove the extension, and add ‘_data.dat’
- comments – if True, print comments (if it makes sense for the given format)
- prettify_format – if None, use the default prettify format. Otherwise specify a string with the prettifier to use.
-
_prepare_dat_1(*args, **kwargs)[source]¶ Output data in .dat format, using multiple columns for all y values associated to the same x.
Deprecated since version 0.8.1: Use ‘dat_multicolumn’ format instead
-
_prepare_dat_2(*args, **kwargs)[source]¶ Output data in .dat format, using blocks.
Deprecated since version 0.8.1: Use ‘dat_block’ format instead
-
_prepare_dat_blocks(main_file_name='', comments=True)[source]¶ Format suitable for gnuplot using blocks. Columns with x and y (path and band energy). Several blocks, separated by two empty lines, one per energy band.
Parameters: comments – if True, print comments (if it makes sense for the given format)
-
_prepare_dat_multicolumn(main_file_name='', comments=True)[source]¶ Write an N x M matrix. First column is the distance between kpoints, The other columns are the bands. Header contains number of kpoints and the number of bands (commented).
Parameters: comments – if True, print comments (if it makes sense for the given format)
-
_prepare_gnuplot(main_file_name='', title='', comments=True, prettify_format=None, y_max_lim=None, y_min_lim=None, y_origin=0.0)[source]¶ Prepare an gnuplot script to plot the bands, with the .dat file returned as an independent file.
Parameters: - main_file_name – if the user asks to write the main content on a file, this contains the filename. This should be used to infer a good filename for the additional files. In this case, we remove the extension, and add ‘_data.dat’
- title – if specified, add a title to the plot
- comments – if True, print comments (if it makes sense for the given format)
- prettify_format – if None, use the default prettify format. Otherwise specify a string with the prettifier to use.
-
_prepare_json(main_file_name='', comments=True)[source]¶ Prepare a json file in a format compatible with the AiiDA band visualizer
Parameters: comments – if True, print comments (if it makes sense for the given format)
-
_prepare_mpl_pdf(main_file_name='', *args, **kwargs)[source]¶ Prepare a python script using matplotlib to plot the bands, with the JSON returned as an independent file.
For the possible parameters, see documentation of
_matplotlib_get_dict()
-
_prepare_mpl_png(main_file_name='', *args, **kwargs)[source]¶ Prepare a python script using matplotlib to plot the bands, with the JSON returned as an independent file.
For the possible parameters, see documentation of
_matplotlib_get_dict()
-
_prepare_mpl_singlefile(*args, **kwargs)[source]¶ Prepare a python script using matplotlib to plot the bands
For the possible parameters, see documentation of
_matplotlib_get_dict()
-
_prepare_mpl_withjson(main_file_name='', *args, **kwargs)[source]¶ Prepare a python script using matplotlib to plot the bands, with the JSON returned as an independent file.
For the possible parameters, see documentation of
_matplotlib_get_dict()
-
_query_type_string= 'data.array.bands.'¶
-
_validate_bands_occupations(bands, occupations=None, labels=None)[source]¶ Validate the list of bands and of occupations before storage. Kpoints must be set in advance. Bands and occupations must be convertible into arrays of Nkpoints x Nbands floats or Nspins x Nkpoints x Nbands; Nkpoints must correspond to the number of kpoints.
-
array_labels¶ Get the labels associated with the band arrays
-
get_bands(also_occupations=False, also_labels=False)[source]¶ Returns an array (nkpoints x num_bands or nspins x nkpoints x num_bands) of energies. :param also_occupations: if True, returns also the occupations array. Default = False
-
set_bands(bands, units=None, occupations=None, labels=None)[source]¶ Set an array of band energies of dimension (nkpoints x nbands). Kpoints must be set in advance. Can contain floats or None. :param bands: a list of nkpoints lists of nbands bands, or a 2D array of shape (nkpoints x nbands), with band energies for each kpoint :param units: optional, energy units :param occupations: optional, a 2D list or array of floats of same shape as bands, with the occupation associated to each band
-
set_kpointsdata(kpointsdata)[source]¶ Load the kpoints from a kpoint object. :param kpointsdata: an instance of KpointsData class
-
show_mpl(**kwargs)[source]¶ Call a show() command for the band structure using matplotlib. This uses internally the ‘mpl_singlefile’ format, with empty main_file_name.
Other kwargs are passed to self._exportcontent.
-
units¶ Units in which the data in bands were stored. A string
-
-
class
aiida.orm.KpointsData(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.array.array.ArrayDataClass to handle array of kpoints in the Brillouin zone. Provide methods to generate either user-defined k-points or path of k-points along symmetry lines. Internally, all k-points are defined in terms of crystal (fractional) coordinates. Cell and lattice vector coordinates are in Angstroms, reciprocal lattice vectors in Angstrom^-1 . :note: The methods setting and using the Bravais lattice info assume the PRIMITIVE unit cell is provided in input to the set_cell or set_cell_from_structure methods.
-
__abstractmethods__= frozenset([])¶
-
__init__(*args, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.array.kpoints'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_change_reference(kpoints, to_cartesian=True)[source]¶ Change reference system, from cartesian to crystal coordinates (units of b1,b2,b3) or viceversa. :param kpoints: a list of (3) point coordinates :return kpoints: a list of (3) point coordinates in the new reference
-
_dimension¶ Dimensionality of the structure, found from its pbc (i.e. 1 if it’s a 1D structure, 2 if its 2D, 3 if it’s 3D …). :return dimensionality: 0, 1, 2 or 3 :note: will return 3 if pbc has not been set beforehand
-
_find_bravais_info(epsilon_length=1e-05, epsilon_angle=1e-05)[source]¶ Finds the Bravais lattice of the cell passed in input to the Kpoint class :note: We assume that the cell given by the cell property is the primitive unit cell.
Deprecated since version 0.11: Use the methods inside the aiida.tools.data.array.kpoints module instead.
Returns: a dictionary, with keys short_name, extended_name, index (index of the Bravais lattice), and sometimes variation (name of the variation of the Bravais lattice) and extra (a dictionary with extra parameters used by the get_special_points method)
-
_get_or_create_bravais_lattice(epsilon_length=1e-05, epsilon_angle=1e-05)[source]¶ Try to get the bravais_lattice info if stored already, otherwise analyze the cell with the default settings and save this in the attribute.
Deprecated since version 0.11: Use the methods inside the aiida.tools.data.array.kpoints module instead.
Parameters: - epsilon_length – threshold on lengths comparison, used to get the bravais lattice info
- epsilon_angle – threshold on angles comparison, used to get the bravais lattice info
Return bravais_lattice: the dictionary containing the symmetry info
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.array.kpoints.KpointsData.'¶
-
_query_type_string= 'data.array.kpoints.'¶
-
_set_bravais_lattice(value)[source]¶ Validating function to set the bravais_lattice dictionary
Deprecated since version 0.11.
-
_set_cell(value)[source]¶ Validate if ‘value’ is a allowed crystal unit cell :param value: something compatible with a 3x3 tuple of floats
-
_set_labels(value)[source]¶ set label names. Must pass in input a list like:
[[0,'X'],[34,'L'],... ]
-
_set_reciprocal_cell()[source]¶ Sets the reciprocal cell in units of 1/Angstrom from the internally set cell
-
_validate_kpoints_weights(kpoints, weights)[source]¶ Validate the list of kpoints and of weights before storage. Kpoints and weights must be convertible respectively to an array of N x dimension and N floats
-
bravais_lattice¶ The dictionary containing informations about the cell symmetry
Deprecated since version 0.11.
-
cell¶ The crystal unit cell. Rows are the crystal vectors in Angstroms. :return: a 3x3 numpy.array
-
find_bravais_lattice(epsilon_length=1e-05, epsilon_angle=1e-05)[source]¶ Analyze the symmetry of the cell. Allows to relax or tighten the thresholds used to compare angles and lengths of the cell. Save the information of the cell used for later use (like getting special points). It has to be used if the user wants to be sure the right symmetries are recognized. Otherwise, this function is automatically called with the default values.
If the right symmetry is not found, be sure also you are providing cells with enough digits.
If node is already stored, just returns the symmetry found before storing (if any).
Deprecated since version 0.11: Use the methods inside the aiida.tools.data.array.kpoints module instead.
Return (str) lattice_name: the name of the bravais lattice and its eventual variation
-
get_description()[source]¶ Returns a string with infos retrieved from kpoints node’s properties. :param node: :return: retstr
-
get_kpoints(also_weights=False, cartesian=False)[source]¶ Return the list of kpoints
Parameters: - also_weights – if True, returns also the list of weights. Default = False
- cartesian – if True, returns points in cartesian coordinates, otherwise, returns in crystal coordinates. Default = False.
-
get_kpoints_mesh(print_list=False)[source]¶ Get the mesh of kpoints.
Parameters: print_list – default=False. If True, prints the mesh of kpoints as a list Raises: AttributeError – if no mesh has been set Return mesh,offset: (if print_list=False) a list of 3 integers and a list of three floats 0<x<1, representing the mesh and the offset of kpoints Return kpoints: (if print_list = True) an explicit list of kpoints coordinates, similar to what returned by get_kpoints()
-
get_special_points(cartesian=False, epsilon_length=1e-05, epsilon_angle=1e-05)[source]¶ Get the special point and path of a given structure.
References:
- In 2D, coordinates are based on the paper: R. Ramirez and M. C. Bohm, Int. J. Quant. Chem., XXX, pp. 391-411 (1986)
- In 3D, coordinates are based on the paper: W. Setyawan, S. Curtarolo, Comp. Mat. Sci. 49, 299 (2010)
Deprecated since version 0.11: Use the methods inside the aiida.tools.data.array.kpoints module instead.
Parameters: - cartesian – If true, returns points in cartesian coordinates. Crystal coordinates otherwise. Default=False
- epsilon_length – threshold on lengths comparison, used to get the bravais lattice info
- epsilon_angle – threshold on angles comparison, used to get the bravais lattice info
Returns point_coords: a dictionary of point_name:point_coords key,values.
Returns path: the suggested path which goes through all high symmetry lines. A list of lists for all path segments. e.g. [(‘G’,’X’),(‘X’,’M’),…] It’s not necessarily a continuous line.
Note: We assume that the cell given by the cell property is the primitive unit cell
-
labels¶ Labels associated with the list of kpoints. List of tuples with kpoint index and kpoint name:
[(0,'G'),(13,'M'),...]
-
pbc¶ The periodic boundary conditions along the vectors a1,a2,a3.
Returns: a tuple of three booleans, each one tells if there are periodic boundary conditions for the i-th real-space direction (i=1,2,3)
-
set_cell(cell, pbc=None)[source]¶ Set a cell to be used for symmetry analysis. To set a cell from an AiiDA structure, use “set_cell_from_structure”.
Parameters: - cell – 3x3 matrix of cell vectors. Orientation: each row represent a lattice vector. Units are Angstroms.
- pbc – list of 3 booleans, True if in the nth crystal direction the structure is periodic. Default = [True,True,True]
-
set_cell_from_structure(structuredata)[source]¶ Set a cell to be used for symmetry analysis from an AiiDA structure. Inherits both the cell and the pbc’s. To set manually a cell, use “set_cell”
Parameters: structuredata – an instance of StructureData
-
set_kpoints(kpoints, cartesian=False, labels=None, weights=None, fill_values=0)[source]¶ Set the list of kpoints. If a mesh has already been stored, raise a ModificationNotAllowed
Parameters: - kpoints –
a list of kpoints, each kpoint being a list of one, two or three coordinates, depending on self.pbc: if structure is 1D (only one True in self.pbc) one allows singletons or scalars for each k-point, if it’s 2D it can be a length-2 list, and in all cases it can be a length-3 list. Examples:
- [[0.,0.,0.],[0.1,0.1,0.1],…] for 1D, 2D or 3D
- [[0.,0.],[0.1,0.1,],…] for 1D or 2D
- [[0.],[0.1],…] for 1D
- [0., 0.1, …] for 1D (list of scalars)
For 0D (all pbc are False), the list can be any of the above or empty - then only Gamma point is set. The value of k for the non-periodic dimension(s) is set by fill_values
- cartesian – if True, the coordinates given in input are treated as in cartesian units. If False, the coordinates are crystal, i.e. in units of b1,b2,b3. Default = False
- labels – optional, the list of labels to be set for some of the kpoints. See labels for more info
- weights – optional, a list of floats with the weight associated to the kpoint list
- fill_values – scalar to be set to all non-periodic dimensions (indicated by False in self.pbc), or list of values for each of the non-periodic dimensions.
- kpoints –
-
set_kpoints_mesh(mesh, offset=[0.0, 0.0, 0.0])[source]¶ Set KpointsData to represent a uniformily spaced mesh of kpoints in the Brillouin zone. This excludes the possibility of set/get kpoints
Parameters: - mesh – a list of three integers, representing the size of the kpoint mesh along b1,b2,b3.
- offset – (optional) a list of three floats between 0 and 1. [0.,0.,0.] is Gamma centered mesh [0.5,0.5,0.5] is half shifted [1.,1.,1.] by periodicity should be equivalent to [0.,0.,0.] Default = [0.,0.,0.].
-
set_kpoints_mesh_from_density(distance, offset=[0.0, 0.0, 0.0], force_parity=False)[source]¶ Set a kpoints mesh using a kpoints density, expressed as the maximum distance between adjacent points along a reciprocal axis
Parameters: - distance – distance (in 1/Angstrom) between adjacent
kpoints, i.e. the number of kpoints along each reciprocal
axis i is
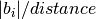 where
where 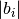 is the norm of the reciprocal cell vector.
is the norm of the reciprocal cell vector. - offset – (optional) a list of three floats between 0 and 1. [0.,0.,0.] is Gamma centered mesh [0.5,0.5,0.5] is half shifted Default = [0.,0.,0.].
- force_parity – (optional) if True, force each integer in the mesh to be even (except for the non-periodic directions).
Note: a cell should be defined first.
Note: the number of kpoints along non-periodic axes is always 1.
- distance – distance (in 1/Angstrom) between adjacent
kpoints, i.e. the number of kpoints along each reciprocal
axis i is
-
set_kpoints_path(value=None, kpoint_distance=None, cartesian=False, epsilon_length=1e-05, epsilon_angle=1e-05)[source]¶ Set a path of kpoints in the Brillouin zone.
Deprecated since version 0.11: Use the methods inside the aiida.tools.data.array.kpoints module instead.
Parameters: - value –
description of the path, in various possible formats.
None: automatically sets all irreducible high symmetry paths. Requires that a cell was set
or
[(‘G’,’M’), (…), …] [(‘G’,’M’,30), (…), …] [(‘G’,(0,0,0),’M’,(1,1,1)), (…), …] [(‘G’,(0,0,0),’M’,(1,1,1),30), (…), …]
- cartesian (bool) – if set to true, reads the coordinates eventually passed in value as cartesian coordinates. Default: False.
- kpoint_distance (float) – parameter controlling the distance between kpoints. Distance is given in crystal coordinates, i.e. the distance is computed in the space of b1,b2,b3. The distance set will be the closest possible to this value, compatible with the requirement of putting equispaced points between two special points (since extrema are included).
- epsilon_length (float) – threshold on lengths comparison, used to get the bravais lattice info. It has to be used if the user wants to be sure the right symmetries are recognized.
- epsilon_angle (float) – threshold on angles comparison, used to get the bravais lattice info. It has to be used if the user wants to be sure the right symmetries are recognized.
- value –
-
-
class
aiida.orm.ProjectionData(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.orbital.OrbitalData,aiida.orm.nodes.data.array.array.ArrayDataA class to handle arrays of projected wavefunction data. That is projections of a orbitals, usually an atomic-hydrogen orbital, onto a given bloch wavefunction, the bloch wavefunction being indexed by s, n, and k. E.g. the elements are the projections described as < orbital | Bloch wavefunction (s,n,k) >
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.array.projection'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_check_projections_bands(projection_array)[source]¶ Checks to make sure that a reference bandsdata is already set, and that projection_array is of the same shape of the bands data
Parameters: projwfc_arrays – nk x nb x nwfc array, to be checked against bands Raise: AttributeError if energy is not already set Raise: AttributeError if input_array is not of same shape as dos_energy
-
_find_orbitals_and_indices(**kwargs)[source]¶ Finds all the orbitals and their indicies associated with kwargs essential for retrieving the other indexed array parameters
Parameters: kwargs – kwargs that can call orbitals as in get_orbitals() Returns: retrieve_indexes, list of indicicies of orbitals corresponding to the kwargs Returns: all_orbitals, list of orbitals to which the indexes correspond
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.array.projection.ProjectionData.'¶
-
_query_type_string= 'data.array.projection.'¶
-
get_pdos(**kwargs)[source]¶ Retrieves all the pdos arrays corresponding to the input kwargs
Parameters: kwargs – inputs describing the orbitals associated with the pdos arrays Returns: a list of tuples containing the orbital, energy array and pdos array associated with all orbitals that correspond to kwargs
-
get_projections(**kwargs)[source]¶ Retrieves all the pdos arrays corresponding to the input kwargs
Parameters: kwargs – inputs describing the orbitals associated with the pdos arrays Returns: a list of tuples containing the orbital, and projection arrays associated with all orbitals that correspond to kwargs
-
get_reference_bandsdata()[source]¶ Returns the reference BandsData, using the set uuid via set_reference_bandsdata
Returns: a BandsData instance
Raises: - AttributeError – if the bandsdata has not been set yet
- exceptions.NotExistent – if the bandsdata uuid did not retrieve bandsdata
-
set_orbitals(**kwargs)[source]¶ This method is inherited from OrbitalData, but is blocked here. If used will raise a NotImplementedError
-
set_projectiondata(list_of_orbitals, list_of_projections=None, list_of_energy=None, list_of_pdos=None, tags=None, bands_check=True)[source]¶ Stores the projwfc_array using the projwfc_label, after validating both.
Parameters: - list_of_orbitals – list of orbitals, of class orbital data. They should be the ones up on which the projection array corresponds with.
- list_of_projections – list of arrays of projections of a atomic wavefunctions onto bloch wavefunctions. Since the projection is for every bloch wavefunction which can be specified by its spin (if used), band, and kpoint the dimensions must be nspin x nbands x nkpoints for the projwfc array. Or nbands x nkpoints if spin is not used.
- energy_axis – list of energy axis for the list_of_pdos
- list_of_pdos – a list of projected density of states for the atomic wavefunctions, units in states/eV
- tags – A list of tags, not supported currently.
- bands_check – if false, skips checks of whether the bands has been already set, and whether the sizes match. For use in parsers, where the BandsData has not yet been stored and therefore get_reference_bandsdata cannot be called
-
set_reference_bandsdata(value)[source]¶ Sets a reference bandsdata, creates a uuid link between this data object and a bandsdata object, must be set before any projection arrays
Parameters: value – a BandsData instance, a uuid or a pk Raise: exceptions.NotExistent if there was no BandsData associated with uuid or pk
-
-
class
aiida.orm.TrajectoryData(structurelist=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.array.array.ArrayDataStores a trajectory (a sequence of crystal structures with timestamps, and possibly with velocities).
-
__abstractmethods__= frozenset([])¶
-
__init__(structurelist=None, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.array.trajectory'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_get_aiida_structure(store=False, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.structure.StructureData.Parameters: - converter – specify the converter. Default ‘ase’.
- store – If True, intermediate calculation gets stored in the AiiDA database for record. Default False.
Returns:
-
_get_cif(index=None, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.cif.CifData
-
_internal_validate(stepids, cells, symbols, positions, times, velocities)[source]¶ Internal function to validate the type and shape of the arrays. See the documentation of py:meth:.set_trajectory for a description of the valid shape and type of the parameters.
-
_logger= <logging.Logger object>¶
-
_parse_xyz_pos(inputstring)[source]¶ Load positions from a XYZ file.
Note
The steps and symbols must be set manually before calling this import function as a consistency measure. Even though the symbols and steps could be extracted from the XYZ file, the data present in the XYZ file may or may not be correct and the same logic would have to be present in the XYZ-velocities function. It was therefore decided not to implement it at all but require it to be set explicitly.
Usage:
from aiida.orm.nodes.data.array.trajectory import TrajectoryData t = TrajectoryData() # get sites and number of timesteps t.set_array('steps', arange(ntimesteps)) t.set_array('symbols', array([site.kind for site in s.sites])) t.importfile('some-calc/AIIDA-PROJECT-pos-1.xyz', 'xyz_pos')
-
_parse_xyz_vel(inputstring)[source]¶ Load velocities from a XYZ file.
Note
The steps and symbols must be set manually before calling this import function as a consistency measure. See also comment for
_parse_xyz_pos()
-
_plugin_type_string= 'data.array.trajectory.TrajectoryData.'¶
-
_prepare_cif(trajectory_index=None, main_file_name='')[source]¶ Write the given trajectory to a string of format CIF.
-
_prepare_tcod(main_file_name='', **kwargs)[source]¶ Write the given trajectory to a string of format TCOD CIF.
-
_prepare_xsf(index=None, main_file_name='')[source]¶ Write the given trajectory to a string of format XSF (for XCrySDen).
-
_query_type_string= 'data.array.trajectory.'¶
-
_validate()[source]¶ Verify that the required arrays are present and that their type and dimension are correct.
-
get_cells()[source]¶ Return the array of cells, if it has already been set.
Raises: KeyError – if the trajectory has not been set yet.
-
get_cif(index=None, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.cif.CifDataNew in version 1.0: Renamed from _get_cif
-
get_index_from_stepid(stepid)[source]¶ Given a value for the stepid (i.e., a value among those of the
stepsarray), return the array index of that stepid, that can be used in other methods such asget_step_data()orget_step_structure().New in version 0.7: Renamed from get_step_index
Note
Note that this function returns the first index found (i.e. if multiple steps are present with the same value, only the index of the first one is returned).
Raises: ValueError – if no step with the given value is found.
-
get_positions()[source]¶ Return the array of positions, if it has already been set.
Raises: KeyError – if the trajectory has not been set yet.
-
get_step_data(index)[source]¶ Return a tuple with all information concerning the stepid with given index (0 is the first step, 1 the second step and so on). If you know only the step value, use the
get_index_from_stepid()method to get the corresponding index.If no velocities were specified, None is returned as the last element.
Returns: A tuple in the format
(stepid, time, cell, symbols, positions, velocities), wherestepidis an integer,timeis a float,cellis a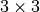 matrix,
matrix, symbolsis an array of lengthn, positions is a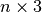 array, and velocities is either
array, and velocities is either
Noneor a arrayParameters: index – The index of the step that you want to retrieve, from 0 to
self.numsteps - 1.Raises: - IndexError – if you require an index beyond the limits.
- KeyError – if you did not store the trajectory yet.
-
get_step_structure(index, custom_kinds=None)[source]¶ Return an AiiDA
aiida.orm.nodes.data.structure.StructureDatanode (not stored yet!) with the coordinates of the given step, identified by its index. If you know only the step value, use theget_index_from_stepid()method to get the corresponding index.Note
The periodic boundary conditions are always set to True.
New in version 0.7: Renamed from step_to_structure
Parameters: - index – The index of the step that you want to retrieve, from
0 to
self.numsteps- 1. - custom_kinds – (Optional) If passed must be a list of
aiida.orm.nodes.data.structure.Kindobjects. There must be one kind object for each different string in thesymbolsarray, withkind.nameset to this string. If this parameter is omitted, the automatic kind generation of AiiDAaiida.orm.nodes.data.structure.StructureDatanodes is used, meaning that the strings in thesymbolsarray must be valid chemical symbols.
- index – The index of the step that you want to retrieve, from
0 to
-
get_stepids()[source]¶ Return the array of steps, if it has already been set.
New in version 0.7: Renamed from get_steps
Raises: KeyError – if the trajectory has not been set yet.
-
get_structure(store=False, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.structure.StructureData.New in version 1.0: Renamed from _get_aiida_structure
Parameters: - converter – specify the converter. Default ‘ase’.
- store – If True, intermediate calculation gets stored in the AiiDA database for record. Default False.
Returns:
-
get_times()[source]¶ Return the array of times (in ps), if it has already been set.
Raises: KeyError – if the trajectory has not been set yet.
-
get_velocities()[source]¶ Return the array of velocities, if it has already been set.
Note
This function (differently from all other
get_*functions, will not raise an exception if the velocities are not set, but rather returnNone(both if no trajectory was not set yet, and if it the trajectory was set but no velocities were specified).
-
numsites¶ Return the number of stored sites, or zero if nothing has been stored yet.
-
numsteps¶ Return the number of stored steps, or zero if nothing has been stored yet.
-
set_structurelist(structurelist)[source]¶ Create trajectory from the list of
aiida.orm.nodes.data.structure.StructureDatainstances.Parameters: structurelist – a list of aiida.orm.nodes.data.structure.StructureDatainstances.Raises: ValueError – if symbol lists of supplied structures are different
-
set_trajectory(symbols, positions, stepids=None, cells=None, times=None, velocities=None)[source]¶ Store the whole trajectory, after checking that types and dimensions are correct.
Parameters
stepids,cellsandvelocitiesare optional variables. If nothing is passed forcellsorvelocitiesnothing will be stored. However, if no input is given forstepidsa consecutive sequence [0,1,2,…,len(positions)-1] will be assumed.Parameters: - symbols – string list with dimension
n, wherenis the number of atoms (i.e., sites) in the structure. The same list is used for each step. Normally, the string should be a valid chemical symbol, but actually any unique string works and can be used as the name of the atomic kind (see also theget_step_structure()method). - positions – float array with dimension
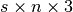 ,
where
,
where sis the length of thestepidsarray andnis the length of thesymbolsarray. Units are angstrom. In particular,positions[i,j,k]is thek-th component of thej-th atom (or site) in the structure at the time step with indexi(identified by step numberstep[i]and with timestamptimes[i]). - stepids – integer array with dimension
s, wheresis the number of steps. Typically represents an internal counter within the code. For instance, if you want to store a trajectory with one step every 10, starting from step 65, the array will be[65,75,85,...]. No checks are done on duplicate elements or on the ordering, but anyway this array should be sorted in ascending order, without duplicate elements. (If not specified, stepids will be set tonumpy.arange(s)by default) It is internally stored as an array named ‘steps’. - cells – if specified float array with dimension
 , where
, where sis the length of thestepidsarray. Units are angstrom. In particular,cells[i,j,k]is thek-th component of thej-th cell vector at the time step with indexi(identified by step numberstepid[i]and with timestamptimes[i]). - times – if specified, float array with dimension
s, wheresis the length of thestepidsarray. Contains the timestamp of each step in picoseconds (ps). - velocities – if specified, must be a float array with the same
dimensions of the
positionsarray. The array contains the velocities in the atoms.
Todo
Choose suitable units for velocities
- symbols – string list with dimension
-
show_mpl_pos(**kwargs)[source]¶ Shows the positions as a function of time, separate for XYZ coordinates
Parameters: - stepsize (int) – The stepsize for the trajectory, set higher than 1 to reduce number of points
- mintime (int) – Time to start from
- maxtime (int) – Maximum time
- elements (list) – A list of atomic symbols that should be displayed. If not specified, all atoms are displayed.
- indices (list) – A list of indices of that atoms that can be displayed. If not specified, all atoms of the correct species are displayed.
- dont_block (bool) – If True, interpreter is not blocked when figure is displayed.
-
symbols¶ Return the array of symbols, if it has already been set.
Raises: KeyError – if the trajectory has not been set yet.
-
-
class
aiida.orm.XyData(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.array.array.ArrayDataA subclass designed to handle arrays that have an “XY” relationship to each other. That is there is one array, the X array, and there are several Y arrays, which can be considered functions of X.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.array.xy'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_arrayandname_validator(array, name, units)[source]¶ Validates that the array is an numpy.ndarray and that the name is of type basestring. Raises InputValidationError if this not the case.
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.array.xy.XyData.'¶
-
_query_type_string= 'data.array.xy.'¶
-
get_x()[source]¶ Tries to retrieve the x array and x name raises a NotExistent exception if no x array has been set yet. :return x_name: the name set for the x_array :return x_array: the x array set earlier :return x_units: the x units set earlier
-
get_y()[source]¶ Tries to retrieve the y arrays and the y names, raises a NotExistent exception if they have not been set yet, or cannot be retrieved :return y_names: list of strings naming the y_arrays :return y_arrays: list of y_arrays :return y_units: list of strings giving the units for the y_arrays
-
set_x(x_array, x_name, x_units)[source]¶ Sets the array and the name for the x values.
Parameters: - x_array – A numpy.ndarray, containing only floats
- x_name – a string for the x array name
- x_units – the units of x
-
set_y(y_arrays, y_names, y_units)[source]¶ Set array(s) for the y part of the dataset. Also checks if the x_array has already been set, and that, the shape of the y_arrays agree with the x_array. :param y_arrays: A list of y_arrays, numpy.ndarray :param y_names: A list of strings giving the names of the y_arrays :param y_units: A list of strings giving the units of the y_arrays
-
-
class
aiida.orm.Bool(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.base.BaseTypeData sub class to represent a boolean value.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.bool'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.bool.Bool.'¶
-
_query_type_string= 'data.bool.'¶
-
_type¶ alias of
__builtin__.bool
-
-
class
aiida.orm.CifData(ase=None, filepath=None, values=None, source=None, scan_type='standard', parse_policy='eager', **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.singlefile.SinglefileDataWrapper for Crystallographic Interchange File (CIF)
Note
the filepath (physical) is held as the authoritative source of information, so all conversions are done through the physical file: when setting
aseorvalues, a physical CIF file is generated first, the values are updated from the physical CIF file.-
__abstractmethods__= frozenset([])¶
-
__init__(ase=None, filepath=None, values=None, source=None, scan_type='standard', parse_policy='eager', **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.cif'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_ase= None¶
-
_get_aiida_structure(converter='pymatgen', store=False, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.structure.StructureData.Parameters: - converter – specify the converter. Default ‘pymatgen’.
- store – if True, intermediate calculation gets stored in the AiiDA database for record. Default False.
- primitive_cell – if True, primitive cell is returned, conventional cell if False. Default False.
- occupancy_tolerance – If total occupancy of a site is between 1 and occupancy_tolerance, the occupancies will be scaled down to 1. (pymatgen only)
- site_tolerance – This tolerance is used to determine if two sites are sitting in the same position, in which case they will be combined to a single disordered site. Defaults to 1e-4. (pymatgen only)
Returns:
-
_logger= <logging.Logger object>¶
-
_parse_policies= ('eager', 'lazy')¶
-
_plugin_type_string= 'data.cif.CifData.'¶
-
_prepare_cif(main_file_name='')[source]¶ Return CIF string of CifData object.
If parsed values are present, a CIF string is created and written to file. If no parsed values are present, the CIF string is read from file.
-
_prepare_tcod(main_file_name='', **kwargs)[source]¶ Write the given CIF to a string of format TCOD CIF.
-
_query_type_string= 'data.cif.'¶
-
_scan_types= ('standard', 'flex')¶
-
_set_incompatibilities= [('ase', 'filepath'), ('ase', 'values'), ('filepath', 'values')]¶
-
_values= None¶
-
ase¶ ASE object, representing the CIF.
Note
requires ASE module.
-
classmethod
from_md5(md5)[source]¶ Return a list of all CIF files that match a given MD5 hash.
Note
the hash has to be stored in a
_md5attribute, otherwise the CIF file will not be found.
-
get_ase(**kwargs)[source]¶ Returns ASE object, representing the CIF. This function differs from the property
aseby the possibility to pass the keyworded arguments (kwargs) to ase.io.cif.read_cif().Note
requires ASE module.
-
get_formulae(mode='sum')[source]¶ Return chemical formulae specified in CIF file.
Note: This does not compute the formula, it only reads it from the appropriate tag. Use refine_inline to compute formulae.
-
classmethod
get_or_create(filename, use_first=False, store_cif=True)[source]¶ Pass the same parameter of the init; if a file with the same md5 is found, that CifData is returned.
Parameters: - filename – an absolute filename on disk
- use_first – if False (default), raise an exception if more than one CIF file is found. If it is True, instead, use the first available CIF file.
- store_cif (bool) – If false, the CifData objects are not stored in the database. default=True.
Return (cif, created): where cif is the CifData object, and create is either True if the object was created, or False if the object was retrieved from the DB.
-
get_structure(converter='pymatgen', store=False, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.structure.StructureData.New in version 1.0: Renamed from _get_aiida_structure
Parameters: - converter – specify the converter. Default ‘pymatgen’.
- store – if True, intermediate calculation gets stored in the AiiDA database for record. Default False.
- primitive_cell – if True, primitive cell is returned, conventional cell if False. Default False.
- occupancy_tolerance – If total occupancy of a site is between 1 and occupancy_tolerance, the occupancies will be scaled down to 1. (pymatgen only)
- site_tolerance – This tolerance is used to determine if two sites are sitting in the same position, in which case they will be combined to a single disordered site. Defaults to 1e-4. (pymatgen only)
Returns:
-
has_atomic_sites¶ Returns whether there are any atomic sites defined in the cif data. That is to say, it will check all the values for the _atom_site_fract_* tags and if they are all equal to ? that means there are no relevant atomic sites defined and the function will return False. In all other cases the function will return True
Returns: False when at least one atomic site fractional coordinate is not equal to ? and True otherwise
-
has_attached_hydrogens¶ Check if there are hydrogens without coordinates, specified as attached to the atoms of the structure.
Returns: True if there are attached hydrogens, False otherwise.
-
has_partial_occupancies¶ Return if the cif data contains partial occupancies
A partial occupancy is defined as site with an occupancy that differs from unity, within a precision of 1E-6
Returns: True if there are partial occupancies, False otherwise
-
has_undefined_atomic_sites¶ Return whether the cif data contains any undefined atomic sites.
An undefined atomic site is defined as a site where at least one of the fractional coordinates specified in the _atom_site_fract_* tags, cannot be successfully interpreted as a float. If the cif data contains any site that matches this description, or it does not contain any atomic site tags at all, the cif data is said to have undefined atomic sites.
Returns: boolean, True if no atomic sites are defined or if any of the defined sites contain undefined positions and False otherwise
-
has_unknown_species¶ Returns whether the cif contains atomic species that are not recognized by AiiDA.
The known species are taken from the elements dictionary in aiida.common.constants, with the exception of the “unknown” placeholder element with symbol ‘X’, as this could not be used to construct a real structure. If any of the formula of the cif data contain species that are not in that elements dictionary, the function will return True and False in all other cases. If there is no formulae to be found, it will return None
Returns: True when there are unknown species in any of the formulae, False if not, None if no formula found
-
parse(scan_type=None)[source]¶ Parses CIF file and sets attributes.
Parameters: scan_type – See set_scan_type
-
put_object_from_file(path, key=None, mode='w', encoding='utf8', force=False)[source]¶ Set the file.
If the source is set and the MD5 checksum of new file is different from the source, the source has to be deleted.
-
static
read_cif(fileobj, index=-1, **kwargs)[source]¶ A wrapper method that simulates the behavior of the old function ase.io.cif.read_cif by using the new generic ase.io.read function.
-
set_ase(aseatoms)[source]¶ Set the contents of the CifData starting from an ASE atoms object
Parameters: aseatoms – the ASE atoms object
-
set_parse_policy(parse_policy)[source]¶ Set the parse policy.
Parameters: parse_policy – Either ‘eager’ (parse CIF file on set_file) or ‘lazy’ (defer parsing until needed)
-
set_scan_type(scan_type)[source]¶ Set the scan_type for PyCifRW.
The ‘flex’ scan_type of PyCifRW is faster for large CIF files but does not yet support the CIF2 format as of 02/2018. See the CifFile.ReadCif function
Parameters: scan_type – Either ‘standard’ or ‘flex’ (see _scan_types)
-
set_values(values)[source]¶ Set internal representation to values.
Warning: This also writes a new CIF file.
Parameters: values – PyCifRW CifFile object Note
requires PyCifRW module.
-
values¶ PyCifRW structure, representing the CIF datablocks.
Note
requires PyCifRW module.
-
-
class
aiida.orm.Code(remote_computer_exec=None, local_executable=None, input_plugin_name=None, files=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataA code entity. It can either be ‘local’, or ‘remote’.
- Local code: it is a collection of files/dirs (added using the add_path() method), where one file is flagged as executable (using the set_local_executable() method).
- Remote code: it is a pair (remotecomputer, remotepath_of_executable) set using the set_remote_computer_exec() method.
For both codes, one can set some code to be executed right before or right after the execution of the code, using the set_preexec_code() and set_postexec_code() methods (e.g., the set_preexec_code() can be used to load specific modules required for the code to be run).
-
HIDDEN_KEY= 'hidden'¶
-
__abstractmethods__= frozenset([])¶
-
__init__(remote_computer_exec=None, local_executable=None, input_plugin_name=None, files=None, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.code'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.code.Code.'¶
-
_query_type_string= 'data.code.'¶
-
_set_local()[source]¶ Set the code as a ‘local’ code, meaning that all the files belonging to the code will be copied to the cluster, and the file set with set_exec_filename will be run.
It also deletes the flags related to the local case (if any)
-
_set_remote()[source]¶ Set the code as a ‘remote’ code, meaning that the code itself has no files attached, but only a location on a remote computer (with an absolute path of the executable on the remote computer).
It also deletes the flags related to the local case (if any)
-
_validate()[source]¶ Perform validation of the Data object.
Note
validation of data source checks license and requires attribution to be provided in field ‘description’ of source in the case of any CC-BY* license. If such requirement is too strict, one can remove/comment it out.
-
can_run_on(computer)[source]¶ Return True if this code can run on the given computer, False otherwise.
Local codes can run on any machine; remote codes can run only on the machine on which they reside.
TODO: add filters to mask the remote machines on which a local code can run.
-
full_label¶ Get full label of this code.
Returns label of the form <code-label>@<computer-name>.
-
full_text_info(verbose=False)[source]¶ Return a (multiline) string with a human-readable detailed information on this computer
-
classmethod
get(pk=None, label=None, machinename=None)[source]¶ Get a Computer object with given identifier string, that can either be the numeric ID (pk), or the label (and computername) (if unique).
Parameters: - pk – the numeric ID (pk) for code
- label – the code label identifying the code to load
- machinename – the machine name where code is setup
Raises: - aiida.common.NotExistent – if no code identified by the given string is found
- aiida.common.MultipleObjectsError – if the string cannot identify uniquely a code
- aiida.common.InputValidationError – if neither a pk nor a label was passed in
-
get_append_text()[source]¶ Return the postexec_code, or an empty string if no post-exec code was defined.
-
get_builder()[source]¶ Create and return a new ProcessBuilder for the default Calculation plugin, as obtained by the self.get_input_plugin_name() method.
Note: it also sets the
builder.codevalue.Raises: - aiida.common.MissingPluginError – if the specified plugin does not exist.
- ValueError – if no default plugin was specified.
Returns:
-
classmethod
get_code_helper(label, machinename=None)[source]¶ Parameters: - label – the code label identifying the code to load
- machinename – the machine name where code is setup
Raises: - aiida.common.NotExistent – if no code identified by the given string is found
- aiida.common.MultipleObjectsError – if the string cannot identify uniquely a code
-
get_description()[source]¶ Return a string description of this Code instance.
Returns: string description of this Code instance
-
get_execname()[source]¶ Return the executable string to be put in the script. For local codes, it is ./LOCAL_EXECUTABLE_NAME For remote codes, it is the absolute path to the executable.
-
classmethod
get_from_string(code_string)[source]¶ Get a Computer object with given identifier string in the format label@machinename. See the note below for details on the string detection algorithm.
Note
the (leftmost) ‘@’ symbol is always used to split code and computername. Therefore do not use ‘@’ in the code name if you want to use this function (‘@’ in the computer name are instead valid).
Parameters: code_string – the code string identifying the code to load
Raises: - aiida.common.NotExistent – if no code identified by the given string is found
- aiida.common.MultipleObjectsError – if the string cannot identify uniquely a code
- aiida.common.InputValidationError – if code_string is not of string type
-
get_full_text_info(verbose=False)[source]¶ Return a (multiline) string with a human-readable detailed information on this computer
-
get_input_plugin_name()[source]¶ Return the name of the default input plugin (or None if no input plugin was set.
-
get_prepend_text()[source]¶ Return the code that will be put in the scheduler script before the execution, or an empty string if no pre-exec code was defined.
Determines whether the Code is hidden or not
-
is_local()[source]¶ Return True if the code is ‘local’, False if it is ‘remote’ (see also documentation of the set_local and set_remote functions).
-
classmethod
list_for_plugin(plugin, labels=True)[source]¶ Return a list of valid code strings for a given plugin.
Parameters: - plugin – The string of the plugin.
- labels – if True, return a list of code names, otherwise return the code PKs (integers).
Returns: a list of string, with the code names if labels is True, otherwise a list of integers with the code PKs.
-
relabel(new_label, raise_error=True)[source]¶ Relabel this code.
Parameters: - new_label – new code label
- raise_error – Set to False in order to return a list of errors instead of raising them.
-
reveal()[source]¶ Reveal the code (allows to show it in the verdi code list) By default, it is revealed
-
set_append_text(code)[source]¶ Pass a string of code that will be put in the scheduler script after the execution of the code.
-
set_files(files)[source]¶ Given a list of filenames (or a single filename string), add it to the path (all at level zero, i.e. without folders). Therefore, be careful for files with the same name!
Todo: decide whether to check if the Code must be a local executable to be able to call this function.
-
set_input_plugin_name(input_plugin)[source]¶ Set the name of the default input plugin, to be used for the automatic generation of a new calculation.
-
set_local_executable(exec_name)[source]¶ Set the filename of the local executable. Implicitly set the code as local.
-
set_prepend_text(code)[source]¶ Pass a string of code that will be put in the scheduler script before the execution of the code.
-
set_remote_computer_exec(remote_computer_exec)[source]¶ Set the code as remote, and pass the computer on which it resides and the absolute path on that computer.
Parameters: remote_computer_exec – a tuple (computer, remote_exec_path), where computer is a aiida.orm.Computer and remote_exec_path is the absolute path of the main executable on remote computer.
-
class
aiida.orm.Float(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.numeric.NumericTypeData sub class to represent a float value.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.float'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.float.Float.'¶
-
_query_type_string= 'data.float.'¶
-
_type¶ alias of
__builtin__.float
-
-
class
aiida.orm.FolderData(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataData sub class to represent a folder on a file system.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.folder'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.folder.FolderData.'¶
-
_query_type_string= 'data.folder.'¶
-
-
class
aiida.orm.Int(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.numeric.NumericTypeData sub class to represent an integer value.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.int'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.int.Int.'¶
-
_query_type_string= 'data.int.'¶
-
_type¶ alias of
__builtin__.int
-
-
class
aiida.orm.List(**kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.Data,_abcoll.MutableSequenceData sub class to represent a list.
-
_LIST_KEY= 'list'¶
-
__abstractmethods__= frozenset([])¶
-
__init__(**kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.list'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 102¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.list.List.'¶
-
_query_type_string= 'data.list.'¶
-
_using_list_reference()[source]¶ This function tells the class if we are using a list reference. This means that calls to self.get_list return a reference rather than a copy of the underlying list and therefore self.set_list need not be called. This knwoledge is essential to make sure this class is performant.
Currently the implementation assumes that if the node needs to be stored then it is using the attributes cache which is a reference.
Returns: True if using self.get_list returns a reference to the underlying sequence. False otherwise. Return type: bool
-
index(value) → integer -- return first index of value.[source]¶ Raises ValueError if the value is not present.
-
pop([index]) → item -- remove and return item at index (default last).[source]¶ Raise IndexError if list is empty or index is out of range.
-
-
class
aiida.orm.OrbitalData(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataUsed for storing collections of orbitals, as well as providing methods for accessing them internally.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.orbital'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_get_orbital_class_from_orbital_dict(orbital_dict)[source]¶ Gets the orbital class from the orbital dictionary stored in DB
Parameters: orbital_dict – orbital dictionary associated with the orbital Returns: an Orbital produced using the module_name
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.orbital.OrbitalData.'¶
-
static
_prep_orbital_dict_keys_from_site(site)[source]¶ Prepares the position from an input site.
Parameters: site – a site of site class Return out_dict: a dictionary of attributes parsed from the site (currently only position)
-
_query_type_string= 'data.orbital.'¶
-
clear_orbitals()[source]¶ Remove all orbitals that were added to the class Cannot work if OrbitalData has been already stored
-
get_orbitals(with_tags=False, **kwargs)[source]¶ Returns all orbitals by default. If a site is provided, returns all orbitals cooresponding to the location of that site, additional arguments may be provided, which act as filters on the retrieved orbitals.
Parameters: - site – if provided, returns all orbitals with position of site
- with_tags – if provided returns all tags stored
Kwargs: attributes than can filter the set of returned orbitals
Return list_of_outputs: a list of orbitals and also tags if with_tags was set to True
-
set_orbitals(orbital, tag=None)[source]¶ Sets the orbitals into the database. Uses the orbital’s inherent set_orbital_dict method to generate a orbital dict string at is stored along with the tags, if provided.
Parameters: - orbital – an orbital or list of orbitals to be set
- tag – a list of strings must be of length orbital
-
-
class
aiida.orm.Dict(**kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataData sub class to represent a dictionary.
-
__abstractmethods__= frozenset([])¶
-
__init__(**kwargs)[source]¶ Store a dictionary as a Node instance.
Usual rules for attribute names apply, in particular, keys cannot start with an underscore, or a ValueError will be raised.
Initial attributes can be changed, deleted or added as long as the node is not stored.
Parameters: dict – the dictionary to set
-
__module__= 'aiida.orm.nodes.data.dict'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.dict.Dict.'¶
-
_query_type_string= 'data.dict.'¶
-
dict¶ Return an instance of AttributeManager that transforms the dictionary into an attribute dict.
Note
this will allow one to do node.dict.key as well as node.dict[key].
Returns: an instance of the AttributeResultManager.
-
keys()[source]¶ Iterator of valid keys stored in the Dict object.
Returns: iterator over the keys of the current dictionary
-
-
class
aiida.orm.RemoteData(remote_path=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataStore a link to a file or folder on a remote machine.
Remember to pass a computer!
-
__abstractmethods__= frozenset([])¶
-
__init__(remote_path=None, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.remote'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.remote.RemoteData.'¶
-
_query_type_string= 'data.remote.'¶
-
_validate()[source]¶ Perform validation of the Data object.
Note
validation of data source checks license and requires attribution to be provided in field ‘description’ of source in the case of any CC-BY* license. If such requirement is too strict, one can remove/comment it out.
-
getfile(relpath, destpath)[source]¶ Connects to the remote folder and gets a string with the (full) content of the file.
Parameters: - relpath – The relative path of the file to show.
- destpath – A path on the local computer to get the file
Returns: a string with the file content
-
is_empty¶ Check if remote folder is empty
-
listdir(relpath='.')[source]¶ Connects to the remote folder and lists the directory content.
Parameters: relpath – If ‘relpath’ is specified, lists the content of the given subfolder. Returns: a flat list of file/directory names (as strings).
-
listdir_withattributes(path='.')[source]¶ Connects to the remote folder and lists the directory content.
Parameters: relpath – If ‘relpath’ is specified, lists the content of the given subfolder. Returns: a list of dictionaries, where the documentation is in :py:class:Transport.listdir_withattributes.
-
-
class
aiida.orm.SinglefileData(filepath, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataData class that can be used to store a single file in its repository.
-
__abstractmethods__= frozenset([])¶
-
__init__(filepath, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.singlefile'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.singlefile.SinglefileData.'¶
-
_query_type_string= 'data.singlefile.'¶
-
_validate()[source]¶ Ensure that there is one object stored in the repository, whose key matches value set for filename attr.
-
filename¶ Return the name of the file stored.
Returns: the filename under which the file is stored in the repository
-
get_content()[source]¶ Return the content of the single file stored for this data node.
Returns: the string content of the file
-
open(key=None, mode='r')[source]¶ Return an open file handle to the content of this data node.
Parameters: - key – optional key within the repository, by default is the filename set in the attributes
- mode – the mode with which to open the file handle
Returns: a file handle in read mode
-
-
class
aiida.orm.Str(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.base.BaseTypeData sub class to represent a string value.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.str'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.str.Str.'¶
-
_query_type_string= 'data.str.'¶
-
_type¶ alias of
__builtin__.str
-
-
class
aiida.orm.StructureData(cell=None, pbc=None, ase=None, pymatgen=None, pymatgen_structure=None, pymatgen_molecule=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.data.DataThis class contains the information about a given structure, i.e. a collection of sites together with a cell, the boundary conditions (whether they are periodic or not) and other related useful information.
-
__abstractmethods__= frozenset([])¶
-
__init__(cell=None, pbc=None, ase=None, pymatgen=None, pymatgen_structure=None, pymatgen_molecule=None, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.structure'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_adjust_default_cell(vacuum_factor=1.0, vacuum_addition=10.0, pbc=(False, False, False))[source]¶ If the structure was imported from an xyz file, it lacks a defined cell, and the default cell is taken ([[1,0,0], [0,1,0], [0,0,1]]), leading to an unphysical definition of the structure. This method will adjust the cell
-
_dimensionality_label= {0: '', 1: 'length', 2: 'surface', 3: 'volume'}¶
-
_get_cif(converter='ase', store=False, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.cif.CifData.Parameters: - converter – specify the converter. Default ‘ase’.
- store – If True, intermediate calculation gets stored in the AiiDA database for record. Default False.
Returns:
-
_get_object_ase()[source]¶ Converts
StructureDatato ase.AtomsReturns: an ase.Atoms object
-
_get_object_phonopyatoms()[source]¶ Converts StructureData to PhonopyAtoms
Returns: a PhonopyAtoms object
-
_get_object_pymatgen(**kwargs)[source]¶ Converts
StructureDatato pymatgen objectReturns: a pymatgen Structure for structures with periodic boundary conditions (in three dimensions) and Molecule otherwise Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors).
-
_get_object_pymatgen_molecule(**kwargs)[source]¶ Converts
StructureDatato pymatgen Molecule objectReturns: a pymatgen Molecule object corresponding to this StructureDataobject.Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors)
-
_get_object_pymatgen_structure(**kwargs)[source]¶ Converts
StructureDatato pymatgen Structure object :param add_spin: True to add the spins to the pymatgen structure. Default is False (no spin added).Note
The spins are set according to the following rule:
- if the kind name ends with 1 -> spin=+1
- if the kind name ends with 2 -> spin=-1
Returns: a pymatgen Structure object corresponding to this StructureDataobjectRaises: ValueError – if periodic boundary conditions does not hold in at least one dimension of real space; if there are partial occupancies together with spins (defined by kind names ending with ‘1’ or ‘2’). Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors)
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.structure.StructureData.'¶
-
_prepare_chemdoodle(main_file_name='')[source]¶ Write the given structure to a string of format required by ChemDoodle.
-
_prepare_tcod(main_file_name='', **kwargs)[source]¶ Write the given structure to a string of format TCOD CIF.
-
_prepare_xsf(main_file_name='')[source]¶ Write the given structure to a string of format XSF (for XCrySDen).
-
_query_type_string= 'data.structure.'¶
-
_set_incompatibilities= [('ase', 'cell'), ('ase', 'pbc'), ('ase', 'pymatgen'), ('ase', 'pymatgen_molecule'), ('ase', 'pymatgen_structure'), ('cell', 'pymatgen'), ('cell', 'pymatgen_molecule'), ('cell', 'pymatgen_structure'), ('pbc', 'pymatgen'), ('pbc', 'pymatgen_molecule'), ('pbc', 'pymatgen_structure'), ('pymatgen', 'pymatgen_molecule'), ('pymatgen', 'pymatgen_structure'), ('pymatgen_molecule', 'pymatgen_structure')]¶
-
append_atom(**kwargs)[source]¶ Append an atom to the Structure, taking care of creating the corresponding kind.
Parameters: - ase – the ase Atom object from which we want to create a new atom (if present, this must be the only parameter)
- position – the position of the atom (three numbers in angstrom)
- symbols – passed to the constructor of the Kind object.
- weights – passed to the constructor of the Kind object.
- name – passed to the constructor of the Kind object. See also the note below.
Note
Note on the ‘name’ parameter (that is, the name of the kind):
- if specified, no checks are done on existing species. Simply, a new kind with that name is created. If there is a name clash, a check is done: if the kinds are identical, no error is issued; otherwise, an error is issued because you are trying to store two different kinds with the same name.
- if not specified, the name is automatically generated. Before adding the kind, a check is done. If other species with the same properties already exist, no new kinds are created, but the site is added to the existing (identical) kind. (Actually, the first kind that is encountered). Otherwise, the name is made unique first, by adding to the string containing the list of chemical symbols a number starting from 1, until an unique name is found
Note
checks of equality of species are done using the
compare_with()method.
-
append_kind(kind)[source]¶ Append a kind to the
StructureData. It makes a copy of the kind.Parameters: kind – the site to append, must be a Kind object.
-
append_site(site)[source]¶ Append a site to the
StructureData. It makes a copy of the site.Parameters: site – the site to append. It must be a Site object.
-
cell¶ Returns the cell shape.
Returns: a 3x3 list of lists.
-
cell_angles¶ Get the angles between the cell lattice vectors in degrees.
-
cell_lengths¶ Get the lengths of cell lattice vectors in angstroms.
-
get_ase()[source]¶ Get the ASE object. Requires to be able to import ase.
Returns: an ASE object corresponding to this StructureDataobject.Note
If any site is an alloy or has vacancies, a ValueError is raised (from the site.get_ase() routine).
-
get_cif(converter='ase', store=False, **kwargs)[source]¶ Creates
aiida.orm.nodes.data.cif.CifData.New in version 1.0: Renamed from _get_cif
Parameters: - converter – specify the converter. Default ‘ase’.
- store – If True, intermediate calculation gets stored in the AiiDA database for record. Default False.
Returns:
-
get_composition()[source]¶ Returns the chemical composition of this structure as a dictionary, where each key is the kind symbol (e.g. H, Li, Ba), and each value is the number of occurences of that element in this structure. For BaZrO3 it would return {‘Ba’:1, ‘Zr’:1, ‘O’:3}. No reduction with smallest common divisor!
Returns: a dictionary with the composition
-
get_description()[source]¶ Returns a string with infos retrieved from StructureData node’s properties
Parameters: self – the StructureData node Returns: retsrt: the description string
-
get_dimensionality()[source]¶ This function checks the dimensionality of the structure and calculates its length/surface/volume :return: returns the dimensionality and length/surface/volume
-
get_formula(mode='hill', separator='')[source]¶ Return a string with the chemical formula.
Parameters: - mode –
a string to specify how to generate the formula, can assume one of the following values:
- ’hill’ (default): count the number of atoms of each species,
then use Hill notation, i.e. alphabetical order with C and H
first if one or several C atom(s) is (are) present, e.g.
['C','H','H','H','O','C','H','H','H']will return'C2H6O'['S','O','O','H','O','H','O']will return'H2O4S'From E. A. Hill, J. Am. Chem. Soc., 22 (8), pp 478–494 (1900) - ’hill_compact’: same as hill but the number of atoms for each
species is divided by the greatest common divisor of all of them, e.g.
['C','H','H','H','O','C','H','H','H','O','O','O']will return'CH3O2' - ’reduce’: group repeated symbols e.g.
['Ba', 'Ti', 'O', 'O', 'O', 'Ba', 'Ti', 'O', 'O', 'O', 'Ba', 'Ti', 'Ti', 'O', 'O', 'O']will return'BaTiO3BaTiO3BaTi2O3' - ’group’: will try to group as much as possible parts of the formula
e.g.
['Ba', 'Ti', 'O', 'O', 'O', 'Ba', 'Ti', 'O', 'O', 'O', 'Ba', 'Ti', 'Ti', 'O', 'O', 'O']will return'(BaTiO3)2BaTi2O3' - ’count’: same as hill (i.e. one just counts the number
of atoms of each species) without the re-ordering (take the
order of the atomic sites), e.g.
['Ba', 'Ti', 'O', 'O', 'O','Ba', 'Ti', 'O', 'O', 'O']will return'Ba2Ti2O6' - ’count_compact’: same as count but the number of atoms
for each species is divided by the greatest common divisor of
all of them, e.g.
['Ba', 'Ti', 'O', 'O', 'O','Ba', 'Ti', 'O', 'O', 'O']will return'BaTiO3'
- ’hill’ (default): count the number of atoms of each species,
then use Hill notation, i.e. alphabetical order with C and H
first if one or several C atom(s) is (are) present, e.g.
- separator – a string used to concatenate symbols. Default empty.
Returns: a string with the formula
Note
in modes reduce, group, count and count_compact, the initial order in which the atoms were appended by the user is used to group and/or order the symbols in the formula
- mode –
-
get_kind(kind_name)[source]¶ Return the kind object associated with the given kind name.
Parameters: kind_name – String, the name of the kind you want to get Returns: The Kind object associated with the given kind_name, if a Kind with the given name is present in the structure. Raise: ValueError if the kind_name is not present.
-
get_kind_names()[source]¶ Return a list of kind names (in the same order of the
self.kindsproperty, but return the names rather than Kind objects)Note
This is NOT necessarily a list of chemical symbols! Use get_symbols_set for chemical symbols
Returns: a list of strings.
-
get_pymatgen(**kwargs)[source]¶ Get pymatgen object. Returns Structure for structures with periodic boundary conditions (in three dimensions) and Molecule otherwise. :param add_spin: True to add the spins to the pymatgen structure. Default is False (no spin added).
Note
The spins are set according to the following rule:
- if the kind name ends with 1 -> spin=+1
- if the kind name ends with 2 -> spin=-1
Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors).
-
get_pymatgen_molecule()[source]¶ Get the pymatgen Molecule object.
Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors).
Returns: a pymatgen Molecule object corresponding to this StructureDataobject.
-
get_pymatgen_structure(**kwargs)[source]¶ Get the pymatgen Structure object. :param add_spin: True to add the spins to the pymatgen structure. Default is False (no spin added).
Note
The spins are set according to the following rule:
- if the kind name ends with 1 -> spin=+1
- if the kind name ends with 2 -> spin=-1
Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors).
Returns: a pymatgen Structure object corresponding to this StructureDataobject.Raises: ValueError – if periodic boundary conditions do not hold in at least one dimension of real space.
-
get_site_kindnames()[source]¶ Return a list with length equal to the number of sites of this structure, where each element of the list is the kind name of the corresponding site.
Note
This is NOT necessarily a list of chemical symbols! Use
[ self.get_kind(s.kind_name).get_symbols_string() for s in self.sites]for chemical symbolsReturns: a list of strings
-
get_symbols_set()[source]¶ Return a set containing the names of all elements involved in this structure (i.e., for it joins the list of symbols for each kind k in the structure).
Returns: a set of strings of element names.
-
has_vacancies¶ Return whether the structure has vacancies in the structure.
Returns: a boolean, True if at least one kind has a vacancy
-
is_alloy¶ Return whether the structure contains any alloy kinds.
Returns: a boolean, True if at least one kind is an alloy
-
kinds¶ Returns a list of kinds.
-
pbc¶ Get the periodic boundary conditions.
Returns: a tuple of three booleans, each one tells if there are periodic boundary conditions for the i-th real-space direction (i=1,2,3)
-
reset_cell(new_cell)[source]¶ Reset the cell of a structure not yet stored to a new value.
Parameters: new_cell – list specifying the cell vectors Raises: ModificationNotAllowed: if object is already stored
-
reset_sites_positions(new_positions, conserve_particle=True)[source]¶ Replace all the Site positions attached to the Structure
Parameters: - new_positions – list of (3D) positions for every sites.
- conserve_particle – if True, allows the possibility of removing a site. currently not implemented.
Raises: - aiida.common.ModificationNotAllowed – if object is stored already
- ValueError – if positions are invalid
Note
it is assumed that the order of the new_positions is given in the same order of the one it’s substituting, i.e. the kind of the site will not be checked.
-
set_pymatgen(obj, **kwargs)[source]¶ Load the structure from a pymatgen object.
Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors).
-
set_pymatgen_molecule(mol, margin=5)[source]¶ Load the structure from a pymatgen Molecule object.
Parameters: margin – the margin to be added in all directions of the bounding box of the molecule. Note
Requires the pymatgen module (version >= 3.0.13, usage of earlier versions may cause errors).
-
set_pymatgen_structure(struct)[source]¶ Load the structure from a pymatgen Structure object.
Note
periodic boundary conditions are set to True in all three directions.
Note
Requires the pymatgen module (version >= 3.3.5, usage of earlier versions may cause errors).
Raises: ValueError – if there are partial occupancies together with spins.
-
sites¶ Returns a list of sites.
-
-
class
aiida.orm.UpfData(filepath=None, source=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.singlefile.SinglefileDataFunction not yet documented.
-
__abstractmethods__= frozenset([])¶
-
__init__(filepath=None, source=None, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.data.upf'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.upf.UpfData.'¶
-
_query_type_string= 'data.upf.'¶
-
_validate()[source]¶ Ensure that there is one object stored in the repository, whose key matches value set for filename attr.
-
element¶
-
classmethod
from_md5(md5)[source]¶ Return a list of all UPF pseudopotentials that match a given MD5 hash.
Note that the hash has to be stored in a _md5 attribute, otherwise the pseudo will not be found.
-
classmethod
get_or_create(filepath, use_first=False, store_upf=True)[source]¶ Pass the same parameter of the init; if a file with the same md5 is found, that UpfData is returned.
Parameters: - filepath – an absolute filepath on disk
- use_first – if False (default), raise an exception if more than one potential is found. If it is True, instead, use the first available pseudopotential.
- store_upf (bool) – If false, the UpfData objects are not stored in the database. default=True.
Return (upf, created): where upf is the UpfData object, and create is either True if the object was created, or False if the object was retrieved from the DB.
-
classmethod
get_upf_groups(filter_elements=None, user=None)[source]¶ Return all names of groups of type UpfFamily, possibly with some filters.
Parameters: - filter_elements – A string or a list of strings. If present, returns only the groups that contains one Upf for every element present in the list. Default=None, meaning that all families are returned.
- user – if None (default), return the groups for all users. If defined, it should be either a DbUser instance, or a string for the username (that is, the user email).
-
md5sum¶
-
store(*args, **kwargs)[source]¶ Store the node, reparsing the file so that the md5 and the element are correctly reset.
-
upffamily_type_string= 'data.upf'¶
-
-
class
aiida.orm.NumericType(*args, **kwargs)[source]¶ Bases:
aiida.orm.nodes.data.base.BaseTypeSub class of Data to store numbers, overloading common operators (
+,*, …).-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.data.numeric'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'data.numeric.NumericType.'¶
-
_query_type_string= 'data.numeric.'¶
-
-
class
aiida.orm.CalculationNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.process.process.ProcessNodeBase class for all nodes representing the execution of a calculation process.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.calculation.calculation'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_cachable= True¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.calculation.calculation.CalculationNode.'¶
-
_query_type_string= 'process.calculation.calculation.'¶
-
_storable= True¶
-
_unstorable_message= 'storing for this node has been disabled'¶
-
inputs¶ Return an instance of NodeLinksManager to manage incoming INPUT_CALC links
The returned Manager allows you to easily explore the nodes connected to this node via an incoming INPUT_CALC link. The incoming nodes are reachable by their link labels which are attributes of the manager.
Returns: NodeLinksManager
-
outputs¶ Return an instance of NodeLinksManager to manage outgoing CREATE links
The returned Manager allows you to easily explore the nodes connected to this node via an outgoing CREATE link. The outgoing nodes are reachable by their link labels which are attributes of the manager.
Returns: NodeLinksManager
-
-
class
aiida.orm.CalcFunctionNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.utils.mixins.FunctionCalculationMixin,aiida.orm.nodes.process.calculation.calculation.CalculationNodeORM class for all nodes representing the execution of a calcfunction.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.calculation.calcfunction'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.calculation.calcfunction.CalcFunctionNode.'¶
-
_query_type_string= 'process.calculation.calcfunction.'¶
-
validate_outgoing(target, link_type, link_label)[source]¶ Validate adding a link of the given type from ourself to a given node.
A calcfunction cannot return Data, so if we receive an outgoing link to a stored Data node, that means the user created a Data node within our function body and stored it themselves or they are returning an input node. The latter use case is reserved for @workfunctions, as they can have RETURN links.
Parameters: - target – the node to which the link is going
- link_type – the link type
- link_label – the link label
Raises: - TypeError – if target is not a Node instance or link_type is not a LinkType enum
- ValueError – if the proposed link is invalid
-
-
class
aiida.orm.CalcJobNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.process.calculation.calculation.CalculationNodeORM class for all nodes representing the execution of a CalcJob.
-
CALC_JOB_STATE_KEY= 'state'¶
-
REMOTE_WORKDIR_KEY= 'remote_workdir'¶
-
RETRIEVE_LIST_KEY= 'retrieve_list'¶
-
RETRIEVE_SINGLE_FILE_LIST_KEY= 'retrieve_singlefile_list'¶
-
RETRIEVE_TEMPORARY_LIST_KEY= 'retrieve_temporary_list'¶
-
SCHEDULER_JOB_ID_KEY= 'job_id'¶
-
SCHEDULER_LAST_CHECK_TIME_KEY= 'scheduler_lastchecktime'¶
-
SCHEDULER_STATE_KEY= 'scheduler_state'¶
-
SCHEUDLER_LAST_JOB_INFO_KEY= 'last_jobinfo'¶
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.calculation.calcjob'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_cachable= True¶
-
_hash_ignored_attributes= ('queue_name', 'account', 'qos', 'priority', 'max_wallclock_seconds', 'max_memory_kb')¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.calculation.calcjob.CalcJobNode.'¶
-
_query_type_string= 'process.calculation.calcjob.'¶
-
_raw_input_folder¶ Get the input folder object.
Returns: the input folder object. Raise: NotExistent: if the raw folder hasn’t been created yet
-
_repository_base_path= 'raw_input'¶
-
_tools= None¶
-
_updatable_attributes= ('sealed', 'paused', 'checkpoints', 'exception', 'exit_message', 'exit_status', 'process_label', 'process_state', 'process_status', 'state', 'remote_workdir', 'retrieve_list', 'retrieve_temporary_list', 'retrieve_singlefile_list', 'job_id', 'scheduler_state', 'scheduler_lastchecktime', 'last_jobinfo')¶
-
_validate()[source]¶ Verify if all the input nodes are present and valid.
Raise: ValidationError: if invalid parameters are found.
-
static
_validate_retrieval_directive(directives)[source]¶ Validate a list or tuple of file retrieval directives.
Parameters: directives – a list or tuple of file retrieveal directives Raises: ValueError – if the format of the directives is invalid
-
get_authinfo()[source]¶ Return the AuthInfo that is configured for the Computer set for this node.
Returns: AuthInfo
-
get_builder_restart()[source]¶ Return a CalcJobBuilder instance, tailored for this calculation instance
This builder is a mapping of the inputs of the CalcJobNode class, supports tab-completion, automatic validation when settings values as well as automated docstrings for each input.
The fields of the builder will be pre-populated with all the inputs recorded for this instance as well as settings all the options that were explicitly set for this calculation instance.
This builder can then directly be launched again to effectively run a duplicate calculation. But more useful is that it serves as a starting point to, after changing one or more inputs, launch a similar calculation by using this already completed calculation as a starting point.
Returns: CalcJobBuilder instance
-
get_hash(ignore_errors=True, ignored_folder_content=('raw_input', ), **kwargs)[source]¶ Return the hash for this node based on its attributes.
-
get_job_id()[source]¶ Return job id that was assigned to the calculation by the scheduler.
Returns: the string representation of the scheduler job id
-
get_last_job_info()[source]¶ Return the last information asked to the scheduler about the status of the job.
Returns: a JobInfo object (that closely resembles a dictionary) or None.
-
get_option(name)[source]¶ Retun the value of an option that was set for this CalcJobNode
Parameters: name – the option name Returns: the option value or None Raises: ValueError for unknown option
-
get_options()[source]¶ Return the dictionary of options set for this CalcJobNode
Returns: dictionary of the options and their values
-
get_parser_class()[source]¶ Return the output parser object for this calculation or None if no parser is set.
Returns: a Parser class. Raise: MissingPluginError from ParserFactory no plugin is found.
-
get_remote_workdir()[source]¶ Return the path to the remote (on cluster) scratch folder of the calculation.
Returns: a string with the remote path
-
get_retrieve_list()[source]¶ Return the list of files/directories to be retrieved on the cluster after the calculation has completed.
Returns: a list of file directives
-
get_retrieve_singlefile_list()[source]¶ Return the list of files to be retrieved on the cluster after the calculation has completed.
Returns: list of single file retrieval directives
-
get_retrieve_temporary_list()[source]¶ Return list of files to be retrieved from the cluster which will be available during parsing.
Returns: a list of file directives
-
get_retrieved_node()[source]¶ Return the retrieved data folder.
Returns: the retrieved FolderData node or None if not found
-
get_scheduler_lastchecktime()[source]¶ Return the time of the last update of the scheduler state by the daemon or None if it was never set.
Returns: a datetime object or None
-
get_scheduler_state()[source]¶ Return the status of the calculation according to the cluster scheduler.
Returns: a JobState enum instance.
-
get_scheduler_stderr()[source]¶ Return the scheduler stdout output if the calculation has finished and been retrieved, None otherwise.
Returns: scheduler stdout output or None
-
get_scheduler_stdout()[source]¶ Return the scheduler stderr output if the calculation has finished and been retrieved, None otherwise.
Returns: scheduler stderr output or None
-
get_transport()[source]¶ Return the transport for this calculation.
Returns: Transport configured with the AuthInfo associated to the computer of this node
-
link_label_retrieved¶ Return the link label used for the retrieved FolderData node.
-
options¶ Return the available process options for the process class that created this node.
-
process_class¶ Return the CalcJob class that was used to create this node.
Returns: CalcJob class Raises: ValueError – if no process type is defined or it is an invalid process type string
-
res¶ To be used to get direct access to the parsed parameters.
Returns: an instance of the CalcJobResultManager. Note: a practical example on how it is meant to be used: let’s say that there is a key ‘energy’ in the dictionary of the parsed results which contains a list of floats. The command calc.res.energy will return such a list.
-
set_job_id(job_id)[source]¶ Set the job id that was assigned to the calculation by the scheduler.
Note
the id will always be stored as a string
Parameters: job_id – the id assigned by the scheduler after submission
-
set_last_job_info(last_job_info)[source]¶ Set the last job info.
Parameters: last_job_info – a JobInfo object
-
set_option(name, value)[source]¶ Set an option to the given value
Parameters: - name – the option name
- value – the value to set
Raises: ValueError for unknown option
Raises: TypeError for values with invalid type
-
set_options(options)[source]¶ Set the options for this CalcJobNode
Parameters: options – dictionary of option and their values to set
-
set_remote_workdir(remote_workdir)[source]¶ Set the absolute path to the working directory on the remote computer where the calculation is run.
Parameters: remote_workdir – absolute filepath to the remote working directory
-
set_retrieve_list(retrieve_list)[source]¶ Set the retrieve list.
This list of directives will instruct the daemon what files to retrieve after the calculation has completed. list or tuple of files or paths that should be retrieved by the daemon.
Parameters: retrieve_list – list or tuple of with filepath directives
-
set_retrieve_singlefile_list(retrieve_singlefile_list)[source]¶ Set the retrieve singlefile list.
The files will be stored as SinglefileData instances and added as output nodes to this calculation node. The format of a single file directive is a tuple or list of length 3 with the following entries:
- the link label under which the file should be added
- the SinglefileData class or sub class to use to store
- the filepath relative to the remote working directory of the calculation
Parameters: retrieve_singlefile_list – list or tuple of single file directives
-
set_retrieve_temporary_list(retrieve_temporary_list)[source]¶ Set the retrieve temporary list.
The retrieve temporary list stores files that are retrieved after completion and made available during parsing and are deleted as soon as the parsing has been completed.
Parameters: retrieve_temporary_list – list or tuple of with filepath directives
-
set_scheduler_state(state)[source]¶ Set the scheduler state.
Parameters: state – an instance of JobState
-
set_state(state)[source]¶ Set the state of the calculation job.
Parameters: state – a string with the state from aiida.common.datastructures.CalcJobState.Raise: ValueError if state is invalid
-
tools¶ Return the calculation tools that are registered for the process type associated with this calculation.
If the entry point name stored in the process_type of the CalcJobNode has an accompanying entry point in the aiida.tools.calculations entry point category, it will attempt to load the entry point and instantiate it passing the node to the constructor. If the entry point does not exist, cannot be resolved or loaded, a warning will be logged and the base CalculationTools class will be instantiated and returned.
Returns: CalculationTools instance
-
-
class
aiida.orm.ProcessNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.utils.mixins.Sealable,aiida.orm.nodes.node.NodeBase class for all nodes representing the execution of a process
This class and its subclasses serve as proxies in the database, for actual Process instances being run. The Process instance in memory will leverage an instance of this class (the exact sub class depends on the sub class of Process) to persist important information of its state to the database. This serves as a way for the user to inspect the state of the Process during its execution as well as a permanent record of its execution in the provenance graph, after the execution has terminated.
-
CHECKPOINT_KEY= 'checkpoints'¶
-
EXCEPTION_KEY= 'exception'¶
-
EXIT_MESSAGE_KEY= 'exit_message'¶
-
EXIT_STATUS_KEY= 'exit_status'¶
-
PROCESS_LABEL_KEY= 'process_label'¶
-
PROCESS_PAUSED_KEY= 'paused'¶
-
PROCESS_STATE_KEY= 'process_state'¶
-
PROCESS_STATUS_KEY= 'process_status'¶
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.process'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 102¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_cachable= False¶
-
_hash_ignored_inputs= ['CALL_CALC', 'CALL_WORK']¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.process.ProcessNode.'¶
-
_query_type_string= 'process.process.'¶
-
_unstorable_message= 'only Data, WorkflowNode, CalculationNode or their subclasses can be stored'¶
-
_updatable_attributes= ('sealed', 'paused', 'checkpoints', 'exception', 'exit_message', 'exit_status', 'process_label', 'process_state', 'process_status')¶
-
called¶ Return a list of nodes that the process called
Returns: list of process nodes called by this process
-
called_descendants¶ Return a list of all nodes that have been called downstream of this process
This will recursively find all the called processes for this process and its children.
-
caller¶ Return the process node that called this process node, or None if it does not have a caller
Returns: process node that called this process node instance or None
-
checkpoint¶ Return the checkpoint bundle set for the process
Returns: checkpoint bundle if it exists, None otherwise
-
exception¶ Return the exception of the process or None if the process is not excepted.
If the process is marked as excepted yet there is no exception attribute, an empty string will be returned.
Returns: the exception message or None
-
exit_message¶ Return the exit message of the process
Returns: the exit message
-
exit_status¶ Return the exit status of the process
Returns: the exit status, an integer exit code or None
-
is_excepted¶ Return whether the process has excepted
Excepted means that during execution of the process, an exception was raised that was not caught.
Returns: True if during execution of the process an exception occurred, False otherwise Return type: bool
-
is_failed¶ Return whether the process has failed
Failed means that the process terminated nominally but it had a non-zero exit status.
Returns: True if the process has failed, False otherwise Return type: bool
-
is_finished¶ Return whether the process has finished
Finished means that the process reached a terminal state nominally. Note that this does not necessarily mean successfully, but there were no exceptions and it was not killed.
Returns: True if the process has finished, False otherwise Return type: bool
-
is_finished_ok¶ Return whether the process has finished successfully
Finished successfully means that it terminated nominally and had a zero exit status.
Returns: True if the process has finished successfully, False otherwise Return type: bool
-
is_killed¶ Return whether the process was killed
Killed means the process was killed directly by the user or by the calling process being killed.
Returns: True if the process was killed, False otherwise Return type: bool
-
is_terminated¶ Return whether the process has terminated
Terminated means that the process has reached any terminal state.
Returns: True if the process has terminated, False otherwise Return type: bool
-
is_valid_cache¶ Return whether the node is valid for caching
Returns: True if this process node is valid to be used for caching, False otherwise
-
load_process_class()[source]¶ For nodes that were ran by a Process, the process_type will be set. This can either be an entry point string or a module path, which is the identifier for that Process. This method will attempt to load the Process class and return
-
logger¶ Get the logger of the Calculation object, so that it also logs to the DB.
Returns: LoggerAdapter object, that works like a logger, but also has the ‘extra’ embedded
-
pause()[source]¶ Mark the process as paused by setting the corresponding attribute.
This serves only to reflect that the corresponding Process is paused and so this method should not be called by anyone but the Process instance itself.
-
paused¶ Return whether the process is paused
Returns: True if the Calculation is marked as paused, False otherwise
-
process_label¶ Return the process label
Returns: the process label
-
process_state¶ Return the process state
Returns: the process state instance of ProcessState enum
-
process_status¶ Return the process status
The process status is a generic status message e.g. the reason it might be paused or when it is being killed
Returns: the process status
-
set_checkpoint(checkpoint)[source]¶ Set the checkpoint bundle set for the process
Parameters: state – string representation of the stepper state info
-
set_exception(exception)[source]¶ Set the exception of the process
Parameters: exception – the exception message
-
set_exit_message(message)[source]¶ Set the exit message of the process, if None nothing will be done
Parameters: message – a string message
-
set_exit_status(status)[source]¶ Set the exit status of the process
Parameters: state – an integer exit code or None, which will be interpreted as zero
-
set_process_state(state)[source]¶ Set the process state
Parameters: state – value or instance of ProcessState enum
-
set_process_status(status)[source]¶ Set the process status
The process status is a generic status message e.g. the reason it might be paused or when it is being killed. If status is None, the corresponding attribute will be deleted.
Parameters: status – string process status
-
-
class
aiida.orm.WorkflowNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.process.process.ProcessNodeBase class for all nodes representing the execution of a workflow process.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.workflow.workflow'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.workflow.workflow.WorkflowNode.'¶
-
_query_type_string= 'process.workflow.workflow.'¶
-
_storable= True¶
-
_unstorable_message= 'storing for this node has been disabled'¶
-
inputs¶ Return an instance of NodeLinksManager to manage incoming INPUT_WORK links
The returned Manager allows you to easily explore the nodes connected to this node via an incoming INPUT_WORK link. The incoming nodes are reachable by their link labels which are attributes of the manager.
Returns: NodeLinksManager
-
outputs¶ Return an instance of NodeLinksManager to manage outgoing RETURN links
The returned Manager allows you to easily explore the nodes connected to this node via an outgoing RETURN link. The outgoing nodes are reachable by their link labels which are attributes of the manager.
Returns: NodeLinksManager
-
-
class
aiida.orm.WorkChainNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.nodes.process.workflow.workflow.WorkflowNodeORM class for all nodes representing the execution of a WorkChain.
-
STEPPER_STATE_INFO_KEY= 'stepper_state_info'¶
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.workflow.workchain'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_cachable= False¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.workflow.workchain.WorkChainNode.'¶
-
_query_type_string= 'process.workflow.workchain.'¶
-
_updatable_attributes= ('sealed', 'paused', 'checkpoints', 'exception', 'exit_message', 'exit_status', 'process_label', 'process_state', 'process_status', 'stepper_state_info')¶
-
set_stepper_state_info(stepper_state_info)[source]¶ Set the stepper state info
Parameters: state – string representation of the stepper state info
-
stepper_state_info¶ Return the stepper state info
Returns: string representation of the stepper state info
-
-
class
aiida.orm.WorkFunctionNode(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.utils.mixins.FunctionCalculationMixin,aiida.orm.nodes.process.workflow.workflow.WorkflowNodeORM class for all nodes representing the execution of a workfunction.
-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.nodes.process.workflow.workfunction'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= 'process.workflow.workfunction.WorkFunctionNode.'¶
-
_query_type_string= 'process.workflow.workfunction.'¶
-
validate_outgoing(target, link_type, link_label)[source]¶ Validate adding a link of the given type from ourself to a given node.
A workfunction cannot create Data, so if we receive an outgoing RETURN link to an unstored Data node, that means the user created a Data node within our function body and is trying to return it. This use case should be reserved for @calcfunctions, as they can have CREATE links.
Parameters: - target – the node to which the link is going
- link_type – the link type
- link_label – the link label
Raises: - TypeError – if target is not a Node instance or link_type is not a LinkType enum
- ValueError – if the proposed link is invalid
-
-
class
aiida.orm.Node(backend=None, user=None, computer=None, **kwargs)[source]¶ Bases:
aiida.orm.entities.EntityBase class for all nodes in AiiDA.
Stores attributes starting with an underscore.
Caches files and attributes before the first save, and saves everything only on store(). After the call to store(), attributes cannot be changed.
Only after storing (or upon loading from uuid) extras can be modified and in this case they are directly set on the db.
In the plugin, also set the _plugin_type_string, to be set in the DB in the ‘type’ field.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of AuthInfo entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.nodes.node'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332343607¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
__abstractmethods__= frozenset([])¶
-
__deepcopy__(memo)[source]¶ Deep copying a Node is not supported in general, but only for the Data sub class.
-
__init__(backend=None, user=None, computer=None, **kwargs)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.nodes.node'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 40¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_add_incoming_cache(source, link_type, link_label)[source]¶ Add an incoming link to the cache.
Parameters: - source – the node from which the link is coming
- link_type – the link type
- link_label – the link label
Raises: aiida.common.UniquenessError – if the given link triple already exists in the cache
-
_add_outputs_from_cache(cache_node)[source]¶ Replicate the output links and nodes from the cached node onto this node.
-
_attrs_cache= None¶
-
_cachable= True¶
-
_get_same_node()[source]¶ Returns a stored node from which the current Node can be cached or None if it does not exist
If a node is returned it is a valid cache, meaning its _aiida_hash extra matches self.get_hash(). If there are multiple valid matches, the first one is returned. If no matches are found, None is returned.
Returns: a stored Node instance with the same hash as this code or None
-
_hash_ignored_attributes= ()¶
-
_incoming_cache= None¶
-
_logger= <logging.Logger object>¶
-
_plugin_type_string= ''¶
-
_query_type_string= ''¶
-
_repository= None¶
-
_repository_base_path= 'path'¶
-
_storable= False¶
-
_store(with_transaction=True)[source]¶ Store the node in the database while saving its attributes and repository directory.
Parameters: with_transaction – if False, do not use a transaction because the caller will already have opened one.
-
_store_from_cache(cache_node, with_transaction)[source]¶ Store this node from an existing cache node.
-
_unstorable_message= 'only Data, WorkflowNode, CalculationNode or their subclasses can be stored'¶
-
_updatable_attributes= ()¶
-
_validate()[source]¶ Check if the attributes and files retrieved from the database are valid.
Must be able to work even before storing: therefore, use the get_attr and similar methods that automatically read either from the DB or from the internal attribute cache.
For the base class, this is always valid. Subclasses will reimplement this. In the subclass, always call the super()._validate() method first!
-
add_comment(content, user=None)[source]¶ Add a new comment.
Parameters: - content – string with comment
- user – the user to associate with the comment, will use default if not supplied
Returns: the newly created comment
-
add_incoming(source, link_type, link_label)[source]¶ Add a link of the given type from a given node to ourself.
Parameters: - source – the node from which the link is coming
- link_type – the link type
- link_label – the link label
Raises: - TypeError – if source is not a Node instance or link_type is not a LinkType enum
- ValueError – if the proposed link is invalid
-
append_to_attr(key, value, clean=True)[source]¶ Append value to an attribute of the Node (in the DbAttribute table).
Parameters: - key – key name of “list-type” attribute If attribute doesn’t exist, it is created.
- value – the value to append to the list
- clean – whether to clean the value WARNING: when set to False, storing will throw errors for any data types not recognized by the db backend
Raises: aiida.common.ValidationError – if the key is not valid, e.g. it contains the separator symbol
-
attributes¶ Return the attributes dictionary.
Note
This will fetch all the attributes from the database which can be a heavy operation. If you only need the keys or some values, use the iterators attributes_keys and attributes_items, or the getters get_attribute and get_attributes instead.
Returns: the attributes as a dictionary
-
attributes_items()[source]¶ Return an iterator over the attribute items.
Returns: an iterator with attribute key value pairs
-
attributes_keys()[source]¶ Return an iterator over the attribute keys.
Returns: an iterator with attribute keys
-
class_node_type= ''¶
-
computer¶ Return the computer of this node.
Returns: the computer or None Return type: Computer or None
-
ctime¶ Return the node ctime.
Returns: the ctime
-
delete_attribute(key, stored_check=True)[source]¶ Delete an attribute.
Deleting attributes on a stored node is forbidden unless stored_check is set to False.
Parameters: - key – name of the attribute
- stored_check – boolean, if True skips the check whether the node is stored
Raises: - AttributeError – if the attribute does not exist
- aiida.common.ModificationNotAllowed – if the node is stored and stored_check=False
-
delete_attributes(keys)[source]¶ Delete multiple attributes.
Parameters: keys – names of the attributes to delete Raises: AttributeError – if at least on of the attribute does not exist
-
delete_extra(key)[source]¶ Delete an extra.
Deleting extras on unstored nodes is forbidden.
Parameters: key – name of the extra Raises: AttributeError – if the extra does not exist
-
delete_extras(keys)[source]¶ Delete multiple extras.
Parameters: keys – names of the extras to delete Raises: AttributeError – if at least on of the extra does not exist
-
delete_object(key, force=False)[source]¶ Delete the object from the repository.
Warning
If the repository belongs to a stored node, a ModificationNotAllowed exception will be raised. This check can be avoided by using the force flag, but this should be used with extreme caution!
Parameters: - key – fully qualified identifier for the object within the repository
- force – boolean, if True, will skip the mutability check
Raises: aiida.common.ModificationNotAllowed – if repository is immutable and force=False
-
description¶ Return the node description.
Returns: the description
-
extras¶ Return the extras dictionary.
Note
This will fetch all the extras from the database which can be a heavy operation. If you only need the keys or some values, use the iterators extras_keys and extras_items, or the getters get_extra and get_extras instead.
Returns: the extras as a dictionary
-
extras_items()[source]¶ Return an iterator over the extra items.
Returns: an iterator with extra key value pairs
-
extras_keys()[source]¶ Return an iterator over the attribute keys.
Returns: an iterator with attribute keys
-
classmethod
from_backend_entity(backend_entity)[source]¶ Construct an entity from a backend entity instance
Parameters: backend_entity – the backend entity Returns: an AiiDA entity instance
-
get_all_same_nodes()[source]¶ Return a list of stored nodes which match the type and hash of the current node.
All returned nodes are valid caches, meaning their _aiida_hash extra matches self.get_hash().
-
get_attribute(key, default=())[source]¶ Return an attribute.
Parameters: - key – name of the attribute
- default – return this value instead of raising if the extra does not exist
Returns: the value of the attribute
Raises: AttributeError – if the attribute does not exist
-
get_attributes(keys)[source]¶ Return a set of attributes.
Parameters: keys – names of the attributes Returns: the values of the attributes Raises: AttributeError – if at least one attribute does not exist
-
get_cache_source()[source]¶ Return the UUID of the node that was used in creating this node from the cache, or None if it was not cached.
Returns: source node UUID or None
-
get_comment(identifier)[source]¶ Return a comment corresponding to the given identifier.
Parameters: identifier – the comment pk
Raises: - aiida.common.NotExistent – if the comment with the given id does not exist
- aiida.common.MultipleObjectsError – if the id cannot be uniquely resolved to a comment
Returns: the comment
-
get_comments()[source]¶ Return a sorted list of comments for this node.
Returns: the list of comments, sorted by pk
-
get_description()[source]¶ Return a string with a description of the node.
Returns: a description string Return type: str
-
get_extra(key, default=())[source]¶ Return an extra.
Parameters: - key – name of the extra
- default – return this value instead of raising if the extra does not exist
Returns: the value of the extra
Raises: AttributeError – if the extra does not exist
-
get_extras(keys)[source]¶ Return a set of extras.
Parameters: keys – names of the extras Returns: the values of the extras Raises: AttributeError – if at least one extra does not exist
-
get_hash(ignore_errors=True, **kwargs)[source]¶ Return the hash for this node based on its attributes.
-
get_incoming(node_class=None, link_type=(), link_label_filter=None)[source]¶ Return a list of link triples that are (directly) incoming into this node.
Parameters: - node_class – If specified, should be a class or tuple of classes, and it filters only elements of that specific type (or a subclass of ‘type’)
- link_type – If specified should be a string or tuple to get the inputs of this link type, if None then returns all inputs of all link types.
- link_label_filter – filters the incoming nodes by its link label. Here wildcards (% and _) can be passed in link label filter as we are using “like” in QB.
-
get_object(key)[source]¶ Return the object identified by key.
Parameters: key – fully qualified identifier for the object within the repository Returns: a File named tuple representing the object located at key
-
get_object_content(key)[source]¶ Return the content of a object identified by key.
Parameters: key – fully qualified identifier for the object within the repository
-
get_outgoing(node_class=None, link_type=(), link_label_filter=None)[source]¶ Return a list of link triples that are (directly) outgoing of this node.
Parameters: - node_class – If specified, should be a class or tuple of classes, and it filters only elements of that specific type (or a subclass of ‘type’)
- link_type – If specified should be a string or tuple to get the inputs of this link type, if None then returns all outputs of all link types.
- link_label_filter – filters the outgoing nodes by its link label. Here wildcards (% and _) can be passed in link label filter as we are using “like” in QB.
-
static
get_schema()[source]¶ - Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: get schema of the node
-
get_stored_link_triples(node_class=None, link_type=(), link_label_filter=None, link_direction='incoming')[source]¶ Return the list of stored link triples directly incoming to or outgoing of this node.
Note this will only return link triples that are stored in the database. Anything in the cache is ignored.
Parameters: - node_class – If specified, should be a class, and it filters only elements of that (subclass of) type
- link_type – Only get inputs of this link type, if empty tuple then returns all inputs of all link types.
- link_label_filter – filters the incoming nodes by its link label. This should be a regex statement as one would pass directly to a QuerBuilder filter statement with the ‘like’ operation.
- link_direction – incoming or outgoing to get the incoming or outgoing links, respectively.
-
has_cached_links()[source]¶ Feturn whether there are unstored incoming links in the cache.
Returns: boolean, True when there are links in the incoming cache, False otherwise
-
initialize()[source]¶ Initialize internal variables for the backend node
This needs to be called explicitly in each specific subclass implementation of the init.
-
is_created_from_cache¶ Return whether this node was created from a cached node.
Returns: boolean, True if the node was created by cloning a cached node, False otherwise
-
is_valid_cache¶ Hook to exclude certain Node instances from being considered a valid cache.
-
label¶ Return the node label.
Returns: the label
-
list_object_names(key=None)[source]¶ Return a list of the object names contained in this repository, optionally in the given sub directory.
Parameters: key – fully qualified identifier for the object within the repository Returns: a list of File named tuples representing the objects present in directory with the given key
-
list_objects(key=None)[source]¶ Return a list of the objects contained in this repository, optionally in the given sub directory.
Parameters: key – fully qualified identifier for the object within the repository Returns: a list of File named tuples representing the objects present in directory with the given key
-
logger¶ Return the logger configured for this Node.
Returns: Logger object
-
mtime¶ Return the node mtime.
Returns: the mtime
-
node_type¶ Return the node type.
Returns: the node type
-
open(key, mode='r')[source]¶ Open a file handle to an object stored under the given key.
Parameters: - key – fully qualified identifier for the object within the repository
- mode – the mode under which to open the handle
-
process_type¶ Return the node process type.
Returns: the process type
-
public¶ Return the node public attribute.
Returns: the public attribute
-
put_object_from_file(path, key, mode='w', encoding='utf8', force=False)[source]¶ Store a new object under key with contents of the file located at path on this file system.
Warning
If the repository belongs to a stored node, a ModificationNotAllowed exception will be raised. This check can be avoided by using the force flag, but this should be used with extreme caution!
Parameters: - path – absolute path of file whose contents to copy to the repository
- key – fully qualified identifier for the object within the repository
- mode – the file mode with which the object will be written
- encoding – the file encoding with which the object will be written
- force – boolean, if True, will skip the mutability check
Raises: aiida.common.ModificationNotAllowed – if repository is immutable and force=False
-
put_object_from_filelike(handle, key, mode='w', encoding='utf8', force=False)[source]¶ Store a new object under key with contents of filelike object handle.
Warning
If the repository belongs to a stored node, a ModificationNotAllowed exception will be raised. This check can be avoided by using the force flag, but this should be used with extreme caution!
Parameters: - handle – filelike object with the content to be stored
- key – fully qualified identifier for the object within the repository
- mode – the file mode with which the object will be written
- encoding – the file encoding with which the object will be written
- force – boolean, if True, will skip the mutability check
Raises: aiida.common.ModificationNotAllowed – if repository is immutable and force=False
-
put_object_from_tree(path, key=None, contents_only=True, force=False)[source]¶ Store a new object under key with the contents of the directory located at path on this file system.
Warning
If the repository belongs to a stored node, a ModificationNotAllowed exception will be raised. This check can be avoided by using the force flag, but this should be used with extreme caution!
Parameters: - path – absolute path of directory whose contents to copy to the repository
- key – fully qualified identifier for the object within the repository
- contents_only – boolean, if True, omit the top level directory of the path and only copy its contents.
- force – boolean, if True, will skip the mutability check
Raises: aiida.common.ModificationNotAllowed – if repository is immutable and force=False
-
remove_comment(identifier)[source]¶ Delete an existing comment.
Parameters: identifier – the comment pk
-
reset_attributes(attributes)[source]¶ Reset the attributes.
Note
This will completely reset any existing attributes and replace them with the new dictionary.
Parameters: attributes – the new attributes to set
-
reset_extras(extras)[source]¶ Reset the extras.
Note
This will completely reset any existing extras and replace them with the new dictionary.
Parameters: extras – the new extras to set
-
set_attribute(key, value, clean=True, stored_check=True)[source]¶ Set an attribute to the given value.
Setting attributes on a stored node is forbidden unless stored_check is set to False.
Parameters: - key – name of the attribute
- value – value of the attribute
- clean – boolean, when True will clean the value before passing it to the backend
- stored_check – boolean, if True skips the check whether the node is stored
Raises: aiida.common.ModificationNotAllowed – if the node is stored and stored_check=False
-
set_attributes(attributes)[source]¶ Set attributes.
Note
This will override any existing attributes that are present in the new dictionary.
Parameters: attributes – the new attributes to set
-
set_extra(key, value)[source]¶ Set an extra to the given value.
Setting extras on unstored nodes is forbidden.
Parameters: - key – name of the extra
- value – value of the extra
Raises: aiida.common.ModificationNotAllowed – if the node is not stored
-
set_extras(extras)[source]¶ Set extras.
Note
This will override any existing extras that are present in the new dictionary.
Parameters: extras – the new extras to set
-
store(with_transaction=True, use_cache=None)[source]¶ Store the node in the database while saving its attributes and repository directory.
After being called attributes cannot be changed anymore! Instead, extras can be changed only AFTER calling this store() function.
Note: After successful storage, those links that are in the cache, and for which also the parent node is already stored, will be automatically stored. The others will remain unstored. Parameters: with_transaction – if False, do not use a transaction because the caller will already have opened one.
-
store_all(with_transaction=True, use_cache=None)[source]¶ Store the node, together with all input links.
Unstored nodes from cached incoming linkswill also be stored.
Parameters: with_transaction – if False, do not use a transaction because the caller will already have opened one.
-
update_comment(identifier, content)[source]¶ Update the content of an existing comment.
Parameters: - identifier – the comment pk
- content – the new comment content
Raises: - aiida.common.NotExistent – if the comment with the given id does not exist
- aiida.common.MultipleObjectsError – if the id cannot be uniquely resolved to a comment
-
user¶ Return the user of this node.
Returns: the user Return type: User
-
uuid¶ Return the node UUID.
Returns: the string representation of the UUID Return type: str
-
validate_incoming(source, link_type, link_label)[source]¶ Validate adding a link of the given type from a given node to ourself.
This function will first validate the types of the inputs, followed by the node and link types and validate whether in principle a link of that type between the nodes of these types is allowed.the
Subsequently, the validity of the “degree” of the proposed link is validated, which means validating the number of links of the given type from the given node type is allowed.
Parameters: - source – the node from which the link is coming
- link_type – the link type
- link_label – the link label
Raises: - TypeError – if source is not a Node instance or link_type is not a LinkType enum
- ValueError – if the proposed link is invalid
-
validate_outgoing(target, link_type, link_label)[source]¶ Validate adding a link of the given type from ourself to a given node.
The validity of the triple (source, link, target) should be validated in the validate_incoming call. This method will be called afterwards and can be overriden by subclasses to add additional checks that are specific to that subclass.
Parameters: - target – the node to which the link is going
- link_type – the link type
- link_label – the link label
Raises: - TypeError – if target is not a Node instance or link_type is not a LinkType enum
- ValueError – if the proposed link is invalid
-
verify_are_parents_stored()[source]¶ Verify that all parent nodes are already stored.
Raises: aiida.common.ModificationNotAllowed – if one of the source nodes of incoming links is not stored.
-
version¶ Return the node version.
Returns: the version
-
class
-
class
aiida.orm.QueryBuilder(backend=None, **kwargs)[source]¶ Bases:
objectThe class to query the AiiDA database.
Usage:
from aiida.orm.querybuilder import QueryBuilder qb = QueryBuilder() # Querying nodes: qb.append(Node) # retrieving the results: results = qb.all()
-
_EDGE_TAG_DELIM= '--'¶
-
_VALID_PROJECTION_KEYS= ('func', 'cast')¶
-
__dict__= dict_proxy({'_add_to_projections': <function _add_to_projections>, 'all': <function all>, '__str__': <function __str__>, '_EDGE_TAG_DELIM': '--', 'one': <function one>, '_join_group_members': <function _join_group_members>, '_join_node_comment': <function _join_node_comment>, '__dict__': <attribute '__dict__' of 'QueryBuilder' objects>, '_join_log_node': <function _join_log_node>, '_get_function_map': <function _get_function_map>, '__weakref__': <attribute '__weakref__' of 'QueryBuilder' objects>, 'children': <function children>, '_join_inputs': <function _join_inputs>, 'order_by': <function order_by>, '_get_ormclass': <function _get_ormclass>, 'distinct': <function distinct>, 'set_debug': <function set_debug>, '_join_to_computer_used': <function _join_to_computer_used>, 'dict': <function dict>, '_join_node_log': <function _join_node_log>, 'parents': <function parents>, '__doc__': '\n The class to query the AiiDA database.\n\n Usage::\n\n from aiida.orm.querybuilder import QueryBuilder\n qb = QueryBuilder()\n # Querying nodes:\n qb.append(Node)\n # retrieving the results:\n results = qb.all()\n\n ', 'iterdict': <function iterdict>, '_build_order': <function _build_order>, '_VALID_PROJECTION_KEYS': ('func', 'cast'), '_get_json_compatible': <function _get_json_compatible>, 'outputs': <function outputs>, '_join_descendants_recursive': <function _join_descendants_recursive>, 'count': <function count>, '_join_computer': <function _join_computer>, 'get_json_compatible_queryhelp': <function get_json_compatible_queryhelp>, '_get_unique_tag': <function _get_unique_tag>, 'get_alias': <function get_alias>, 'limit': <function limit>, '_check_dbentities': <staticmethod object>, '_deprecate': <function _deprecate>, '__module__': 'aiida.orm.querybuilder', '_join_outputs': <function _join_outputs>, '_join_ancestors_recursive': <function _join_ancestors_recursive>, '_join_comment_user': <function _join_comment_user>, 'get_query': <function get_query>, 'get_aliases': <function get_aliases>, '_build_filters': <function _build_filters>, 'add_filter': <function add_filter>, 'append': <function append>, 'get_used_tags': <function get_used_tags>, '_join_user_comment': <function _join_user_comment>, '_build_projections': <function _build_projections>, '__init__': <function __init__>, 'iterall': <function iterall>, '_add_process_type_filter': <function _add_process_type_filter>, '_join_comment_node': <function _join_comment_node>, 'inputs': <function inputs>, '_join_group_user': <function _join_group_user>, 'add_projection': <function add_projection>, '_process_filters': <function _process_filters>, '_join_user_group': <function _join_user_group>, 'get_aiida_entity_res': <staticmethod object>, 'inject_query': <function inject_query>, 'offset': <function offset>, '_get_projectable_entity': <function _get_projectable_entity>, '_join_creator_of': <function _join_creator_of>, 'except_if_input_to': <function except_if_input_to>, '_build': <function _build>, '_join_created_by': <function _join_created_by>, '_get_tag_from_specification': <function _get_tag_from_specification>, '_get_connecting_node': <function _get_connecting_node>, '_join_groups': <function _join_groups>, '_add_type_filter': <function _add_type_filter>, 'first': <function first>})¶
-
__init__(backend=None, **kwargs)[source]¶ Instantiates a QueryBuilder instance.
Which backend is used decided here based on backend-settings (taken from the user profile). This cannot be overriden so far by the user.
Parameters: - debug (bool) – Turn on debug mode. This feature prints information on the screen about the stages of the QueryBuilder. Does not affect results.
- path (list) – A list of the vertices to traverse. Leave empty if you plan on using the method
QueryBuilder.append(). - filters – The filters to apply. You can specify the filters here, when appending to the query
using
QueryBuilder.append()or even later usingQueryBuilder.add_filter(). Check latter gives API-details. - project – The projections to apply. You can specify the projections here, when appending to the query
using
QueryBuilder.append()or even later usingQueryBuilder.add_projection(). Latter gives you API-details. - limit (int) – Limit the number of rows to this number. Check
QueryBuilder.limit()for more information. - offset (int) – Set an offset for the results returned. Details in
QueryBuilder.offset(). - order_by – How to order the results. As the 2 above, can be set also at later stage,
check
QueryBuilder.order_by()for more information.
-
__module__= 'aiida.orm.querybuilder'¶
-
__str__()[source]¶ When somebody hits: print(QueryBuilder) or print(str(QueryBuilder)) I want to print the SQL-query. Because it looks cool…
-
__weakref__¶ list of weak references to the object (if defined)
-
_add_process_type_filter(tagspec, classifiers, subclassing)[source]¶ Add a filter based on process type.
Parameters: - tagspec – The tag, which has to exist already as a key in self._filters
- classifiers – a dictionary with classifiers
- subclassing – if True, allow for subclasses of the process type
Note: This function handles the case when process_type_string is None.
-
_add_to_projections(alias, projectable_entity_name, cast=None, func=None)[source]¶ Parameters: - alias (
sqlalchemy.orm.util.AliasedClass) – A instance of sqlalchemy.orm.util.AliasedClass, alias for an ormclass - projectable_entity_name – User specification of what to project. Appends to query’s entities what the user wants to project (have returned by the query)
- alias (
-
_add_type_filter(tagspec, classifiers, subclassing)[source]¶ Add a filter based on type.
Parameters: - tagspec – The tag, which has to exist already as a key in self._filters
- classifiers – a dictionary with classifiers
- subclassing – if True, allow for subclasses of the ormclass
-
_build_filters(alias, filter_spec)[source]¶ Recurse through the filter specification and apply filter operations.
Parameters: - alias – The alias of the ORM class the filter will be applied on
- filter_spec – the specification as given by the queryhelp
Returns: an instance of sqlalchemy.sql.elements.BinaryExpression.
-
static
_check_dbentities(entities_cls_joined, entities_cls_to_join, relationship)[source]¶ Parameters: - entities_cls_joined – A tuple of the aliased class passed as joined_entity and the ormclass that was expected
- entities_cls_joined – A tuple of the aliased class passed as entity_to_join and the ormclass that was expected
- relationship (str) – The relationship between the two entities to make the Exception comprehensible
-
_deprecate(function, deprecated_name, preferred_name, version='1.0.0a5')[source]¶ Wrapper to return a decorated functon which will print a deprecation warning when it is called.
Specifically for when an old relationship type is used. Note that it is the way of calling the function which is deprecated, not the function itself
Parameters: - function – a deprecated function to call
- deprecated_name – the name which is deprecated
- preferred_name – the new name which is preferred
- version – aiida version for which this takes effect.
-
_get_connecting_node(index, joining_keyword=None, joining_value=None, **kwargs)[source]¶ Parameters: - querydict – A dictionary specifying how the current node is linked to other nodes.
- index – Index of this node within the path specification
- joining_keyword – the relation on which to join
- joining_value – the tag of the nodes to be joined
-
_get_function_map()[source]¶ Map relationship type keywords to functions The new mapping (since 1.0.0a5) is a two level dictionary. The first level defines the entity which has been passed to the qb.append functon, and the second defines the relationship with respect to a given tag.
-
_get_json_compatible(inp)[source]¶ Parameters: inp – The input value that will be converted. Recurses into each value if inp is an iterable.
-
_get_ormclass(cls, ormclass_type_string)[source]¶ Get ORM classifiers from either class(es) or ormclass_type_string(s).
Parameters: - cls – a class or tuple/set/list of classes that are either AiiDA ORM classes or backend ORM classes.
- ormclass_type_string – type string for ORM class
Returns: the ORM class as well as a dictionary with additional classifier strings
Handles the case of lists as well.
-
_get_tag_from_specification(specification)[source]¶ Parameters: specification – If that is a string, I assume the user has deliberately specified it with tag=specification. In that case, I simply check that it’s not a duplicate. If it is a class, I check if it’s in the _cls_to_tag_map!
-
_get_unique_tag(classifiers)[source]¶ Using the function get_tag_from_type, I get a tag. I increment an index that is appended to that tag until I have an unused tag. This function is called in
QueryBuilder.append()when autotag is set to True.Parameters: classifiers (dict) – Classifiers, containing the string that defines the type of the AiiDA ORM class. For subclasses of Node, this is the Node._plugin_type_string, for other they are as defined as returned by
QueryBuilder._get_ormclass().Can also be a list of dictionaries, when multiple classes are passed to QueryBuilder.append
Returns: A tag as a string (it is a single string also when passing multiple classes).
-
_join_ancestors_recursive(joined_entity, entity_to_join, isouterjoin, filter_dict, expand_path=False)[source]¶ joining ancestors using the recursive functionality :TODO: Move the filters to be done inside the recursive query (for example on depth) :TODO: Pass an option to also show the path, if this is wanted.
-
_join_comment_node(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased comment
- entity_to_join – aliased node
-
_join_comment_user(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased comment
- entity_to_join – aliased user
-
_join_computer(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An entity that can use a computer (eg a node)
- entity_to_join – aliased dbcomputer entity
-
_join_created_by(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – the aliased user you want to join to
- entity_to_join – the (aliased) node or group in the DB to join with
-
_join_creator_of(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – the aliased node
- entity_to_join – the aliased user to join to that node
-
_join_descendants_recursive(joined_entity, entity_to_join, isouterjoin, filter_dict, expand_path=False)[source]¶ joining descendants using the recursive functionality :TODO: Move the filters to be done inside the recursive query (for example on depth) :TODO: Pass an option to also show the path, if this is wanted.
-
_join_group_members(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) ORMclass that is a group in the database
- entity_to_join – The (aliased) ORMClass that is a node and member of the group
joined_entity and entity_to_join are joined via the table_groups_nodes table. from joined_entity as group to enitity_to_join as node. (enitity_to_join is with_group joined_entity)
-
_join_group_user(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased dbgroup
- entity_to_join – aliased dbuser
-
_join_groups(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) node in the database
- entity_to_join – The (aliased) Group
joined_entity and entity_to_join are joined via the table_groups_nodes table. from joined_entity as node to enitity_to_join as group. (enitity_to_join is a group with_node joined_entity)
-
_join_inputs(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) ORMclass that is an output
- entity_to_join – The (aliased) ORMClass that is an input.
joined_entity and entity_to_join are joined with a link from joined_entity as output to enitity_to_join as input (enitity_to_join is with_outgoing joined_entity)
-
_join_log_node(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased log
- entity_to_join – aliased node
-
_join_node_comment(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased node
- entity_to_join – aliased comment
-
_join_node_log(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased node
- entity_to_join – aliased log
-
_join_outputs(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) ORMclass that is an input
- entity_to_join – The (aliased) ORMClass that is an output.
joined_entity and entity_to_join are joined with a link from joined_entity as input to enitity_to_join as output (enitity_to_join is with_incoming joined_entity)
-
_join_to_computer_used(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – the (aliased) computer entity
- entity_to_join – the (aliased) node entity
-
_join_user_comment(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased user
- entity_to_join – aliased comment
-
_join_user_group(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased user
- entity_to_join – aliased group
-
add_filter(tagspec, filter_spec)[source]¶ Adding a filter to my filters.
Parameters: - tagspec – The tag, which has to exist already as a key in self._filters
- filter_spec – The specifications for the filter, has to be a dictionary
Usage:
qb = QueryBuilder() # Instantiating the QueryBuilder instance qb.append(Node, tag='node') # Appending a Node #let's put some filters: qb.add_filter('node',{'id':{'>':12}}) # 2 filters together: qb.add_filter('node',{'label':'foo', 'uuid':{'like':'ab%'}}) # Now I am overriding the first filter I set: qb.add_filter('node',{'id':13})
-
add_projection(tag_spec, projection_spec)[source]¶ Adds a projection
Parameters: - tag_spec – A valid specification for a tag
- projection_spec – The specification for the projection. A projection is a list of dictionaries, with each dictionary containing key-value pairs where the key is database entity (e.g. a column / an attribute) and the value is (optional) additional information on how to process this database entity.
If the given projection_spec is not a list, it will be expanded to a list. If the listitems are not dictionaries, but strings (No additional processing of the projected results desired), they will be expanded to dictionaries.
Usage:
qb = QueryBuilder() qb.append(StructureData, tag='struc') # Will project the uuid and the kinds qb.add_projection('struc', ['uuid', 'attributes.kinds'])
The above example will project the uuid and the kinds-attribute of all matching structures. There are 2 (so far) special keys.
The single star * will project the ORM-instance:
qb = QueryBuilder() qb.append(StructureData, tag='struc') # Will project the ORM instance qb.add_projection('struc', '*') print type(qb.first()[0]) # >>> aiida.orm.nodes.data.structure.StructureData
The double start ** projects all possible projections of this entity:
QueryBuilder().append(StructureData,tag=’s’, project=’**’).limit(1).dict()[0][‘s’].keys()
# >>> u’user_id, description, ctime, label, extras, mtime, id, attributes, dbcomputer_id, nodeversion, type, public, uuid’
Be aware that the result of ** depends on the backend implementation.
-
all(batch_size=None)[source]¶ Executes the full query with the order of the rows as returned by the backend. the order inside each row is given by the order of the vertices in the path and the order of the projections for each vertice in the path.
Parameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Leave the default (None) if speed is not critical or if you don’t know what you’re doing! Returns: a list of lists of all projected entities.
-
append(cls=None, entity_type=None, tag=None, filters=None, project=None, subclassing=True, edge_tag=None, edge_filters=None, edge_project=None, outerjoin=False, **kwargs)[source]¶ Any iterative procedure to build the path for a graph query needs to invoke this method to append to the path.
Parameters: - cls –
The Aiida-class (or backend-class) defining the appended vertice. Also supports a tuple/list of classes. This results in an all instances of this class being accepted in a query. However the classes have to have the same orm-class for the joining to work. I.e. both have to subclasses of Node. Valid is:
cls=(StructureData, Dict)
This is invalid:
cls=(Group, Node) - entity_type – The node type of the class, if cls is not given. Also here, a tuple or list is accepted.
- autotag (bool) – Whether to find automatically a unique tag. If this is set to True (default False),
- tag (str) – A unique tag. If none is given, I will create a unique tag myself.
- filters – Filters to apply for this vertex.
See
add_filter(), the method invoked in the background, or usage examples for details. - project – Projections to apply. See usage examples for details.
More information also in
add_projection(). - subclassing (bool) – Whether to include subclasses of the given class (default True). E.g. Specifying a ProcessNode as cls will include CalcJobNode, WorkChainNode, CalcFunctionNode, etc..
- outerjoin (bool) – If True, (default is False), will do a left outerjoin instead of an inner join
- edge_tag (str) – The tag that the edge will get. If nothing is specified (and there is a meaningful edge) the default is tag1–tag2 with tag1 being the entity joining from and tag2 being the entity joining to (this entity).
- edge_filters (str) – The filters to apply on the edge. Also here, details in
add_filter(). - edge_project (str) – The project from the edges. API-details in
add_projection().
A small usage example how this can be invoked:
qb = QueryBuilder() # Instantiating empty querybuilder instance qb.append(cls=StructureData) # First item is StructureData node # The # next node in the path is a PwCalculation, with # the structure joined as an input qb.append( cls=PwCalculation, with_incoming=StructureData )
Returns: self Return type: aiida.orm.QueryBuilder- cls –
-
count()[source]¶ Counts the number of rows returned by the backend.
Returns: the number of rows as an integer
-
dict(batch_size=None)[source]¶ Executes the full query with the order of the rows as returned by the backend. the order inside each row is given by the order of the vertices in the path and the order of the projections for each vertice in the path.
Parameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Leave the default (None) if speed is not critical or if you don’t know what you’re doing! Returns: a list of dictionaries of all projected entities. Each dictionary consists of key value pairs, where the key is the tag of the vertice and the value a dictionary of key-value pairs where key is the entity description (a column name or attribute path) and the value the value in the DB. Usage:
qb = QueryBuilder() qb.append( StructureData, tag='structure', filters={'uuid':{'==':myuuid}}, ) qb.append( Node, with_ancestors='structure', project=['entity_type', 'id'], # returns entity_type (string) and id (string) tag='descendant' ) # Return the dictionaries: print "qb.iterdict()" for d in qb.iterdict(): print '>>>', d
results in the following output:
qb.iterdict() >>> {'descendant': { 'entity_type': u'calculation.job.quantumespresso.pw.PwCalculation.', 'id': 7716} } >>> {'descendant': { 'entity_type': u'data.remote.RemoteData.', 'id': 8510} }
-
distinct()[source]¶ Asks for distinct rows, which is the same as asking the backend to remove duplicates. Does not execute the query!
If you want a distinct query:
qb = QueryBuilder() # append stuff! qb.append(...) qb.append(...) ... qb.distinct().all() #or qb.distinct().dict()
Returns: self
-
except_if_input_to(calc_class)[source]¶ Makes counterquery based on the own path, only selecting entries that have been input to calc_class
Parameters: calc_class – The calculation class to check against Returns: self
-
first()[source]¶ Executes query asking for one instance. Use as follows:
qb = QueryBuilder(**queryhelp) qb.first()
Returns: One row of results as a list
-
get_alias(tag)[source]¶ In order to continue a query by the user, this utility function returns the aliased ormclasses.
Parameters: tag – The tag for a vertice in the path Returns: the alias given for that vertice
-
get_json_compatible_queryhelp()[source]¶ Makes the queryhelp a json-compatible dictionary.
In this way,the queryhelp can be stored in the database or a json-object, retrieved or shared and used later. See this usage:
qb = QueryBuilder(limit=3).append(StructureData, project='id').order_by({StructureData:'id'}) queryhelp = qb.get_json_compatible_queryhelp() # Now I could save this dictionary somewhere and use it later: qb2=QueryBuilder(**queryhelp) # This is True if no change has been made to the database. # Note that such a comparison can only be True if the order of results is enforced qb.all()==qb2.all()
Returns: the json-compatible queryhelp
-
get_query()[source]¶ Instantiates and manipulates a sqlalchemy.orm.Query instance if this is needed. First, I check if the query instance is still valid by hashing the queryhelp. In this way, if a user asks for the same query twice, I am not recreating an instance.
Returns: an instance of sqlalchemy.orm.Query that is specific to the backend used.
Returns a list of all the vertices that are being used. Some parameter allow to select only subsets. :param bool vertices: Defaults to True. If True, adds the tags of vertices to the returned list :param bool edges: Defaults to True. If True, adds the tags of edges to the returnend list.
Returns: A list of all tags, including (if there is) also the tag give for the edges
-
inject_query(query)[source]¶ Manipulate the query an inject it back. This can be done to add custom filters using SQLA. :param query: A sqlalchemy.orm.Query instance
-
iterall(batch_size=100)[source]¶ Same as
all(), but returns a generator. Be aware that this is only safe if no commit will take place during this transaction. You might also want to read the SQLAlchemy documentation on http://docs.sqlalchemy.org/en/latest/orm/query.html#sqlalchemy.orm.query.Query.yield_perParameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Returns: a generator of lists
-
iterdict(batch_size=100)[source]¶ Same as
dict(), but returns a generator. Be aware that this is only safe if no commit will take place during this transaction. You might also want to read the SQLAlchemy documentation on http://docs.sqlalchemy.org/en/latest/orm/query.html#sqlalchemy.orm.query.Query.yield_perParameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Returns: a generator of dictionaries
-
limit(limit)[source]¶ Set the limit (nr of rows to return)
Parameters: limit (int) – integers of number of rows of rows to return
-
offset(offset)[source]¶ Set the offset. If offset is set, that many rows are skipped before returning. offset = 0 is the same as omitting setting the offset. If both offset and limit appear, then offset rows are skipped before starting to count the limit rows that are returned.
Parameters: offset (int) – integers of nr of rows to skip
-
one()[source]¶ Executes the query asking for exactly one results. Will raise an exception if this is not the case :raises: MultipleObjectsError if more then one row can be returned :raises: NotExistent if no result was found
-
order_by(order_by)[source]¶ Set the entity to order by
Parameters: order_by – This is a list of items, where each item is a dictionary specifies what to sort for an entity In each dictionary in that list, keys represent valid tags of entities (tables), and values are list of columns.
Usage:
#Sorting by id (ascending): qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':['id']}) # or #Sorting by id (ascending): qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':[{'id':{'order':'asc'}}]}) # for descending order: qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':[{'id':{'order':'desc'}}]}) # or (shorter) qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':[{'id':'desc'}]})
-
-
class
aiida.orm.User(email, first_name='', last_name='', institution='', backend=None)[source]¶ Bases:
aiida.orm.entities.EntityAiiDA User
-
class
Collection(*args, **kwargs)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of users stored in a backend
-
UNDEFINED= 'UNDEFINED'¶
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.users'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332174120¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_default_user= None¶
-
_gorg¶ alias of
Collection
-
get_default()[source]¶ Get the current default user
Returns: The default user Return type: aiida.orm.User
-
get_or_create(**kwargs)[source]¶ Get the existing user with a given email address or create an unstored one
Parameters: kwargs – The properties of the user to get or create Returns: The corresponding user object Return type: aiida.orm.UserRaises: aiida.common.exceptions.MultipleObjectsError,aiida.common.exceptions.NotExistent
-
-
REQUIRED_FIELDS= ['first_name', 'last_name', 'institution']¶
-
__init__(email, first_name='', last_name='', institution='', backend=None)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.users'¶
-
date_joined¶
-
email¶
-
first_name¶
-
static
get_schema()[source]¶ Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: schema of the user
-
get_short_name()[source]¶ Return the user short name (typically, this returns the email)
Returns: The short name
-
institution¶
-
is_active¶
-
last_login¶
-
last_name¶
-
static
normalize_email(email)[source]¶ Normalize the address by lowercasing the domain part of the email address.
Taken from Django.
-
password¶
-
class
-
aiida.orm.load_code(identifier=None, pk=None, uuid=None, label=None, sub_classes=None, query_with_dashes=True)[source]¶ Load a Code instance by one of its identifiers: pk, uuid or label
If the type of the identifier is unknown simply pass it without a keyword and the loader will attempt to automatically infer the type.
Parameters: - identifier – pk (integer), uuid (string) or label (string) of a Code
- pk – pk of a Code
- uuid – uuid of a Code, or the beginning of the uuid
- label – label of a Code
- sub_classes – an optional tuple of orm classes to narrow the queryset. Each class should be a strict sub class of the ORM class of the given entity loader.
- query_with_dashes (bool) – allow to query for a uuid with dashes
Returns: the Code instance
Raises: - ValueError – if none or more than one of the identifiers are supplied
- TypeError – if the provided identifier has the wrong type
- aiida.common.NotExistent – if no matching Code is found
- aiida.common.MultipleObjectsError – if more than one Code was found
-
aiida.orm.load_computer(identifier=None, pk=None, uuid=None, label=None, sub_classes=None, query_with_dashes=True)[source]¶ Load a Computer instance by one of its identifiers: pk, uuid or label
If the type of the identifier is unknown simply pass it without a keyword and the loader will attempt to automatically infer the type.
Parameters: - identifier – pk (integer), uuid (string) or label (string) of a Computer
- pk – pk of a Computer
- uuid – uuid of a Computer, or the beginning of the uuid
- label – label of a Computer
- sub_classes – an optional tuple of orm classes to narrow the queryset. Each class should be a strict sub class of the ORM class of the given entity loader.
- query_with_dashes (bool) – allow to query for a uuid with dashes
Returns: the Computer instance
Raises: - ValueError – if none or more than one of the identifiers are supplied
- TypeError – if the provided identifier has the wrong type
- aiida.common.NotExistent – if no matching Computer is found
- aiida.common.MultipleObjectsError – if more than one Computer was found
-
aiida.orm.load_group(identifier=None, pk=None, uuid=None, label=None, sub_classes=None, query_with_dashes=True)[source]¶ Load a Group instance by one of its identifiers: pk, uuid or label
If the type of the identifier is unknown simply pass it without a keyword and the loader will attempt to automatically infer the type.
Parameters: - identifier – pk (integer), uuid (string) or label (string) of a Group
- pk – pk of a Group
- uuid – uuid of a Group, or the beginning of the uuid
- label – label of a Group
- sub_classes – an optional tuple of orm classes to narrow the queryset. Each class should be a strict sub class of the ORM class of the given entity loader.
- query_with_dashes (bool) – allow to query for a uuid with dashes
Returns: the Group instance
Raises: - ValueError – if none or more than one of the identifiers are supplied
- TypeError – if the provided identifier has the wrong type
- aiida.common.NotExistent – if no matching Group is found
- aiida.common.MultipleObjectsError – if more than one Group was found
-
aiida.orm.load_node(identifier=None, pk=None, uuid=None, label=None, sub_classes=None, query_with_dashes=True)[source]¶ Load a node by one of its identifiers: pk or uuid. If the type of the identifier is unknown simply pass it without a keyword and the loader will attempt to infer the type
Parameters: - identifier – pk (integer) or uuid (string)
- pk – pk of a node
- uuid – uuid of a node, or the beginning of the uuid
- label – label of a Node
- sub_classes – an optional tuple of orm classes to narrow the queryset. Each class should be a strict sub class of the ORM class of the given entity loader.
- query_with_dashes (bool) – allow to query for a uuid with dashes
Returns: the node instance
Raises: - ValueError – if none or more than one of the identifiers are supplied
- TypeError – if the provided identifier has the wrong type
- aiida.common.NotExistent – if no matching Node is found
- aiida.common.MultipleObjectsError – if more than one Node was found
Submodules¶
Authinfo objects and functions
-
class
aiida.orm.authinfos.AuthInfo(computer, user, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityBase class to map a DbAuthInfo, that contains computer configuration specific to a given user (authorization info and other metadata, like how often to check on a given computer etc.)
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of AuthInfo entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.authinfos'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332168886¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
PROPERTY_WORKDIR= 'workdir'¶
-
__init__(computer, user, backend=None)[source]¶ Create a AuthInfo given a computer and a user
Parameters: - computer – a Computer instance
- user – a User instance
Returns: an AuthInfo object associated with the given computer and user
-
__module__= 'aiida.orm.authinfos'¶
-
computer¶
-
enabled¶ Is the computer enabled for this user?
Return type: bool
-
get_property(name)[source]¶ Get an authinfo property
Parameters: name – the property name Returns: the property value
-
get_workdir()[source]¶ Get the workdir; defaults to the value of the corresponding computer, if not explicitly set
Returns: the workdir Return type: str
-
set_auth_params(auth_params)[source]¶ Set the dictionary of auth_params
Parameters: auth_params – a dictionary with the new auth_params
-
set_property(name, value)[source]¶ Set an authinfo property
Parameters: - name – the property name
- value – the property value
-
user¶
-
class
-
class
aiida.orm.autogroup.Autogroup[source]¶ Bases:
objectAn object used for the autogrouping of objects. The autogrouping is checked by the Node.store() method. In the store(), the Node will check if current_autogroup is != None. If so, it will call Autogroup.is_to_be_grouped, and decide whether to put it in a group. Such autogroups are going to be of the VERDIAUTOGROUP_TYPE.
The exclude/include lists, can have values ‘all’ if you want to include/exclude all classes. Otherwise, they are lists of strings like: calculation.quantumespresso.pw, data.array.kpoints, … i.e.: a string identifying the base class, than the path to the class as in Calculation/Data -Factories
-
__dict__= dict_proxy({'get_exclude_with_subclasses': <function get_exclude_with_subclasses>, 'set_exclude': <function set_exclude>, '__module__': 'aiida.orm.autogroup', 'get_group_name': <function get_group_name>, 'set_include_with_subclasses': <function set_include_with_subclasses>, '_validate': <function _validate>, 'get_include': <function get_include>, 'set_include': <function set_include>, 'set_group_name': <function set_group_name>, 'is_to_be_grouped': <function is_to_be_grouped>, 'get_exclude': <function get_exclude>, '__dict__': <attribute '__dict__' of 'Autogroup' objects>, 'set_exclude_with_subclasses': <function set_exclude_with_subclasses>, '__weakref__': <attribute '__weakref__' of 'Autogroup' objects>, '__doc__': "\n An object used for the autogrouping of objects.\n The autogrouping is checked by the Node.store() method.\n In the store(), the Node will check if current_autogroup is != None.\n If so, it will call Autogroup.is_to_be_grouped, and decide whether to put it in a group.\n Such autogroups are going to be of the VERDIAUTOGROUP_TYPE.\n\n The exclude/include lists, can have values 'all' if you want to include/exclude all classes.\n Otherwise, they are lists of strings like: calculation.quantumespresso.pw, data.array.kpoints, ...\n i.e.: a string identifying the base class, than the path to the class as in Calculation/Data -Factories\n ", 'get_include_with_subclasses': <function get_include_with_subclasses>})¶
-
__module__= 'aiida.orm.autogroup'¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_validate(param, is_exact=True)[source]¶ Used internally to verify the sanity of exclude, include lists
-
get_exclude_with_subclasses()[source]¶ Return the list of classes to exclude from autogrouping. Will also exclude their derived subclasses
-
get_group_name()[source]¶ Get the name of the group. If no group name was set, it will set a default one by itself.
-
get_include_with_subclasses()[source]¶ Return the list of classes to include in the autogrouping. Will also include their derived subclasses.
-
is_to_be_grouped(the_class)[source]¶ Return whether the given class has to be included in the autogroup according to include/exclude list
Return (bool): True if the_class is to be included in the autogroup
-
Comment objects and functions
-
class
aiida.orm.comments.Comment(node, user, content=None, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityBase class to map a DbComment that represents a comment attached to a certain Node.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of Comment entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.comments'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332295371¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
__init__(node, user, content=None, backend=None)[source]¶ Create a Comment for a given node and user
Parameters: - node – a Node instance
- user – a User instance
- content – the comment content
Returns: a Comment object associated to the given node and user
-
__module__= 'aiida.orm.comments'¶
-
content¶
-
ctime¶
-
mtime¶
-
node¶
-
user¶
-
class
Module for Computer entities
-
class
aiida.orm.computers.Computer(name, hostname, description='', transport_type='', scheduler_type='', workdir=None, enabled_state=True, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityBase class to map a node in the DB + its permanent repository counterpart.
Stores attributes starting with an underscore.
Caches files and attributes before the first save, and saves everything only on store(). After the call to store(), attributes cannot be changed.
Only after storing (or upon loading from uuid) metadata can be modified and in this case they are directly set on the db.
In the plugin, also set the _plugin_type_string, to be set in the DB in the ‘type’ field.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of Computer entries.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.computers'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332306077¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
-
PROPERTY_MINIMUM_SCHEDULER_POLL_INTERVAL= 'minimum_scheduler_poll_interval'¶
-
PROPERTY_MINIMUM_SCHEDULER_POLL_INTERVAL__DEFAULT= 10.0¶
-
PROPERTY_SHEBANG= 'shebang'¶
-
PROPERTY_WORKDIR= 'workdir'¶
-
__init__(name, hostname, description='', transport_type='', scheduler_type='', workdir=None, enabled_state=True, backend=None)[source]¶ Construct a new computer
-
__module__= 'aiida.orm.computers'¶
-
classmethod
_default_mpiprocs_per_machine_validator(def_cpus_per_machine)[source]¶ Validates the default number of CPUs per machine (node)
-
_logger= <logging.Logger object>¶
-
_mpirun_command_validator(mpirun_cmd)[source]¶ Validates the mpirun_command variable. MUST be called after properly checking for a valid scheduler.
-
configure(user=None, **kwargs)[source]¶ Configure a computer for a user with valid auth params passed via kwargs
Parameters: user – the user to configure the computer for Kwargs: the configuration keywords with corresponding values Returns: the authinfo object for the configured user Return type: aiida.orm.AuthInfo
-
delete_property(name, raise_exception=True)[source]¶ Delete a property from this computer
Parameters: - name – the name of the property
- raise_exception – if True raise if the property does not exist, otherwise return None
-
description¶ Get a description of the computer
Returns: the description Return type: str
-
full_text_info¶ Return a (multiline) string with a human-readable detailed information on this computer.
Rypte: str
-
get_authinfo(user)[source]¶ Return the aiida.orm.authinfo.AuthInfo instance for the given user on this computer, if the computer is configured for the given user.
Parameters: user – a User instance. Returns: a AuthInfo instance Raises: aiida.common.NotExistent – if the computer is not configured for the given user.
-
get_configuration(user=None)[source]¶ Get the configuration of computer for the given user as a dictionary
Parameters: user ( aiida.orm.User) – the user to to get the configuration for. Uses default user if None
-
get_default_mpiprocs_per_machine()[source]¶ Return the default number of CPUs per machine (node) for this computer, or None if it was not set.
-
get_description()[source]¶ Get the description for this computer
Returns: the description Return type: str
-
get_minimum_job_poll_interval()[source]¶ Get the minimum interval between subsequent requests to update the list of jobs currently running on this computer.
Returns: The minimum interval (in seconds) Return type: float
-
get_mpirun_command()[source]¶ Return the mpirun command. Must be a list of strings, that will be then joined with spaces when submitting.
I also provide a sensible default that may be ok in many cases.
-
get_property(name, *args)[source]¶ Get a property of this computer
Parameters: - name – the property name
- args – additional arguments
Returns: the property value
-
get_scheduler()[source]¶ Get a scheduler instance for this computer
Returns: the scheduler instance Return type: aiida.schedulers.Scheduler
-
get_scheduler_type()[source]¶ Get the scheduler type for this computer
Returns: the scheduler type Return type: str
-
static
get_schema()[source]¶ - Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: get schema of the computer
-
get_transport(user=None)[source]¶ Return a Transport class, configured with all correct parameters. The Transport is closed (meaning that if you want to run any operation with it, you have to open it first (i.e., e.g. for a SSH transport, you have to open a connection). To do this you can call
transports.open(), or simply run within awithstatement:transport = Computer.get_transport() with transport: print(transports.whoami())
Parameters: user – if None, try to obtain a transport for the default user. Otherwise, pass a valid User. Returns: a (closed) Transport, already configured with the connection parameters to the supercomputer, as configured with verdi computer configurefor the user specified as a parameteruser.
-
get_transport_class()[source]¶ Get the transport class for this computer. Can be used to instantiate a transport instance.
Returns: the transport class
-
get_transport_type()[source]¶ Get the current transport type for this computer
Returns: the transport type Return type: str
-
get_workdir()[source]¶ Get the working directory for this computer :return: The currently configured working directory :rtype: str
-
hostname¶
-
is_user_configured(user)[source]¶ Is the user configured on this computer?
Parameters: user – the user to check Returns: True if configured, False otherwise Return type: bool
-
is_user_enabled(user)[source]¶ Is the given user enabled to run on this computer?
Parameters: user – the user to check Returns: True if enabled, False otherwise Return type: bool
-
label¶ The computer label
-
logger¶
-
name¶
-
set_default_mpiprocs_per_machine(def_cpus_per_machine)[source]¶ Set the default number of CPUs per machine (node) for this computer. Accepts None if you do not want to set this value.
-
set_description(val)[source]¶ Set the description for this computer
Parameters: val (str) – the new description
-
set_enabled_state(enabled)[source]¶ Set the enable state for this computer
Parameters: enabled – True if enabled, False otherwise
-
set_hostname(val)[source]¶ Set the hostname of this computer :param val: The new hostname :type val: str
-
set_minimum_job_poll_interval(interval)[source]¶ Set the minimum interval between subsequent requests to update the list of jobs currently running on this computer.
Parameters: interval (float) – The minimum interval in seconds
-
set_mpirun_command(val)[source]¶ Set the mpirun command. It must be a list of strings (you can use string.split() if you have a single, space-separated string).
-
set_property(name, value)[source]¶ Set a property on this computer
Parameters: - name – the property name
- value – the new value
-
set_transport_type(transport_type)[source]¶ Set the transport type for this computer
Parameters: transport_type (str) – the new transport type
-
store()[source]¶ Store the computer in the DB.
Differently from Nodes, a computer can be re-stored if its properties are to be changed (e.g. a new mpirun command, etc.)
-
validate()[source]¶ Check if the attributes and files retrieved from the DB are valid. Raise a ValidationError if something is wrong.
Must be able to work even before storing: therefore, use the get_attr and similar methods that automatically read either from the DB or from the internal attribute cache.
For the base class, this is always valid. Subclasses will reimplement this. In the subclass, always call the super().validate() method first!
-
class
Module for converting backend entities into frontend, ORM, entities
-
class
aiida.orm.convert.ConvertIterator(backend_iterator)[source]¶ Bases:
_abcoll.Iterator,_abcoll.SizedIterator that converts backend entities into frontend ORM entities as needed
See
aiida.orm.Group.nodes()for an example.-
__abstractmethods__= frozenset([])¶
-
__module__= 'aiida.orm.convert'¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_negative_cache_version= 102¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
Module for all common top level AiiDA entity classes and methods
-
class
aiida.orm.entities.Entity(backend_entity)[source]¶ Bases:
objectAn AiiDA entity
-
class
Collection(backend, entity_class)¶ Bases:
typing.GenericContainer class that represents the collection of objects of a particular type.
-
_COLLECTIONS= <aiida.common.datastructures.LazyStore object>¶
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__call__(backend)¶ Create a new objects collection using a different backend
Parameters: backend – the backend to use Returns: a new collection with the different backend
-
__dict__= dict_proxy({'__module__': 'aiida.orm.entities', u'__origin__': None, 'all': <function all>, '_gorg': aiida.orm.entities.Collection, '__dict__': <attribute '__dict__' of 'Collection' objects>, 'query': <function query>, '__weakref__': <attribute '__weakref__' of 'Collection' objects>, 'find': <function find>, '__init__': <function __init__>, 'backend': <property object>, '_abc_cache': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache_version': 35, 'entity_type': <property object>, '__abstractmethods__': frozenset([]), '__call__': <function __call__>, '__args__': None, '__doc__': 'Container class that represents the collection of objects of a particular type.', '__tree_hash__': 5926332092883, 'get': <function get>, '__parameters__': (~EntityType,), '__orig_bases__': (typing.Generic[~EntityType],), '_COLLECTIONS': <aiida.common.datastructures.LazyStore object>, 'get_collection': <classmethod object>, '__next_in_mro__': <type 'object'>, u'__extra__': None, '_abc_registry': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache': <_weakrefset.WeakSet object>})¶
-
__extra__= None¶
-
__init__(backend, entity_class)¶ Construct a new entity collection
-
__module__= 'aiida.orm.entities'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (typing.Generic[~EntityType],)¶
-
__origin__= None¶
-
__parameters__= (~EntityType,)¶
-
__tree_hash__= 5926332092883¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 35¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
all()¶ Get all entities in this collection
Returns: A collection of users matching the criteria
-
backend¶ Return the backend.
-
entity_type¶
-
find(filters=None, order_by=None, limit=None)¶ Find collection entries matching the filter criteria
Parameters: - filters – the keyword value pair filters to match
- order_by (list) – a list of (key, direction) pairs specifying the sort order
- limit (int) – the maximum number of results to return
Returns: a list of resulting matches
Return type: list
-
get(**filters)¶ Get a single collection entry that matches the filter criteria
Parameters: filters – the filters identifying the object to get Returns: the entry
-
classmethod
get_collection(entity_type, backend)¶ Get the collection for a given entity type and backend instance
Parameters: - entity_type – the entity type e.g. User, Computer, etc
- backend – the backend instance to get the collection for
Returns: the collection instance
-
query()¶ Get a query builder for the objects of this collection
Returns: a new query builder instance Return type: aiida.orm.QueryBuilder
-
-
__dict__= dict_proxy({'__module__': 'aiida.orm.entities', 'get': <classmethod object>, '__dict__': <attribute '__dict__' of 'Entity' objects>, 'is_stored': <property object>, '_objects': None, 'initialize': <function new_fn>, '__weakref__': <attribute '__weakref__' of 'Entity' objects>, 'id': <property object>, '__init__': <function __init__>, 'backend': <property object>, 'from_backend_entity': <classmethod object>, 'uuid': <property object>, 'init_from_backend': <function init_from_backend>, 'Collection': aiida.orm.entities.Collection, 'backend_entity': <property object>, 'objects': <aiida.common.lang.classproperty object>, 'pk': <property object>, '__doc__': 'An AiiDA entity', 'store': <function store>})¶
-
__init__(backend_entity)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.entities'¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_objects= None¶
-
backend¶ Get the backend for this entity :return: the backend instance
-
backend_entity¶ Get the implementing class for this object
Returns: the class model
-
classmethod
from_backend_entity(backend_entity)[source]¶ Construct an entity from a backend entity instance
Parameters: backend_entity – the backend entity Returns: an AiiDA entity instance
-
id¶ Get the id for this entity. This is unique only amongst entities of this type for a particular backend
Returns: the entity id
-
init_from_backend(backend_entity)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
initialize(*args, **kwargs)¶
-
is_stored¶ Is the computer stored?
Returns: True if stored, False otherwise Return type: bool
-
objects¶ A class that, when used as a decorator, works as if the two decorators @property and @classmethod where applied together (i.e., the object works as a property, both for the Class and for any of its instance; and is called with the class cls rather than with the instance as its first argument).
-
pk¶ Get the primary key for this entity
Note
Deprecated because the backend need not be a database and so principle key doesn’t always make sense. Use id() instead.
Returns: the principal key
-
uuid¶ Get the UUID for this entity. This is unique across all entities types and backends
Returns: the entity uuid Return type: uuid.UUID
-
class
-
class
aiida.orm.entities.Collection(backend, entity_class)[source]¶ Bases:
typing.GenericContainer class that represents the collection of objects of a particular type.
-
_COLLECTIONS= <aiida.common.datastructures.LazyStore object>¶
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__call__(backend)[source]¶ Create a new objects collection using a different backend
Parameters: backend – the backend to use Returns: a new collection with the different backend
-
__dict__= dict_proxy({'__module__': 'aiida.orm.entities', u'__origin__': None, 'all': <function all>, '_gorg': aiida.orm.entities.Collection, '__dict__': <attribute '__dict__' of 'Collection' objects>, 'query': <function query>, '__weakref__': <attribute '__weakref__' of 'Collection' objects>, 'find': <function find>, '__init__': <function __init__>, 'backend': <property object>, '_abc_cache': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache_version': 35, 'entity_type': <property object>, '__abstractmethods__': frozenset([]), '__call__': <function __call__>, '__args__': None, '__doc__': 'Container class that represents the collection of objects of a particular type.', '__tree_hash__': 5926332092883, 'get': <function get>, '__parameters__': (~EntityType,), '__orig_bases__': (typing.Generic[~EntityType],), '_COLLECTIONS': <aiida.common.datastructures.LazyStore object>, 'get_collection': <classmethod object>, '__next_in_mro__': <type 'object'>, u'__extra__': None, '_abc_registry': <_weakrefset.WeakSet object>, '_abc_generic_negative_cache': <_weakrefset.WeakSet object>})¶
-
__extra__= None¶
-
__module__= 'aiida.orm.entities'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (typing.Generic[~EntityType],)¶
-
__origin__= None¶
-
__parameters__= (~EntityType,)¶
-
__tree_hash__= 5926332092883¶
-
__weakref__¶ list of weak references to the object (if defined)
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 35¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
all()[source]¶ Get all entities in this collection
Returns: A collection of users matching the criteria
-
backend¶ Return the backend.
-
entity_type¶
-
find(filters=None, order_by=None, limit=None)[source]¶ Find collection entries matching the filter criteria
Parameters: - filters – the keyword value pair filters to match
- order_by (list) – a list of (key, direction) pairs specifying the sort order
- limit (int) – the maximum number of results to return
Returns: a list of resulting matches
Return type: list
-
get(**filters)[source]¶ Get a single collection entry that matches the filter criteria
Parameters: filters – the filters identifying the object to get Returns: the entry
-
classmethod
get_collection(entity_type, backend)[source]¶ Get the collection for a given entity type and backend instance
Parameters: - entity_type – the entity type e.g. User, Computer, etc
- backend – the backend instance to get the collection for
Returns: the collection instance
-
query()[source]¶ Get a query builder for the objects of this collection
Returns: a new query builder instance Return type: aiida.orm.QueryBuilder
-
AiiDA Group entites
-
class
aiida.orm.groups.Group(label=None, user=None, description='', type_string=<GroupTypeString.USER: 'user'>, backend=None, name=None, type=None)[source]¶ Bases:
aiida.orm.entities.EntityAn AiiDA ORM implementation of group of nodes.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionCollection of Groups
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.groups'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332329563¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
get_or_create(label=None, **kwargs)[source]¶ Try to retrieve a group from the DB with the given arguments; create (and store) a new group if such a group was not present yet.
Returns: (group, created) where group is the group (new or existing, in any case already stored) and created is a boolean saying
-
-
__init__(label=None, user=None, description='', type_string=<GroupTypeString.USER: 'user'>, backend=None, name=None, type=None)[source]¶ Create a new group. Either pass a dbgroup parameter, to reload ad group from the DB (and then, no further parameters are allowed), or pass the parameters for the Group creation.
Parameters: - dbgroup – the dbgroup object, if you want to reload the group from the DB rather than creating a new one.
- label – The group label, required on creation
- description – The group description (by default, an empty string)
- user – The owner of the group (by default, the automatic user)
- type_string – a string identifying the type of group (by default, an empty string, indicating an user-defined group.
-
__module__= 'aiida.orm.groups'¶
-
add_nodes(nodes)[source]¶ Add a node or a set of nodes to the group.
Note: all the nodes and the group itself have to be stored. Parameters: nodes – a single Node or a list of Nodes
-
count()[source]¶ Return the number of entities in this group.
Returns: integer number of entities contained within the group
-
description¶ Returns: the description of the group as a string
-
classmethod
get(**kwargs)[source]¶ Custom get for group which can be used to get a group with the given attributes
Parameters: kwargs – the attributes to match the group to Returns: the group Return type: aiida.orm.Group
-
classmethod
get_from_string(string)[source]¶ Get a group from a string. If only the label is provided, without colons, only user-defined groups are searched; add ‘:type_str’ after the group label to choose also the type of the group equal to ‘type_str’ (e.g. ‘data.upf’, ‘import’, etc.)
Raises: - ValueError – if the group type does not exist.
- aiida.common.NotExistent – if the group is not found.
-
classmethod
get_or_create(backend=None, **kwargs)[source]¶ Try to retrieve a group from the DB with the given arguments; create (and store) a new group if such a group was not present yet.
Returns: (group, created) where group is the group (new or existing, in any case already stored) and created is a boolean saying
-
static
get_schema()[source]¶ - Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: get schema of the group
-
is_empty¶ Return whether the group is empty, i.e. it does not contain any nodes.
Returns: boolean, True if it contains no nodes, False otherwise
-
label¶ Returns: the label of the group as a string
-
name¶ Returns: the label of the group as a string
-
nodes¶ Return a generator/iterator that iterates over all nodes and returns the respective AiiDA subclasses of Node, and also allows to ask for the number of nodes in the group using len().
-
remove_nodes(nodes)[source]¶ Remove a node or a set of nodes to the group.
Note: all the nodes and the group itself have to be stored. Parameters: nodes – a single Node or a list of Nodes
-
type¶ Returns: the string defining the type of the group
-
type_string¶ Returns: the string defining the type of the group
-
user¶ Returns: the user associated with this group
-
uuid¶ Returns: a string with the uuid
-
class
-
class
aiida.orm.groups.GroupTypeString[source]¶ Bases:
enum.EnumA simple enum of allowed group type strings.
-
IMPORTGROUP_TYPE= 'auto.import'¶
-
UPFGROUP_TYPE= 'data.upf'¶
-
USER= 'user'¶
-
VERDIAUTOGROUP_TYPE= 'auto.run'¶
-
__module__= 'aiida.orm.groups'¶
-
-
class
aiida.orm.importexport.HTMLGetLinksParser(filter_extension=None)[source]¶ Bases:
HTMLParser.HTMLParser-
__init__(filter_extension=None)[source]¶ If a filter_extension is passed, only links with extension matching the given one will be returned.
-
__module__= 'aiida.orm.importexport'¶
-
-
class
aiida.orm.importexport.MyWritingZipFile(zipfile, fname)[source]¶ Bases:
object-
__dict__= dict_proxy({'write': <function write>, '__module__': 'aiida.orm.importexport', '__weakref__': <attribute '__weakref__' of 'MyWritingZipFile' objects>, '__exit__': <function __exit__>, '__dict__': <attribute '__dict__' of 'MyWritingZipFile' objects>, 'close': <function close>, '__enter__': <function __enter__>, 'open': <function open>, '__doc__': None, '__init__': <function __init__>})¶
-
__module__= 'aiida.orm.importexport'¶
-
__weakref__¶ list of weak references to the object (if defined)
-
-
class
aiida.orm.importexport.ZipFolder(zipfolder_or_fname, mode=None, subfolder='.', use_compression=True, allowZip64=True)[source]¶ Bases:
objectTo improve: if zipfile is closed, do something (e.g. add explicit open method, rename open to openfile, set _zipfile to None, …)
-
__dict__= dict_proxy({'__module__': 'aiida.orm.importexport', '__exit__': <function __exit__>, 'open': <function open>, '__enter__': <function __enter__>, '_get_internal_path': <function _get_internal_path>, 'pwd': <property object>, '__weakref__': <attribute '__weakref__' of 'ZipFolder' objects>, '__init__': <function __init__>, '__dict__': <attribute '__dict__' of 'ZipFolder' objects>, 'close': <function close>, 'insert_path': <function insert_path>, '__doc__': '\n To improve: if zipfile is closed, do something\n (e.g. add explicit open method, rename open to openfile,\n set _zipfile to None, ...)\n ', 'get_subfolder': <function get_subfolder>})¶
-
__init__(zipfolder_or_fname, mode=None, subfolder='.', use_compression=True, allowZip64=True)[source]¶ Parameters: - zipfolder_or_fname – either another ZipFolder instance, of which you want to get a subfolder, or a filename to create.
- mode – the file mode; see the zipfile.ZipFile docs for valid strings. Note: can be specified only if zipfolder_or_fname is a string (the filename to generate)
- subfolder – the subfolder that specified the “current working directory” in the zip file. If zipfolder_or_fname is a ZipFolder, subfolder is a relative path from zipfolder_or_fname.subfolder
- use_compression – either True, to compress files in the Zip, or False if you just want to pack them together without compressing. It is ignored if zipfolder_or_fname is a ZipFolder isntance.
-
__module__= 'aiida.orm.importexport'¶
-
__weakref__¶ list of weak references to the object (if defined)
-
pwd¶
-
-
aiida.orm.importexport._merge_comment(incoming_comment, comment_mode)[source]¶ Merge comment according comment_mode :return: New UUID if new Comment should be created, else None.
-
aiida.orm.importexport.deserialize_field(k, v, fields_info, import_unique_ids_mappings, foreign_ids_reverse_mappings)[source]¶
-
aiida.orm.importexport.export(what, outfile='export_data.aiida.tar.gz', overwrite=False, silent=False, **kwargs)[source]¶ Export the entries passed in the ‘what’ list to a file tree. :todo: limit the export to finished or failed calculations. :param what: a list of entity instances; they can belong to different models/entities. :param input_forward: Follow forward INPUT links (recursively) when calculating the node set to export. :param create_reversed: Follow reversed CREATE links (recursively) when calculating the node set to export. :param return_reversed: Follow reversed RETURN links (recursively) when calculating the node set to export. :param call_reversed: Follow reversed CALL links (recursively) when calculating the node set to export. :param allowed_licenses: a list or a function. If a list, then checks whether all licenses of Data nodes are in the list. If a function, then calls function for licenses of Data nodes expecting True if license is allowed, False otherwise. :param forbidden_licenses: a list or a function. If a list, then checks whether all licenses of Data nodes are in the list. If a function, then calls function for licenses of Data nodes expecting True if license is allowed, False otherwise. :param outfile: the filename of the file on which to export :param overwrite: if True, overwrite the output file without asking. if False, raise an IOError in this case. :param silent: suppress debug print
Raises: IOError – if overwrite==False and the filename already exists.
-
aiida.orm.importexport.export_tree(what, folder, allowed_licenses=None, forbidden_licenses=None, silent=False, input_forward=False, create_reversed=True, return_reversed=False, call_reversed=False, include_comments=True, include_logs=True, **kwargs)[source]¶ Export the entries passed in the ‘what’ list to a file tree. :todo: limit the export to finished or failed calculations. :param what: a list of entity instances; they can belong to different models/entities. :param folder: a
Folderobject :param input_forward: Follow forward INPUT links (recursively) when calculating the node set to export. :param create_reversed: Follow reversed CREATE links (recursively) when calculating the node set to export. :param return_reversed: Follow reversed RETURN links (recursively) when calculating the node set to export. :param call_reversed: Follow reversed CALL links (recursively) when calculating the node set to export. :param allowed_licenses: a list or a function. If a list, then checks whether all licenses of Data nodes are in the list. If a function, then calls function for licenses of Data nodes expecting True if license is allowed, False otherwise. :param forbidden_licenses: a list or a function. If a list, then checks whether all licenses of Data nodes are in the list. If a function, then calls function for licenses of Data nodes expecting True if license is allowed, False otherwise. :param include_comments: Bool: In-/exclude export of comments for given node(s). Default: True, include comments in export (as well as relevant users). :param include_logs: Bool: In-/exclude export of logs for given node(s). Default: True, include logs in export. :param silent: suppress debug prints :raises LicensingException: if any node is licensed under forbidden license
-
aiida.orm.importexport.export_zip(what, outfile='testzip', overwrite=False, silent=False, use_compression=True, **kwargs)[source]¶
-
aiida.orm.importexport.fill_in_query(partial_query, originating_entity_str, current_entity_str, tag_suffixes=[], entity_separator='_')[source]¶ This function recursively constructs QueryBuilder queries that are needed for the SQLA export function. To manage to construct such queries, the relationship dictionary is consulted (which shows how to reference different AiiDA entities in QueryBuilder. To find the dependencies of the relationships of the exported data, the get_all_fields_info_sqla (which described the exported schema and its dependencies) is consulted.
-
aiida.orm.importexport.get_all_fields_info()[source]¶ This method returns a description of the field names that should be used to describe the entity properties. Apart from of the listing of the fields per properties, it also shown the dependencies among different entities (and on which fields). It is also shown/return the unique identifiers used per entity.
-
aiida.orm.importexport.get_all_parents_dj(node_pks)[source]¶ Get all the parents of given nodes :param node_pks: one node pk or an iterable of node pks :return: a list of aiida objects with all the parents of the nodes
-
aiida.orm.importexport.get_valid_import_links(url)[source]¶ Open the given URL, parse the HTML and return a list of valid links where the link file has a .aiida extension.
-
aiida.orm.importexport.import_data(in_path, group=None, silent=False, **kwargs)[source]¶ Import exported AiiDA environment to the AiiDA database. If the ‘in_path’ is a folder, calls extract_tree; otherwise, tries to detect the compression format (zip, tar.gz, tar.bz2, …) and calls the correct function. :param in_path: the path to a file or folder that can be imported in AiiDA :param extras_mode_existing: 3 letter code that will identify what to do with the extras import. The first letter acts on extras that are present in the original node and not present in the imported node. Can be either: ‘k’ (keep it) or ‘n’ (do not keep it). The second letter acts on the imported extras that are not present in the original node. Can be either: ‘c’ (create it) or ‘n’ (do not create it). The third letter defines what to do in case of a name collision. Can be either: ‘l’ (leave the old value), ‘u’ (update with a new value), ‘d’ (delete the extra), ‘a’ (ask what to do if the content is different). :param extras_mode_new: ‘import’ to import extras of new nodes or ‘none’ to ignore them :param comment_node_existing: Similar to param extras_mode_existing, but for Comments. :param comment_mode_new: Similar to param extras_mode_new, but for Comments.
-
aiida.orm.importexport.import_data_dj(in_path, user_group=None, ignore_unknown_nodes=False, extras_mode_existing='kcl', extras_mode_new='import', comment_mode='newest', silent=False)[source]¶ Import exported AiiDA environment to the AiiDA database. If the ‘in_path’ is a folder, calls extract_tree; otherwise, tries to detect the compression format (zip, tar.gz, tar.bz2, …) and calls the correct function. :param in_path: the path to a file or folder that can be imported in AiiDA :param extras_mode_existing: 3 letter code that will identify what to do with the extras import. The first letter acts on extras that are present in the original node and not present in the imported node. Can be either: ‘k’ (keep it) or ‘n’ (do not keep it). The second letter acts on the imported extras that are not present in the original node. Can be either: ‘c’ (create it) or ‘n’ (do not create it). The third letter defines what to do in case of a name collision. Can be either: ‘l’ (leave the old value), ‘u’ (update with a new value), ‘d’ (delete the extra), ‘a’ (ask what to do if the content is different). :param extras_mode_new: ‘import’ to import extras of new nodes or ‘none’ to ignore them :param comment_mode: Comment import modes (when same UUIDs are found): ‘newest’: Will keep the Comment with the most recent modification time (mtime) ‘overwrite’: Will overwrite existing Comments with the ones from the import file
-
aiida.orm.importexport.import_data_sqla(in_path, user_group=None, ignore_unknown_nodes=False, extras_mode_existing='kcl', extras_mode_new='import', comment_mode='newest', silent=False)[source]¶ Import exported AiiDA environment to the AiiDA database. If the ‘in_path’ is a folder, calls extract_tree; otherwise, tries to detect the compression format (zip, tar.gz, tar.bz2, …) and calls the correct function. :param in_path: the path to a file or folder that can be imported in AiiDA :param extras_mode_existing: 3 letter code that will identify what to do with the extras import. The first letter acts on extras that are present in the original node and not present in the imported node. Can be either: ‘k’ (keep it) or ‘n’ (do not keep it). The second letter acts on the imported extras that are not present in the original node. Can be either: ‘c’ (create it) or ‘n’ (do not create it). The third letter defines what to do in case of a name collision. Can be either: ‘l’ (leave the old value), ‘u’ (update with a new value), ‘d’ (delete the extra), or ‘a’ (ask what to do if the content is different). :param extras_mode_new: ‘import’ to import extras of new nodes or ‘none’ to ignore them :param comment_mode: Comment import modes (when same UUIDs are found): ‘newest’: Will keep the Comment with the most recent modification time (mtime) ‘overwrite’: Will overwrite existing Comments with the ones from the import file
-
aiida.orm.importexport.merge_extras(old_extras, new_extras, mode)[source]¶ Parameters: - old_extras – a dictionary containing the old extras of an already existing node
- new_extras – a dictionary containing the new extras of an imported node
- extras_mode_existing – 3 letter code that will identify what to do with the extras import. The first letter acts on extras that are present in the original node and not present in the imported node. Can be either k (keep it) or n (do not keep it). The second letter acts on the imported extras that are not present in the original node. Can be either c (create it) or n (do not create it). The third letter says what to do in case of a name collision. Can be l (leave the old value), u (update with a new value), d (delete the extra), a (ask what to do if the content is different).
-
aiida.orm.importexport.schema_to_entity_names(class_string)[source]¶ Mapping from classes path to entity names (used by the SQLA import/export) This could have been written much simpler if it is only for SQLA but there is an attempt the SQLA import/export code to be used for Django too.
-
aiida.orm.importexport.serialize_dict(datadict, remove_fields=[], rename_fields={}, track_conversion=False)[source]¶ Serialize the dict using the serialize_field function to serialize each field.
Parameters: - remove_fields –
a list of strings. If a field with key inside the remove_fields list is found, it is removed from the dict.
This is only used at level-0, no removal is possible at deeper levels.
- rename_fields –
a dictionary in the format
{"oldname": "newname"}.If the “oldname” key is found, it is replaced with the “newname” string in the output dictionary.
This is only used at level-0, no renaming is possible at deeper levels.
- track_conversion – if True, a tuple is returned, where the first element is the serialized dictionary, and the second element is a dictionary with the information on the serialized fields.
- remove_fields –
-
aiida.orm.importexport.serialize_field(data, track_conversion=False)[source]¶ Serialize a single field.
Todo: Generalize such that it the proper function is selected also during import
Module for orm logging abstract classes
-
class
aiida.orm.logs.Log(time, loggername, levelname, dbnode_id, message='', metadata=None, backend=None)[source]¶ Bases:
aiida.orm.entities.EntityAn AiiDA Log entity. Corresponds to a logged message against a particular AiiDA node.
-
class
Collection(backend, entity_class)[source]¶ Bases:
aiida.orm.entities.CollectionThis class represents the collection of logs and can be used to create and retrieve logs.
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.logs'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332335920¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_gorg¶ alias of
Collection
-
static
create_entry_from_record(record)[source]¶ Helper function to create a log entry from a record created as by the python logging library
Parameters: record ( logging.record) – The record created by the logging moduleReturns: An object implementing the log entry interface Return type: aiida.orm.logs.Log
-
delete(log_id)[source]¶ Remove a Log entry from the collection with the given id
Parameters: log_id – id of the log to delete
-
get_logs_for(entity, order_by=None)[source]¶ Get all the log messages for a given entity and optionally sort
Parameters: - entity (
aiida.orm.Entity) – the entity to get logs for - order_by – the optional sort order
Returns: the list of log entries
Return type: list
- entity (
-
-
__init__(time, loggername, levelname, dbnode_id, message='', metadata=None, backend=None)[source]¶ Construct a new log
-
__module__= 'aiida.orm.logs'¶
-
dbnode_id¶ Get the id of the object that created the log entry
Returns: The id of the object that created the log entry Return type: int
-
levelname¶ The name of the log level
Returns: The entry log level name Return type: basestring
-
loggername¶ The name of the logger that created this entry
Returns: The entry loggername Return type: basestring
-
message¶ Get the message corresponding to the entry
Returns: The entry message Return type: basestring
-
metadata¶ Get the metadata corresponding to the entry
Returns: The entry metadata Return type: json.json
-
time¶ Get the time corresponding to the entry
Returns: The entry timestamp Return type: datetime.datetime
-
class
The QueryBuilder: A class that allows you to query the AiiDA database, independent from backend.
Note that the backend implementation is enforced and handled with a composition model!
QueryBuilder() is the frontend class that the user can use. It inherits from object and contains
backend-specific functionality. Backend specific functionality is provided by the implementation classes.
These inherit from aiida.orm.implementation.BackendQueryBuilder(),
an interface classes which enforces the implementation of its defined methods.
An instance of one of the implementation classes becomes a member of the QueryBuilder() instance
when instantiated by the user.
-
class
aiida.orm.querybuilder.QueryBuilder(backend=None, **kwargs)[source]¶ Bases:
objectThe class to query the AiiDA database.
Usage:
from aiida.orm.querybuilder import QueryBuilder qb = QueryBuilder() # Querying nodes: qb.append(Node) # retrieving the results: results = qb.all()
-
_EDGE_TAG_DELIM= '--'¶
-
_VALID_PROJECTION_KEYS= ('func', 'cast')¶
-
__dict__= dict_proxy({'_add_to_projections': <function _add_to_projections>, 'all': <function all>, '__str__': <function __str__>, '_EDGE_TAG_DELIM': '--', 'one': <function one>, '_join_group_members': <function _join_group_members>, '_join_node_comment': <function _join_node_comment>, '__dict__': <attribute '__dict__' of 'QueryBuilder' objects>, '_join_log_node': <function _join_log_node>, '_get_function_map': <function _get_function_map>, '__weakref__': <attribute '__weakref__' of 'QueryBuilder' objects>, 'children': <function children>, '_join_inputs': <function _join_inputs>, 'order_by': <function order_by>, '_get_ormclass': <function _get_ormclass>, 'distinct': <function distinct>, 'set_debug': <function set_debug>, '_join_to_computer_used': <function _join_to_computer_used>, 'dict': <function dict>, '_join_node_log': <function _join_node_log>, 'parents': <function parents>, '__doc__': '\n The class to query the AiiDA database.\n\n Usage::\n\n from aiida.orm.querybuilder import QueryBuilder\n qb = QueryBuilder()\n # Querying nodes:\n qb.append(Node)\n # retrieving the results:\n results = qb.all()\n\n ', 'iterdict': <function iterdict>, '_build_order': <function _build_order>, '_VALID_PROJECTION_KEYS': ('func', 'cast'), '_get_json_compatible': <function _get_json_compatible>, 'outputs': <function outputs>, '_join_descendants_recursive': <function _join_descendants_recursive>, 'count': <function count>, '_join_computer': <function _join_computer>, 'get_json_compatible_queryhelp': <function get_json_compatible_queryhelp>, '_get_unique_tag': <function _get_unique_tag>, 'get_alias': <function get_alias>, 'limit': <function limit>, '_check_dbentities': <staticmethod object>, '_deprecate': <function _deprecate>, '__module__': 'aiida.orm.querybuilder', '_join_outputs': <function _join_outputs>, '_join_ancestors_recursive': <function _join_ancestors_recursive>, '_join_comment_user': <function _join_comment_user>, 'get_query': <function get_query>, 'get_aliases': <function get_aliases>, '_build_filters': <function _build_filters>, 'add_filter': <function add_filter>, 'append': <function append>, 'get_used_tags': <function get_used_tags>, '_join_user_comment': <function _join_user_comment>, '_build_projections': <function _build_projections>, '__init__': <function __init__>, 'iterall': <function iterall>, '_add_process_type_filter': <function _add_process_type_filter>, '_join_comment_node': <function _join_comment_node>, 'inputs': <function inputs>, '_join_group_user': <function _join_group_user>, 'add_projection': <function add_projection>, '_process_filters': <function _process_filters>, '_join_user_group': <function _join_user_group>, 'get_aiida_entity_res': <staticmethod object>, 'inject_query': <function inject_query>, 'offset': <function offset>, '_get_projectable_entity': <function _get_projectable_entity>, '_join_creator_of': <function _join_creator_of>, 'except_if_input_to': <function except_if_input_to>, '_build': <function _build>, '_join_created_by': <function _join_created_by>, '_get_tag_from_specification': <function _get_tag_from_specification>, '_get_connecting_node': <function _get_connecting_node>, '_join_groups': <function _join_groups>, '_add_type_filter': <function _add_type_filter>, 'first': <function first>})¶
-
__init__(backend=None, **kwargs)[source]¶ Instantiates a QueryBuilder instance.
Which backend is used decided here based on backend-settings (taken from the user profile). This cannot be overriden so far by the user.
Parameters: - debug (bool) – Turn on debug mode. This feature prints information on the screen about the stages of the QueryBuilder. Does not affect results.
- path (list) – A list of the vertices to traverse. Leave empty if you plan on using the method
QueryBuilder.append(). - filters – The filters to apply. You can specify the filters here, when appending to the query
using
QueryBuilder.append()or even later usingQueryBuilder.add_filter(). Check latter gives API-details. - project – The projections to apply. You can specify the projections here, when appending to the query
using
QueryBuilder.append()or even later usingQueryBuilder.add_projection(). Latter gives you API-details. - limit (int) – Limit the number of rows to this number. Check
QueryBuilder.limit()for more information. - offset (int) – Set an offset for the results returned. Details in
QueryBuilder.offset(). - order_by – How to order the results. As the 2 above, can be set also at later stage,
check
QueryBuilder.order_by()for more information.
-
__module__= 'aiida.orm.querybuilder'¶
-
__str__()[source]¶ When somebody hits: print(QueryBuilder) or print(str(QueryBuilder)) I want to print the SQL-query. Because it looks cool…
-
__weakref__¶ list of weak references to the object (if defined)
-
_add_process_type_filter(tagspec, classifiers, subclassing)[source]¶ Add a filter based on process type.
Parameters: - tagspec – The tag, which has to exist already as a key in self._filters
- classifiers – a dictionary with classifiers
- subclassing – if True, allow for subclasses of the process type
Note: This function handles the case when process_type_string is None.
-
_add_to_projections(alias, projectable_entity_name, cast=None, func=None)[source]¶ Parameters: - alias (
sqlalchemy.orm.util.AliasedClass) – A instance of sqlalchemy.orm.util.AliasedClass, alias for an ormclass - projectable_entity_name – User specification of what to project. Appends to query’s entities what the user wants to project (have returned by the query)
- alias (
-
_add_type_filter(tagspec, classifiers, subclassing)[source]¶ Add a filter based on type.
Parameters: - tagspec – The tag, which has to exist already as a key in self._filters
- classifiers – a dictionary with classifiers
- subclassing – if True, allow for subclasses of the ormclass
-
_build_filters(alias, filter_spec)[source]¶ Recurse through the filter specification and apply filter operations.
Parameters: - alias – The alias of the ORM class the filter will be applied on
- filter_spec – the specification as given by the queryhelp
Returns: an instance of sqlalchemy.sql.elements.BinaryExpression.
-
static
_check_dbentities(entities_cls_joined, entities_cls_to_join, relationship)[source]¶ Parameters: - entities_cls_joined – A tuple of the aliased class passed as joined_entity and the ormclass that was expected
- entities_cls_joined – A tuple of the aliased class passed as entity_to_join and the ormclass that was expected
- relationship (str) – The relationship between the two entities to make the Exception comprehensible
-
_deprecate(function, deprecated_name, preferred_name, version='1.0.0a5')[source]¶ Wrapper to return a decorated functon which will print a deprecation warning when it is called.
Specifically for when an old relationship type is used. Note that it is the way of calling the function which is deprecated, not the function itself
Parameters: - function – a deprecated function to call
- deprecated_name – the name which is deprecated
- preferred_name – the new name which is preferred
- version – aiida version for which this takes effect.
-
_get_connecting_node(index, joining_keyword=None, joining_value=None, **kwargs)[source]¶ Parameters: - querydict – A dictionary specifying how the current node is linked to other nodes.
- index – Index of this node within the path specification
- joining_keyword – the relation on which to join
- joining_value – the tag of the nodes to be joined
-
_get_function_map()[source]¶ Map relationship type keywords to functions The new mapping (since 1.0.0a5) is a two level dictionary. The first level defines the entity which has been passed to the qb.append functon, and the second defines the relationship with respect to a given tag.
-
_get_json_compatible(inp)[source]¶ Parameters: inp – The input value that will be converted. Recurses into each value if inp is an iterable.
-
_get_ormclass(cls, ormclass_type_string)[source]¶ Get ORM classifiers from either class(es) or ormclass_type_string(s).
Parameters: - cls – a class or tuple/set/list of classes that are either AiiDA ORM classes or backend ORM classes.
- ormclass_type_string – type string for ORM class
Returns: the ORM class as well as a dictionary with additional classifier strings
Handles the case of lists as well.
-
_get_tag_from_specification(specification)[source]¶ Parameters: specification – If that is a string, I assume the user has deliberately specified it with tag=specification. In that case, I simply check that it’s not a duplicate. If it is a class, I check if it’s in the _cls_to_tag_map!
-
_get_unique_tag(classifiers)[source]¶ Using the function get_tag_from_type, I get a tag. I increment an index that is appended to that tag until I have an unused tag. This function is called in
QueryBuilder.append()when autotag is set to True.Parameters: classifiers (dict) – Classifiers, containing the string that defines the type of the AiiDA ORM class. For subclasses of Node, this is the Node._plugin_type_string, for other they are as defined as returned by
QueryBuilder._get_ormclass().Can also be a list of dictionaries, when multiple classes are passed to QueryBuilder.append
Returns: A tag as a string (it is a single string also when passing multiple classes).
-
_join_ancestors_recursive(joined_entity, entity_to_join, isouterjoin, filter_dict, expand_path=False)[source]¶ joining ancestors using the recursive functionality :TODO: Move the filters to be done inside the recursive query (for example on depth) :TODO: Pass an option to also show the path, if this is wanted.
-
_join_comment_node(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased comment
- entity_to_join – aliased node
-
_join_comment_user(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased comment
- entity_to_join – aliased user
-
_join_computer(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An entity that can use a computer (eg a node)
- entity_to_join – aliased dbcomputer entity
-
_join_created_by(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – the aliased user you want to join to
- entity_to_join – the (aliased) node or group in the DB to join with
-
_join_creator_of(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – the aliased node
- entity_to_join – the aliased user to join to that node
-
_join_descendants_recursive(joined_entity, entity_to_join, isouterjoin, filter_dict, expand_path=False)[source]¶ joining descendants using the recursive functionality :TODO: Move the filters to be done inside the recursive query (for example on depth) :TODO: Pass an option to also show the path, if this is wanted.
-
_join_group_members(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) ORMclass that is a group in the database
- entity_to_join – The (aliased) ORMClass that is a node and member of the group
joined_entity and entity_to_join are joined via the table_groups_nodes table. from joined_entity as group to enitity_to_join as node. (enitity_to_join is with_group joined_entity)
-
_join_group_user(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased dbgroup
- entity_to_join – aliased dbuser
-
_join_groups(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) node in the database
- entity_to_join – The (aliased) Group
joined_entity and entity_to_join are joined via the table_groups_nodes table. from joined_entity as node to enitity_to_join as group. (enitity_to_join is a group with_node joined_entity)
-
_join_inputs(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) ORMclass that is an output
- entity_to_join – The (aliased) ORMClass that is an input.
joined_entity and entity_to_join are joined with a link from joined_entity as output to enitity_to_join as input (enitity_to_join is with_outgoing joined_entity)
-
_join_log_node(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased log
- entity_to_join – aliased node
-
_join_node_comment(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased node
- entity_to_join – aliased comment
-
_join_node_log(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased node
- entity_to_join – aliased log
-
_join_outputs(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – The (aliased) ORMclass that is an input
- entity_to_join – The (aliased) ORMClass that is an output.
joined_entity and entity_to_join are joined with a link from joined_entity as input to enitity_to_join as output (enitity_to_join is with_incoming joined_entity)
-
_join_to_computer_used(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – the (aliased) computer entity
- entity_to_join – the (aliased) node entity
-
_join_user_comment(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased user
- entity_to_join – aliased comment
-
_join_user_group(joined_entity, entity_to_join, isouterjoin)[source]¶ Parameters: - joined_entity – An aliased user
- entity_to_join – aliased group
-
add_filter(tagspec, filter_spec)[source]¶ Adding a filter to my filters.
Parameters: - tagspec – The tag, which has to exist already as a key in self._filters
- filter_spec – The specifications for the filter, has to be a dictionary
Usage:
qb = QueryBuilder() # Instantiating the QueryBuilder instance qb.append(Node, tag='node') # Appending a Node #let's put some filters: qb.add_filter('node',{'id':{'>':12}}) # 2 filters together: qb.add_filter('node',{'label':'foo', 'uuid':{'like':'ab%'}}) # Now I am overriding the first filter I set: qb.add_filter('node',{'id':13})
-
add_projection(tag_spec, projection_spec)[source]¶ Adds a projection
Parameters: - tag_spec – A valid specification for a tag
- projection_spec – The specification for the projection. A projection is a list of dictionaries, with each dictionary containing key-value pairs where the key is database entity (e.g. a column / an attribute) and the value is (optional) additional information on how to process this database entity.
If the given projection_spec is not a list, it will be expanded to a list. If the listitems are not dictionaries, but strings (No additional processing of the projected results desired), they will be expanded to dictionaries.
Usage:
qb = QueryBuilder() qb.append(StructureData, tag='struc') # Will project the uuid and the kinds qb.add_projection('struc', ['uuid', 'attributes.kinds'])
The above example will project the uuid and the kinds-attribute of all matching structures. There are 2 (so far) special keys.
The single star * will project the ORM-instance:
qb = QueryBuilder() qb.append(StructureData, tag='struc') # Will project the ORM instance qb.add_projection('struc', '*') print type(qb.first()[0]) # >>> aiida.orm.nodes.data.structure.StructureData
The double start ** projects all possible projections of this entity:
QueryBuilder().append(StructureData,tag=’s’, project=’**’).limit(1).dict()[0][‘s’].keys()
# >>> u’user_id, description, ctime, label, extras, mtime, id, attributes, dbcomputer_id, nodeversion, type, public, uuid’
Be aware that the result of ** depends on the backend implementation.
-
all(batch_size=None)[source]¶ Executes the full query with the order of the rows as returned by the backend. the order inside each row is given by the order of the vertices in the path and the order of the projections for each vertice in the path.
Parameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Leave the default (None) if speed is not critical or if you don’t know what you’re doing! Returns: a list of lists of all projected entities.
-
append(cls=None, entity_type=None, tag=None, filters=None, project=None, subclassing=True, edge_tag=None, edge_filters=None, edge_project=None, outerjoin=False, **kwargs)[source]¶ Any iterative procedure to build the path for a graph query needs to invoke this method to append to the path.
Parameters: - cls –
The Aiida-class (or backend-class) defining the appended vertice. Also supports a tuple/list of classes. This results in an all instances of this class being accepted in a query. However the classes have to have the same orm-class for the joining to work. I.e. both have to subclasses of Node. Valid is:
cls=(StructureData, Dict)
This is invalid:
cls=(Group, Node) - entity_type – The node type of the class, if cls is not given. Also here, a tuple or list is accepted.
- autotag (bool) – Whether to find automatically a unique tag. If this is set to True (default False),
- tag (str) – A unique tag. If none is given, I will create a unique tag myself.
- filters – Filters to apply for this vertex.
See
add_filter(), the method invoked in the background, or usage examples for details. - project – Projections to apply. See usage examples for details.
More information also in
add_projection(). - subclassing (bool) – Whether to include subclasses of the given class (default True). E.g. Specifying a ProcessNode as cls will include CalcJobNode, WorkChainNode, CalcFunctionNode, etc..
- outerjoin (bool) – If True, (default is False), will do a left outerjoin instead of an inner join
- edge_tag (str) – The tag that the edge will get. If nothing is specified (and there is a meaningful edge) the default is tag1–tag2 with tag1 being the entity joining from and tag2 being the entity joining to (this entity).
- edge_filters (str) – The filters to apply on the edge. Also here, details in
add_filter(). - edge_project (str) – The project from the edges. API-details in
add_projection().
A small usage example how this can be invoked:
qb = QueryBuilder() # Instantiating empty querybuilder instance qb.append(cls=StructureData) # First item is StructureData node # The # next node in the path is a PwCalculation, with # the structure joined as an input qb.append( cls=PwCalculation, with_incoming=StructureData )
Returns: self Return type: aiida.orm.QueryBuilder- cls –
-
count()[source]¶ Counts the number of rows returned by the backend.
Returns: the number of rows as an integer
-
dict(batch_size=None)[source]¶ Executes the full query with the order of the rows as returned by the backend. the order inside each row is given by the order of the vertices in the path and the order of the projections for each vertice in the path.
Parameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Leave the default (None) if speed is not critical or if you don’t know what you’re doing! Returns: a list of dictionaries of all projected entities. Each dictionary consists of key value pairs, where the key is the tag of the vertice and the value a dictionary of key-value pairs where key is the entity description (a column name or attribute path) and the value the value in the DB. Usage:
qb = QueryBuilder() qb.append( StructureData, tag='structure', filters={'uuid':{'==':myuuid}}, ) qb.append( Node, with_ancestors='structure', project=['entity_type', 'id'], # returns entity_type (string) and id (string) tag='descendant' ) # Return the dictionaries: print "qb.iterdict()" for d in qb.iterdict(): print '>>>', d
results in the following output:
qb.iterdict() >>> {'descendant': { 'entity_type': u'calculation.job.quantumespresso.pw.PwCalculation.', 'id': 7716} } >>> {'descendant': { 'entity_type': u'data.remote.RemoteData.', 'id': 8510} }
-
distinct()[source]¶ Asks for distinct rows, which is the same as asking the backend to remove duplicates. Does not execute the query!
If you want a distinct query:
qb = QueryBuilder() # append stuff! qb.append(...) qb.append(...) ... qb.distinct().all() #or qb.distinct().dict()
Returns: self
-
except_if_input_to(calc_class)[source]¶ Makes counterquery based on the own path, only selecting entries that have been input to calc_class
Parameters: calc_class – The calculation class to check against Returns: self
-
first()[source]¶ Executes query asking for one instance. Use as follows:
qb = QueryBuilder(**queryhelp) qb.first()
Returns: One row of results as a list
-
get_alias(tag)[source]¶ In order to continue a query by the user, this utility function returns the aliased ormclasses.
Parameters: tag – The tag for a vertice in the path Returns: the alias given for that vertice
-
get_json_compatible_queryhelp()[source]¶ Makes the queryhelp a json-compatible dictionary.
In this way,the queryhelp can be stored in the database or a json-object, retrieved or shared and used later. See this usage:
qb = QueryBuilder(limit=3).append(StructureData, project='id').order_by({StructureData:'id'}) queryhelp = qb.get_json_compatible_queryhelp() # Now I could save this dictionary somewhere and use it later: qb2=QueryBuilder(**queryhelp) # This is True if no change has been made to the database. # Note that such a comparison can only be True if the order of results is enforced qb.all()==qb2.all()
Returns: the json-compatible queryhelp
-
get_query()[source]¶ Instantiates and manipulates a sqlalchemy.orm.Query instance if this is needed. First, I check if the query instance is still valid by hashing the queryhelp. In this way, if a user asks for the same query twice, I am not recreating an instance.
Returns: an instance of sqlalchemy.orm.Query that is specific to the backend used.
Returns a list of all the vertices that are being used. Some parameter allow to select only subsets. :param bool vertices: Defaults to True. If True, adds the tags of vertices to the returned list :param bool edges: Defaults to True. If True, adds the tags of edges to the returnend list.
Returns: A list of all tags, including (if there is) also the tag give for the edges
-
inject_query(query)[source]¶ Manipulate the query an inject it back. This can be done to add custom filters using SQLA. :param query: A sqlalchemy.orm.Query instance
-
iterall(batch_size=100)[source]¶ Same as
all(), but returns a generator. Be aware that this is only safe if no commit will take place during this transaction. You might also want to read the SQLAlchemy documentation on http://docs.sqlalchemy.org/en/latest/orm/query.html#sqlalchemy.orm.query.Query.yield_perParameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Returns: a generator of lists
-
iterdict(batch_size=100)[source]¶ Same as
dict(), but returns a generator. Be aware that this is only safe if no commit will take place during this transaction. You might also want to read the SQLAlchemy documentation on http://docs.sqlalchemy.org/en/latest/orm/query.html#sqlalchemy.orm.query.Query.yield_perParameters: batch_size (int) – The size of the batches to ask the backend to batch results in subcollections. You can optimize the speed of the query by tuning this parameter. Returns: a generator of dictionaries
-
limit(limit)[source]¶ Set the limit (nr of rows to return)
Parameters: limit (int) – integers of number of rows of rows to return
-
offset(offset)[source]¶ Set the offset. If offset is set, that many rows are skipped before returning. offset = 0 is the same as omitting setting the offset. If both offset and limit appear, then offset rows are skipped before starting to count the limit rows that are returned.
Parameters: offset (int) – integers of nr of rows to skip
-
one()[source]¶ Executes the query asking for exactly one results. Will raise an exception if this is not the case :raises: MultipleObjectsError if more then one row can be returned :raises: NotExistent if no result was found
-
order_by(order_by)[source]¶ Set the entity to order by
Parameters: order_by – This is a list of items, where each item is a dictionary specifies what to sort for an entity In each dictionary in that list, keys represent valid tags of entities (tables), and values are list of columns.
Usage:
#Sorting by id (ascending): qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':['id']}) # or #Sorting by id (ascending): qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':[{'id':{'order':'asc'}}]}) # for descending order: qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':[{'id':{'order':'desc'}}]}) # or (shorter) qb = QueryBuilder() qb.append(Node, tag='node') qb.order_by({'node':[{'id':'desc'}]})
-
Module for the ORM user class.
-
class
aiida.orm.users.User(email, first_name='', last_name='', institution='', backend=None)[source]¶ Bases:
aiida.orm.entities.EntityAiiDA User
-
class
Collection(*args, **kwargs)[source]¶ Bases:
aiida.orm.entities.CollectionThe collection of users stored in a backend
-
UNDEFINED= 'UNDEFINED'¶
-
__abstractmethods__= frozenset([])¶
-
__args__= None¶
-
__extra__= None¶
-
__module__= 'aiida.orm.users'¶
-
__next_in_mro__¶ alias of
__builtin__.object
-
__orig_bases__= (aiida.orm.entities.Collection,)¶
-
__origin__= None¶
-
__parameters__= ()¶
-
__tree_hash__= 5926332174120¶
-
_abc_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache= <_weakrefset.WeakSet object>¶
-
_abc_generic_negative_cache_version= 39¶
-
_abc_registry= <_weakrefset.WeakSet object>¶
-
_default_user= None¶
-
_gorg¶ alias of
Collection
-
get_default()[source]¶ Get the current default user
Returns: The default user Return type: aiida.orm.User
-
get_or_create(**kwargs)[source]¶ Get the existing user with a given email address or create an unstored one
Parameters: kwargs – The properties of the user to get or create Returns: The corresponding user object Return type: aiida.orm.UserRaises: aiida.common.exceptions.MultipleObjectsError,aiida.common.exceptions.NotExistent
-
-
REQUIRED_FIELDS= ['first_name', 'last_name', 'institution']¶
-
__init__(email, first_name='', last_name='', institution='', backend=None)[source]¶ Parameters: backend_entity ( aiida.orm.implementation.BackendEntity) – the backend model supporting this entity
-
__module__= 'aiida.orm.users'¶
-
date_joined¶
-
email¶
-
first_name¶
-
static
get_schema()[source]¶ Every node property contains:
- display_name: display name of the property
- help text: short help text of the property
- is_foreign_key: is the property foreign key to other type of the node
- type: type of the property. e.g. str, dict, int
Returns: schema of the user
-
get_short_name()[source]¶ Return the user short name (typically, this returns the email)
Returns: The short name
-
institution¶
-
is_active¶
-
last_login¶
-
last_name¶
-
static
normalize_email(email)[source]¶ Normalize the address by lowercasing the domain part of the email address.
Taken from Django.
-
password¶
-
class